Réponse mise à jour en 2020 :
Selon la réponse de @Owen, ORC a grandi et mûri en tant que son propre projet Apache. Une liste complète des adopteurs ORC montre à quel point il est désormais pris en charge dans de nombreuses variétés de technologies Big Data.
Merci à @Owen et à l'équipe du projet ORC Apache, le site du projet ORC dispose d'une documentation entièrement mise à jour sur l'utilisation de l'outil autonome Java ou C++ sur un fichier ORC stocké sur un système de fichiers local Linux. Qui a repris le flambeau de la page wiki originale Hive + ORC Apache.
Réponse originale datée :May 30 '14 at 16:27
L'utilitaire de vidage de fichier ORC est fourni avec hive (0.11 ou supérieur) :
hive --orcfiledump <hdfs-location-of-orc-file>Lien source
Il est également capable de voir le contenu d'un fichier ORC par application de bureau fonctionnant sous Linux.
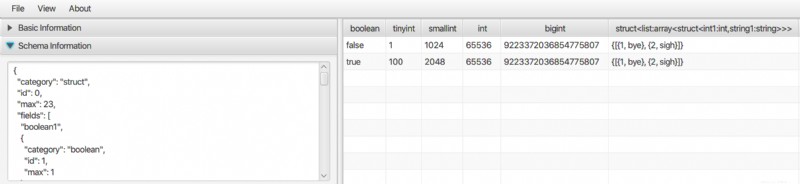
Il existe une application de bureau pour afficher Parquet ainsi que d'autres données au format binaire comme ORC et AVRO. C'est une application Java pure qui peut être exécutée sous Linux, Mac et Windows. Veuillez vérifier Bigdata File Viewer pour plus de détails.
Il prend en charge les types de données complexes tels que tableau, carte, structure, etc.
Il existe désormais également un exécutable natif pour Linux et MacOS qui imprime le contenu du fichier orc au format JSON. Voir le projet ORC (http://orc.apache.org/) et compiler les outils C++.
% orc-contents examples/TestOrcFile.test1.orc
Il existe également un outil de métadonnées natif :
% orc-metadata ../examples/TestOrcFile.test1.orc
Le projet ORC dispose également d'un uber jar autonome qui peut faire la même chose à partir de Java.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc