Dans ce guide, nous décrirons quel encodage de caractères et couvrirons quelques exemples de conversion de fichiers d'un encodage de caractères à un autre à l'aide d'un outil de ligne de commande. Puis enfin, nous verrons comment convertir plusieurs fichiers à partir de n'importe quel jeu de caractères (charset ) en UTF-8 encodage sous Linux.
Comme vous l'avez probablement déjà à l'esprit, un ordinateur ne comprend ni ne stocke les lettres, les chiffres ou tout ce que nous, en tant qu'humains, pouvons percevoir, à l'exception des bits. Un bit n'a que deux valeurs possibles, soit un 0 ou 1 , true ou false , yes ou no . Toutes les autres choses telles que les lettres, les chiffres, les images doivent être représentées en bits pour qu'un ordinateur puisse les traiter.
En termes simples, l'encodage des caractères est un moyen d'informer un ordinateur sur la manière d'interpréter les zéros et les uns bruts en caractères réels, où un caractère est représenté par un ensemble de nombres. Lorsque nous tapons du texte dans un fichier, les mots et les phrases que nous formons sont composés de différents caractères, et les caractères sont organisés en un jeu de caractères .
Il existe différents schémas de codage tels que ASCII , ANSI , Unicode entre autres. Ci-dessous un exemple de ASCII encodage.
Character bits A 01000001 B 01000010
Sous Linux, l'iconv L'outil de ligne de commande est utilisé pour convertir du texte d'une forme d'encodage à une autre.
Vous pouvez vérifier l'encodage d'un fichier en utilisant le fichier commande, en utilisant le -i ou --mime flag qui active l'impression d'une chaîne de type mime comme dans les exemples ci-dessous :
$ file -i Car.java $ file -i CarDriver.java


La syntaxe pour utiliser iconv est le suivant :
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Où -f ou --from-code signifie encodage d'entrée et -t ou --to-encoding spécifie l'encodage de sortie.
Pour répertorier tous les jeux de caractères codés connus, exécutez la commande ci-dessous :
$ iconv -l
Convertir les fichiers du codage UTF-8 au codage ASCII
Ensuite, nous apprendrons comment convertir d'un schéma d'encodage à un autre. La commande ci-dessous convertit à partir de ISO-8859-1 à UTF-8 codage.
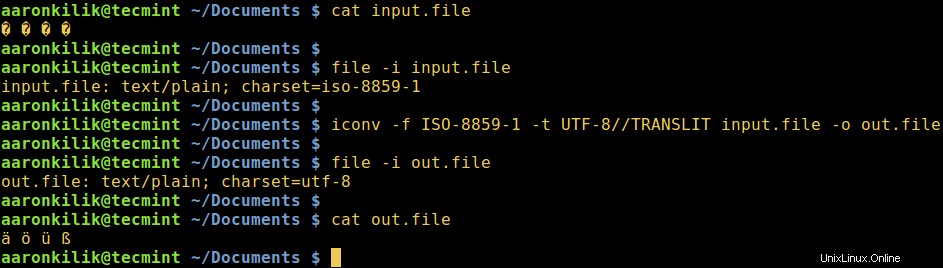
Prenons un fichier nommé input.file qui contient les caractères :
� � � �
Commençons par vérifier l'encodage des caractères dans le fichier, puis visualisons le contenu du fichier. De près, nous pouvons convertir tous les caractères en ASCII encodage.
Après avoir exécuté l'iconv commande, nous vérifions ensuite le contenu du fichier de sortie et le nouvel encodage des caractères comme ci-dessous.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Remarque :Dans le cas où la chaîne //IGNORE est ajouté à l'encodage, des caractères qui ne peuvent pas être convertis et une erreur s'affiche après la conversion.
Encore une fois, supposons que la chaîne //TRANSLIT est ajouté à to-encoding comme dans l'exemple ci-dessus (ASCII//TRANSLIT ), les caractères en cours de conversion sont translittérés si nécessaire et si possible. Ce qui implique que dans le cas où un caractère ne peut pas être représenté dans le jeu de caractères cible, il peut être approximé par un ou plusieurs caractères d'apparence similaire.
Par conséquent, tout caractère qui ne peut pas être translittéré et qui n'est pas dans le jeu de caractères cible est remplacé par un point d'interrogation (?) dans la sortie.
Convertir plusieurs fichiers en codage UTF-8
Pour en revenir à notre sujet principal, pour convertir plusieurs ou tous les fichiers d'un répertoire en codage UTF-8, vous pouvez écrire un petit script shell appelé encoding.sh comme suit :
#!/bin/bash
#enter input encoding here
FROM_ENCODING="value_here"
#output encoding(UTF-8)
TO_ENCODING="UTF-8"
#convert
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
#loop to convert multiple files
for file in *.txt; do
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
done
exit 0
Enregistrez le fichier, puis rendez le script exécutable. Exécutez-le depuis le répertoire où se trouvent vos fichiers (*.txt ) sont situés.
$ chmod +x encoding.sh $ ./encoding.sh
Important :Vous pouvez également utiliser ce script pour la conversion générale de plusieurs fichiers d'un encodage donné à un autre, jouez simplement avec les valeurs du FROM_ENCODING et TO_ENCODING variable, sans oublier le nom du fichier de sortie "${file%.txt}.utf8.converted" .
Pour plus d'informations, consultez l'iconv page de manuel.
$ man iconv
Pour résumer ce guide, comprendre l'encodage et la conversion d'un schéma d'encodage de caractères à un autre est une connaissance nécessaire pour chaque utilisateur d'ordinateur, plus encore pour les programmeurs lorsqu'il s'agit de traiter du texte.
Enfin, vous pouvez nous contacter en utilisant la section des commentaires ci-dessous pour toute question ou commentaire.