La table de processus est une structure de données du noyau qui décrit l'état d'un processus (ainsi que la zone U du processus). Il contient des champs qui doivent toujours être disponibles pour le noyau.
Il contient les champs suivants :
- champ d'état (qui identifie l'état du processus)
- champs permettant au noyau de localiser le processus et sa zone u en mémoire
- UID pour déterminer divers privilèges de processus
- PID pour spécifier les relations n/b processus (par exemple, fork)
- descripteur d'événement (lorsque le processus est en état de veille)
- paramètres de planification pour déterminer l'ordre dans lequel le processus passe aux états "noyau en cours d'exécution" et "utilisateur en cours d'exécution"
- champ de signal pour les signaux envoyés au processus mais pas encore traités
- timers qui donnent le temps d'exécution du processus en mode noyau et en mode utilisateur
- champ qui donne la taille du processus (afin que le noyau sache combien d'espace allouer au processus).
En bref, la table des processus donne des informations sur les processus au noyau.
La table de processus sous Linux (comme dans presque tous les autres systèmes d'exploitation) est simplement une structure de données dans la RAM d'un ordinateur. Il contient des informations sur les processus actuellement gérés par le système d'exploitation.
Ces informations incluent des informations générales sur chaque processus
- identifiant de processus
- propriétaire du processus
- priorité du processus
- variables d'environnement pour chaque processus
- le processus parent
- pointeurs vers le code machine exécutable d'un processus.
Une information très importante dans la table de processus est l'état dans lequel se trouve actuellement chaque processus. Cette information est essentielle pour le système d'exploitation, car elle permet ce qu'on appelle le multitraitement, c'est-à-dire la possibilité d'exécuter virtuellement plusieurs processus sur une seule unité de traitement (CPU).
Les informations indiquant si un processus est actuellement ACTIF, EN VEILLE, EN COURS D'EXÉCUTION, etc. sont utilisées par le système d'exploitation afin de gérer l'exécution des processus.
De plus, il existe des informations statistiques telles que le moment où le processus s'est exécuté pour la dernière fois afin de permettre au planificateur du système d'exploitation de décider quel processus doit être exécuté ensuite.
Donc, en résumé, la table de processus est l'élément organisationnel central permettant au système d'exploitation de gérer tous les processus démarrés.
Une courte introduction peut être trouvée dans ce fil :
https://web.archive.org/web/20190817081256/http://www.linuxforums.org/forum/kernel/42062-use-process-table.html
Et wikipedia a aussi de belles informations sur les processus :
http://en.wikipedia.org/wiki/Process_management_(informatique)#Process_description_and_control
http://en.wikipedia.org/wiki/Process_table
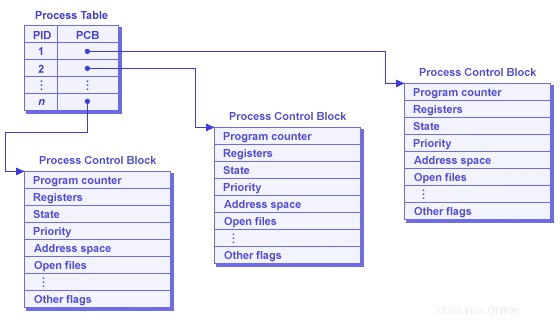
Chaque processus est représenté dans le système d'exploitation par un bloc de contrôle de processus - également appelé bloc de contrôle des tâches - qui contient les éléments suivants
Process management
Registers
Program counter
Program status word
Stack pointer
Process state
Priority
Scheduling parameters Process ID
Parent process
Process group
Signals
Time when process started CPU time used
Children’s CPU time
Time of next alarm
Memory management
Pointer to text segment info
Pointer to data segment info
Pointer to stack segment info
File management
Root directory Working directory File descriptors User ID
Group ID
Pour en savoir plus, https://www.technologyuk.net/computing/computer-software/operating-systems/