Le travail principal d'un robot Web consiste à explorer ou à analyser des sites Web et des pages à la recherche d'informations. ils travaillent sans relâche pour collecter des données pour les moteurs de recherche et d'autres applications. Pour certains, il y a de bonnes raisons de garder les pages éloignées des moteurs de recherche. Que vous souhaitiez affiner l'accès à votre site ou que vous souhaitiez travailler sur un site de développement sans apparaître dans les résultats Google, une fois mis en œuvre, le fichier robots.txt permet aux robots d'exploration et aux robots de savoir quelles informations ils peuvent collecter.
Qu'est-ce qu'un fichier Robots.txt ?
Un robots.txt est un fichier de site Web en texte brut à la racine de votre site qui respecte la norme d'exclusion des robots. Par exemple, www.votredomaine.com aurait un fichier robots.txt sur www.votredomaine.com/robots.txt. Le fichier se compose d'une ou plusieurs règles qui autorisent ou bloquent l'accès aux robots d'exploration, les contraignant à un chemin de fichier spécifié sur le site Web. Par défaut, tous les fichiers sont entièrement autorisés à explorer, sauf indication contraire.
Le fichier robots.txt est l'un des premiers aspects analysés par les crawlers. Il est important de noter que votre site ne peut avoir qu'un seul fichier robots.txt. Le fichier est implémenté sur une ou plusieurs pages ou sur un site entier pour décourager les moteurs de recherche d'afficher des détails sur votre site Web.
Cet article fournit cinq étapes pour créer un fichier robots.txt et la syntaxe nécessaire pour tenir les bots à distance.
Comment configurer un fichier Robots.txt
1. Créer un fichier Robots.txt
Vous devez avoir accès à la racine de votre domaine. Votre fournisseur d'hébergement Web peut vous aider à déterminer si vous disposez ou non de l'accès approprié.
La partie la plus importante du fichier est sa création et son emplacement. Utilisez n'importe quel éditeur de texte pour créer un fichier robots.txt et peut être trouvé sur :
- La racine de votre domaine :www.votredomaine.com/robots.txt.
- Vos sous-domaines :page.votredomaine.com/robots.txt.
- Ports non standard :www.votredomaine.com:881/robots.txt.
Enfin, vous devrez vous assurer que votre fichier robots.txt est un fichier texte encodé en UTF-8. Google et d'autres moteurs de recherche et robots d'exploration populaires peuvent ignorer les caractères en dehors de la plage UTF-8, ce qui peut rendre vos règles robots.txt invalides.
2. Définissez votre agent utilisateur Robots.txt
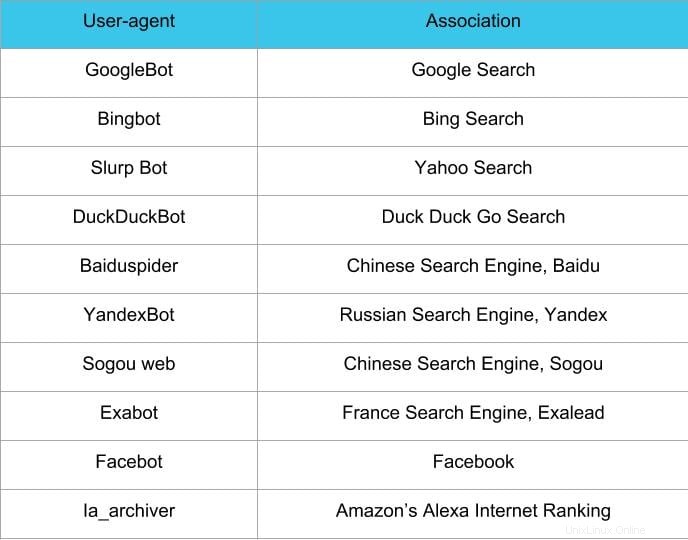
L'étape suivante dans la création de fichiers robots.txt consiste à définir le user-agent . L'agent utilisateur concerne les robots d'exploration Web ou les moteurs de recherche que vous souhaitez autoriser ou bloquer. Plusieurs entités peuvent être le user-agent . Nous avons répertorié ci-dessous quelques robots d'exploration, ainsi que leurs associations.
Il existe trois manières différentes d'établir un agent utilisateur dans votre fichier robots.txt.
Création d'un agent utilisateur
La syntaxe que vous utilisez pour définir l'agent utilisateur est User-agent :NameOfBot . Ci-dessous, DuckDuckBot est le seul agent utilisateur établie.
# Example of how to set user-agent
User-agent: DuckDuckBotCréation de plusieurs agents utilisateurs
Si nous devons en ajouter plusieurs, suivez le même processus que pour l'agent utilisateur DuckDuckBot. sur une ligne suivante, en saisissant le nom de l'user-agent supplémentaire . Dans cet exemple, nous avons utilisé Facebot.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotDéfinition de tous les robots d'exploration en tant qu'agent utilisateur
Pour bloquer tous les bots ou robots d'exploration, remplacez le nom du bot par un astérisque (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Définir des règles pour votre fichier Robots.txt
Un fichier robots.txt est lu par groupes. Un groupe précisera qui est le user-agent est et ont une règle ou une directive pour indiquer quels fichiers ou répertoires l'agent utilisateur peut ou ne peut pas accéder.
Voici les directives utilisées :
- Interdire :La directive faisant référence à une page ou un répertoire relatif à votre domaine racine dont vous ne voulez pas le nom user-agent ramper. Il commencera par une barre oblique (/) suivie de l'URL complète de la page. Vous le terminerez par une barre oblique uniquement s'il fait référence à un répertoire et non à une page entière. Vous pouvez utiliser un ou plusieurs disallow paramètres par règle.
- Autoriser :La directive fait référence à une page ou un répertoire relatif à votre domaine racine que vous souhaitez nommer user-agent ramper. Par exemple, vous utiliseriez le allow directive pour remplacer le disallow règle. Il commencera également par une barre oblique (/) suivie de l'URL complète de la page. Vous le terminerez par une barre oblique uniquement s'il fait référence à un répertoire et non à une page entière. Vous pouvez utiliser un ou plusieurs autoriser paramètres par règle.
- Plan du site :La directive sitemap est facultative et donne l'emplacement du plan du site pour le site Web. La seule condition est qu'il doit s'agir d'une URL complète. Vous pouvez utiliser zéro ou plus, selon ce qui est nécessaire.
Les robots d'indexation traitent les groupes de haut en bas. Comme mentionné précédemment, ils accèdent à toute page ou répertoire non explicitement défini sur interdire . Par conséquent, ajoutez Disallow :/ sous le user-agent informations dans chaque groupe pour empêcher ces agents utilisateurs spécifiques d'explorer votre site Web.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Pour bloquer un sous-domaine spécifique de tous les robots d'exploration, ajoutez une barre oblique et l'URL complète du sous-domaine dans votre règle d'interdiction.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtSi vous souhaitez bloquer un répertoire, suivez le même processus en ajoutant une barre oblique et le nom de votre répertoire, mais terminez ensuite par une autre barre oblique.
# Example
User-agent: *
Disallow: /images/Enfin, si vous souhaitez que tous les moteurs de recherche collectent des informations sur toutes les pages de votre site, vous pouvez soit créer un autoriser ou interdire règle, mais assurez-vous d'ajouter une barre oblique lorsque vous utilisez le autoriser règle. Des exemples des deux règles sont présentés ci-dessous.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Téléchargez votre fichier Robots.txt
Les sites Web ne sont pas automatiquement livrés avec un fichier robots.txt car il n'est pas requis. Une fois que vous avez décidé d'en créer un, téléchargez le fichier dans le répertoire racine de votre site Web. Le téléchargement dépend de la structure de fichiers de votre site et de votre environnement d'hébergement Web. Contactez votre fournisseur d'hébergement pour obtenir de l'aide sur la façon de télécharger votre fichier robots.txt.
5. Vérifiez que votre fichier Robots.txt fonctionne correctement
Il existe plusieurs façons de tester et de s'assurer que votre fichier robots.txt fonctionne correctement. Avec n'importe lequel d'entre eux, vous pouvez voir toutes les erreurs dans votre syntaxe ou votre logique. En voici quelques-uns :
- Le testeur robots.txt de Google dans leur console de recherche.
- L'outil de validation et de test robots.txt de Merkle, Inc.
- Outil de test robots.txt de Ryte.
Bonus :Utilisation de Robots.txt dans WordPress
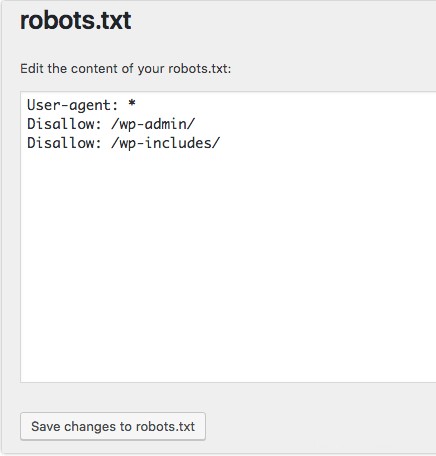
Si vous utilisez WordPress le plugin Yoast SEO, vous verrez une section dans la fenêtre d'administration pour créer un fichier robots.txt.
Connectez-vous au backend de votre site Web WordPress et accédez aux outils sous le SEO section, puis cliquez sur Éditeur de fichiers .
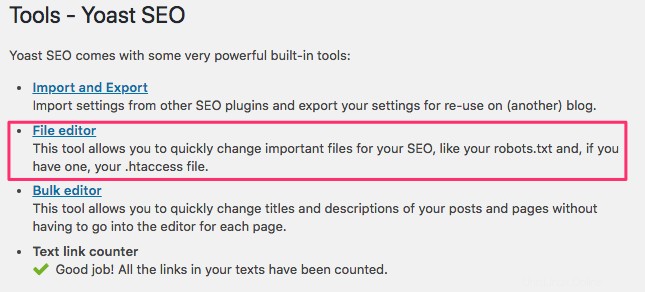
Suivez la même séquence que précédemment pour établir vos agents utilisateurs et vos règles. Ci-dessous, nous avons bloqué les robots d'exploration Web des répertoires WordPress wp-admin et wp-includes tout en permettant aux utilisateurs et aux robots de voir d'autres pages du site. Lorsque vous avez terminé, cliquez sur Enregistrer les modifications dans le fichier robots.txt pour activer le fichier robots.txt.