Apache Cassandra est l'une des bases de données NoSQL les plus populaires. Bien qu'il existe d'autres versions de NoSQL qui sont disponibles. Mais pourquoi Apache Cassandra est-il populaire ? regardons. Ici, nous verrons les fonctionnalités et l'installation d'Apache Cassandra.
Présentation
Les organisations manipulant une énorme quantité de données non structurées, la préférant. Il s'agit d'une base de données NoSQL basée sur Java. Sans schéma fixe, Cassandra est capable de gérer et de gérer un volume de données vraiment énorme. Il fonctionne avec le modèle peer to peer, où chaque nœud est connecté à tous les autres nœuds. Les nœuds ont une autorisation de lecture-écriture, donc pas besoin d'un nœud maître. Vous pouvez ajouter des nœuds sans fin dans le cluster.
Fonctionnalités
1. Architecture pair à pair
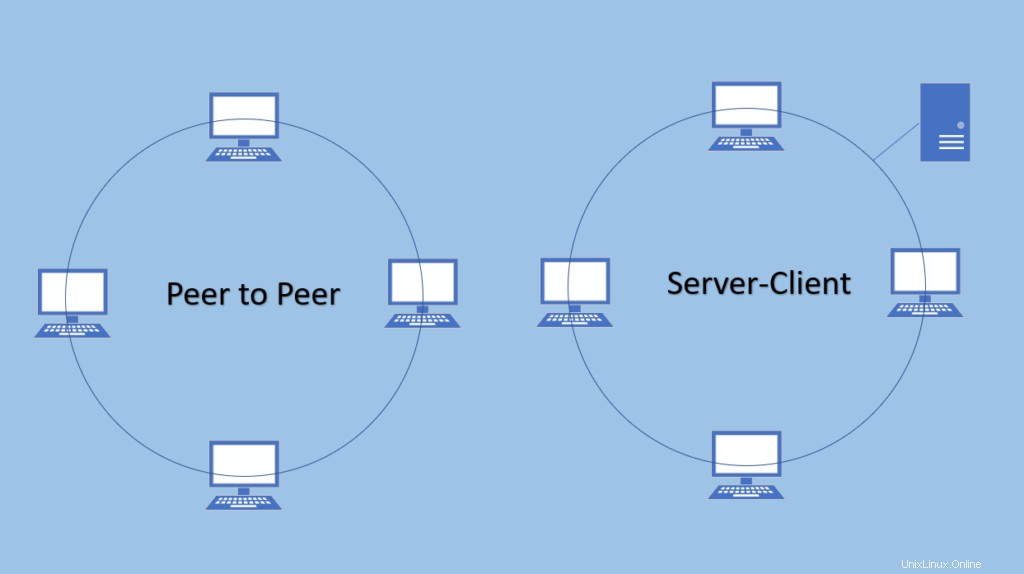
Il n'y a pas de dépendance de serveur maître, tous les nœuds sont traités de la même manière ici. Il n'y a aucune raison d'échouer en raison du modèle peer to peer et serveur.
2. Haute évolutivité
En raison de la conception du débit de lecture/écriture. Un nouveau nœud ou une nouvelle machine est ajouté, sans interrompre les applications en cours d'exécution ou les opérations en direct.
3. Tolérance aux pannes
Chaque nœud a la même copie de données. Supposons que 5 nœuds soient présents dans le cluster et que l'un d'eux cesse de fonctionner, ce nœud défectueux peut être supprimé rapidement.
4. Stockage de données flexible
Il peut prendre en charge toutes sortes de données structurées comme des formats de données semi-structurés, structurés et non structurés.
5. Stockage et accès rapides aux données
Il peut fonctionner même sur des structures matérielles bon marché, il peut stocker une énorme quantité de données sans sacrifier la vitesse du centre de données.
Installation
Prérequis :
- Dans cette démonstration d'installation, nous utiliserons Rocky Linux.
- Java et YUM mis à jour sont nécessaires pour effectuer la configuration.
Mettre d'abord à jour le système :
# yum update Installer JAVA et python
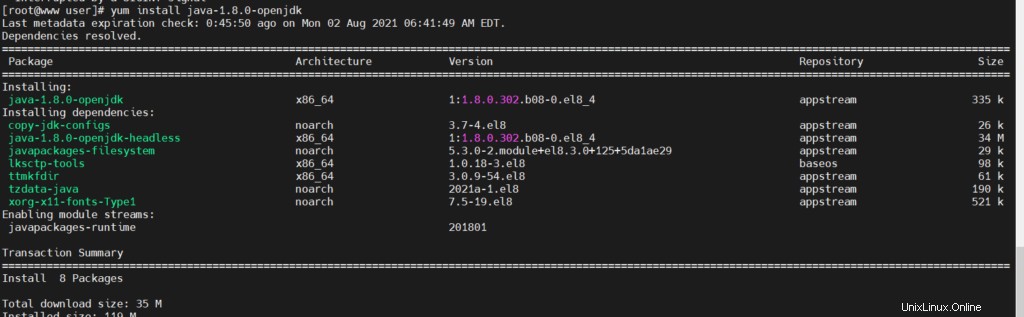
# yum install java-1.8.0-openjdk
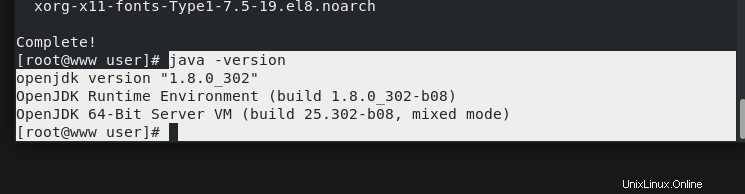
Après l'exécution de la commande, vérifiez quelle version de JAVA est installée.
# java -versionopenjdk version "1.8.0_302"
OpenJDK Runtime Environment (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (build 25.302-b08, mixed mode)
Maintenant, installons le référentiel Cassandra sur le serveur.
Créez un nouveau fichier de dépôt pour Cassandra, modifiez le fichier comme suit.
$ sudo vim /etc/yum.repos.d/cassandra.repo[cassandra]
name=Apache Cassandra
baseurl=https://downloads.apache.org/cassandra/redhat/40x/
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://downloads.apache.org/cassandra/KEYS
Installer le package.
$ sudo yum install cassandra -yModifiez les paramètres requis pour le cluster.
Le cluster par défaut nommé "Test Cluster" par défaut. Vous devez le renommer. Toutes les configurations sont stockées dans /etc/cassandra . Toutes les données de fouillis sont stockées dans /var/lib/cassandra
Changez le nom du cluster, passez en ligne de commande.
# cqlsh
cqlsh> UPDATE system.local SET cluster_name = 'unixcop Cluster' WHERE KEY = 'local';
# service cassandra restart
Ouvrez cassandra.yaml, renommez le nom du cluster. Enregistrez le fichier et quittez.
# cd /etc/cassandra/default.confOuvrez le fichier et effectuez les modifications requises.
# vim cassandra.yaml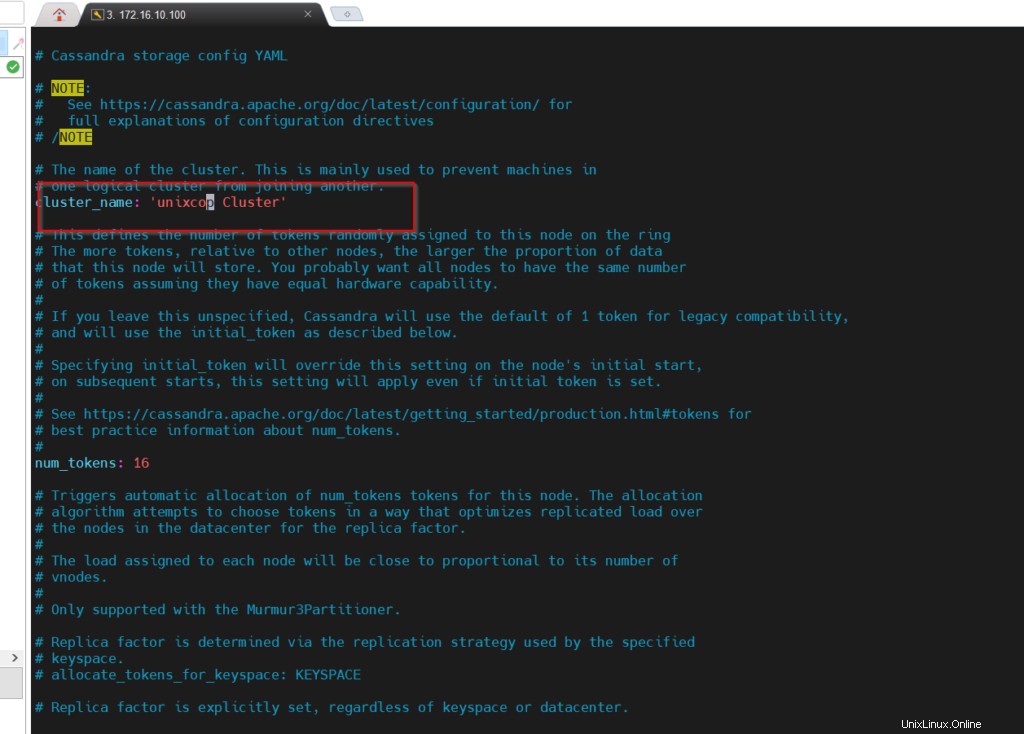
Redémarrez le service et c'est parti.
Conclusion
Aujourd'hui, nous avons montré comment configurer et renommer la base de données Cassandra. Bien qu'il s'agisse de l'une des bases de données NoSQL les plus populaires, elle ne convient pas à toutes les exigences complexes en matière de bases de données. Au départ, il s'agissait d'un projet open source, qui fait maintenant partie du projet Apache.