Dans la première partie, j'ai discuté de la fonction et de l'utilisation des cgroups pour l'administration système et le réglage des performances. Dans la deuxième partie, j'ai noté la complexité des valeurs cgroups et CPUShares. Ici, dans la troisième partie, je me concentre sur les tâches administratives manuelles pour les cgroups.
N'oubliez pas de lire la quatrième partie sur le fonctionnement des cgroups avec systemd.
Faire des cgroups à la dure
Voyons comment créer des groupes de contrôle sans aucun des outils qui les entourent. Au fond, les cgroups sont simplement une structure de répertoires avec cgroups monté en eux. Ils peuvent être situés n'importe où sur le système de fichiers, mais vous trouverez les cgroups créés par le système dans /sys/fs/cgroup par défaut. Alors, comment créez-vous des groupes de contrôle ? Commencez par créer le répertoire de niveau supérieur suivant :
# mkdir -p /my_cgroups Une fois celui-ci créé, décidez quels contrôleurs vous souhaitez utiliser. N'oubliez pas que la structure des cgroups version 1 ressemble à ceci :
/my_cgroups
├── <controller type>
│ ├── <group 1>
│ ├── <group 2>
│ ├── <group 3> [ Les lecteurs ont également aimé :Une introduction à crun, un environnement d'exécution de conteneur rapide et à faible empreinte mémoire ]
Tous les groupes que vous souhaitez créer sont imbriqués séparément sous chaque type de contrôleur. Par conséquent, group1 sous le contrôleur memory est complètement indépendant de group1 dans blkio . Dans cet esprit, créons un exemple CPUShares de base.
Pour simplifier, je vais générer une charge sur le système en exécutant :
# cat /dev/urandom Cela met une charge artificielle sur le système pour une mesure facile. Ce n'est pas un exemple de charge réel, mais il met en évidence les principaux points de CPUShares. J'ai également configuré une machine virtuelle exécutant CentOS 8 avec un seul vCPU pour simplifier les calculs. Dans cet esprit, la première étape consiste à créer des répertoires pour nos contrôleurs de groupe de contrôle :
# mkdir -p /my_cgroups/{memory,cpusets,cpu} Ensuite, montez les cgroups dans ces dossiers :
# mount -t cgroup -o memory none /my_cgroups/memory
# mount -t cgroup -o cpu,cpuacct none /my_cgroups/cpu
# mount -t cgroup -o cpuset none /my_cgroups/cpusets
Pour créer vos propres groupes de contrôle, créez simplement un nouveau répertoire sous le contrôleur que vous souhaitez utiliser. Dans ce cas, j'ai affaire au fichier cpu.shares , qui se trouve dans le cpu annuaire. Créons donc quelques groupes de contrôle sous le cpu contrôleur :
# mkdir -p /my_cgroups/cpu/{user1,user2,user3} Notez que les répertoires sont automatiquement remplis par le contrôleur :
# ls -l /my_cgroup/cpu/user1/
-rw-r--r--. 1 root root 0 Sep 5 10:26 cgroup.clone_children
-rw-r--r--. 1 root root 0 Sep 5 10:26 cgroup.procs
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.stat
-rw-r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_all
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_percpu
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_percpu_sys
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_percpu_user
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_sys
-r--r--r--. 1 root root 0 Sep 5 10:26 cpuacct.usage_user
-rw-r--r--. 1 root root 0 Sep 5 10:26 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 Sep 5 10:26 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 Sep 5 10:26 cpu.rt_period_us
-rw-r--r--. 1 root root 0 Sep 5 10:26 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 Sep 5 10:20 cpu.shares
-r--r--r--. 1 root root 0 Sep 5 10:26 cpu.stat
-rw-r--r--. 1 root root 0 Sep 5 10:26 notify_on_release
-rw-r--r--. 1 root root 0 Sep 5 10:23 tasks Maintenant que j'ai configuré des groupes de contrôle, il est temps de générer de la charge. Pour cela, j'ouvre simplement trois sessions SSH et j'exécute la commande suivante au premier plan :
# cat /dev/urandom
Vous pouvez voir les résultats en top :
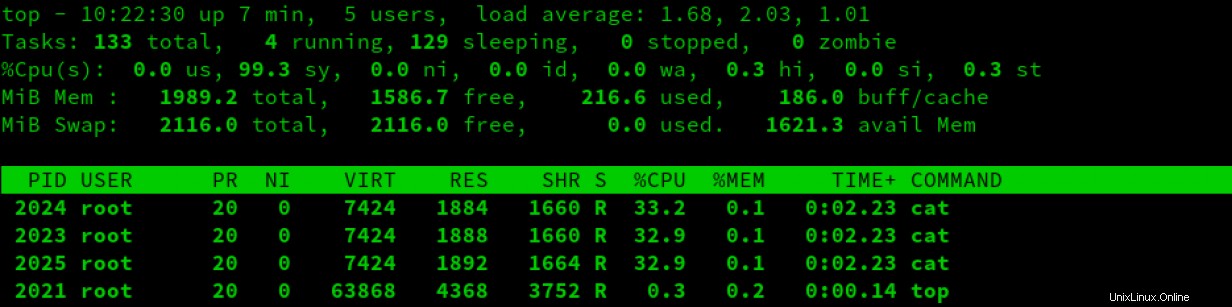
REMARQUE IMPORTANTE :N'oubliez pas que les CPUShares sont basés sur le groupe de contrôle de niveau supérieur, qui n'est pas contraint par défaut. Cela signifie que si un processus plus haut dans l'arborescence demande des CPUShares, le système donnera la priorité à ce processus. Cela peut dérouter les gens. Il est essentiel d'avoir une représentation visuelle de la disposition du groupe de contrôle sur un système pour éviter toute confusion.
Dans la capture d'écran ci-dessus, vous pouvez voir que tous les cat les processus reçoivent plus ou moins la même quantité de temps CPU. En effet, par défaut, les cgroups reçoivent une valeur 1024 dans cpu.shares . Ces partages sont limités par la relation du parent avec d'autres groupes de contrôle, comme indiqué précédemment. Dans notre exemple, je n'ai ajusté le poids d'aucun des parents. Par conséquent, si tous les cgroups parents demandent des ressources simultanément, le poids par défaut de 1024 CPUShares s'applique.
Pour en revenir à notre exemple, j'ai créé un groupe de contrôle avec des valeurs par défaut. Cela signifie que chaque groupe a le poids par défaut de 1024. Pour changer cela, changez simplement les valeurs dans le cpu.shares fichier :
# echo 2048 > user1/cpu.shares
# echo 768 > user2/cpu.shares
# echo 512 > user3/cpu.shares
Excellent, j'ai maintenant un calcul de pondération plus compliqué, mais je n'ai en fait ajouté aucun processus au groupe de contrôle. Par conséquent, le groupe de contrôle est inactif. Pour ajouter un processus à un groupe de contrôle, ajoutez simplement le PID souhaité aux tasks fichier :
# echo 2023 > user1/tasks
Voici le résultat de l'ajout d'un processus dans un cgroup comme on le voit dans top :
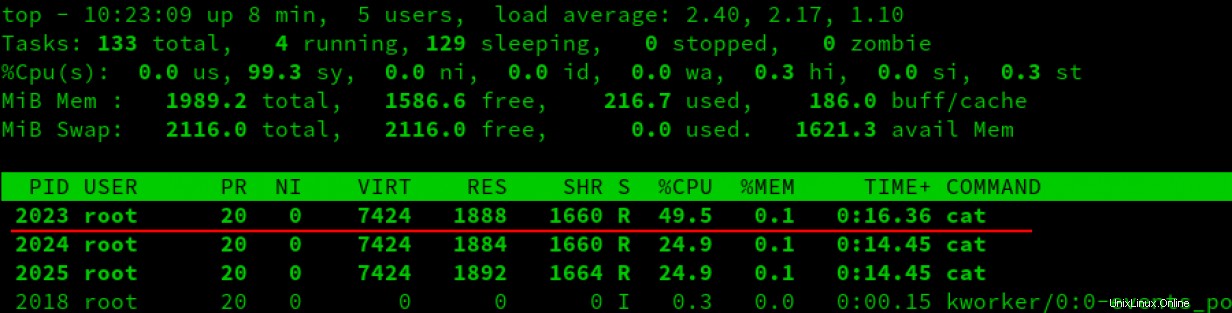
Comme vous le voyez dans la capture d'écran ci-dessus, le processus dans le nouveau groupe de contrôle reçoit environ la moitié du temps CPU. C'est à cause de l'équation de tout à l'heure :
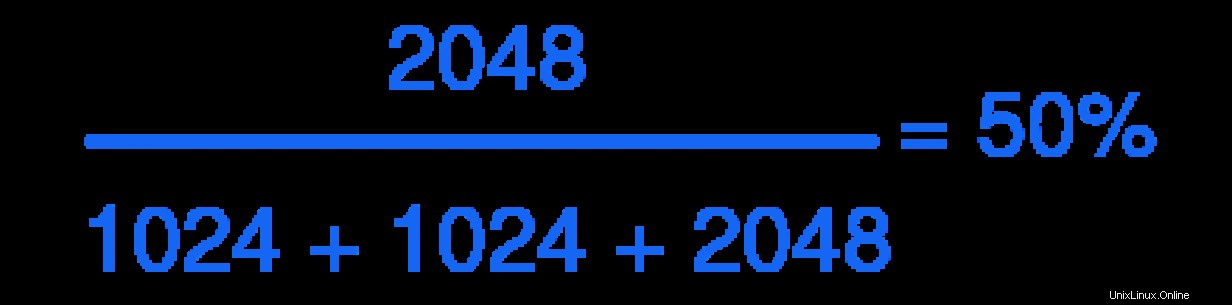
Continuons et ajoutons les deux autres processus dans leurs groupes de contrôle respectifs et observons les résultats :
# echo 2024 > user2/tasks
# echo 2025 > user3/tasks 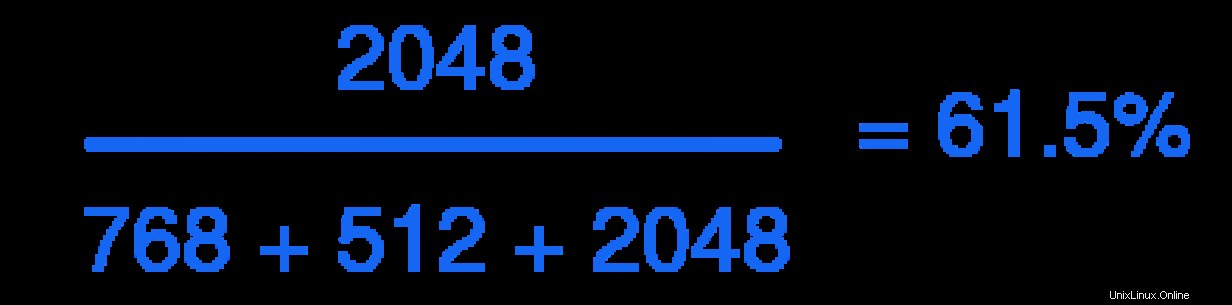
Nous voyons maintenant que la pondération a pris effet, avec le cgroup user1 occupant environ 61 % du temps CPU :
Le temps restant est partagé entre user2 et utilisateur3 .
Il y a, bien sûr, plusieurs problèmes avec notre configuration de test.
- Ceux-ci sont tous créés à la main. Que se passe-t-il si le processus que vous mettez dans un cgroup change son PID ?
- Les fichiers et dossiers personnalisés créés ne survivront pas à un redémarrage.
- C'est beaucoup de travail manuel. Où est l'outillage ?
N'ayez crainte, mes amis, systemd vous couvre.
[ Cours en ligne gratuit :Présentation technique de Red Hat Enterprise Linux. ]
Conclusion
Maintenant que nous comprenons mieux l'administration manuelle des cgroups, nous pouvons mieux apprécier la valeur de cgroups et systemd travaillant ensemble. J'examine cette idée dans la quatrième partie de cette série. Incidemment, la quatrième partie est la conclusion.