Valeurs séparées par des virgules alias CSV est une donnée semi-structurée qui utilise une virgule comme délimiteur pour séparer les mots. Les formats de fichiers CSV sont très populaires parmi les professionnels des données, car ils doivent gérer de nombreux fichiers CSV et les traiter pour créer des informations. Dans cet article, nous nous concentrerons sur l'analyse des fichiers CSV dans les scripts shell Bash sous Linux.
Dans la plupart des parties de cet article, j'utiliserai awk et sed des outils pour l'analyse csv au lieu de combiner différentes commandes comme grep , cut , tr , etc.
Le awk L'utilitaire réduit la complexité de diriger plusieurs commandes ou d'écrire une boucle avec une logique pour saisir les données. Au lieu de cela, vous pouvez écrire un code à une ligne dans awk pour faire le travail.
1. Préparation du fichier CSV pour le traitement
Votre fichier CSV peut être généré à partir d'une base de données, d'une API, ou vous avez peut-être exécuté certaines commandes et converti la sortie pour délimiter au format CSV. Dans tous les cas, vous devez d'abord analyser l'ensemble de données avant d'exécuter votre logique dessus.
Comme bonne pratique, vous devez nettoyer votre jeu de données avant de l'utiliser. Pourquoi devrions-nous nettoyer l'ensemble de données ? Il peut y avoir des situations où il y aura des valeurs de cellules vides ou aucun formatage approprié dans les en-têtes, des colonnes supplémentaires qui ne sont pas nécessaires pour le traitement, et bien d'autres.
J'utilise les données CSV ci-dessous, que j'ai extraites de Kaggle à des fins de démonstration.
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1. Remplacer les cellules vides
Dans certains cas, le fichier CSV n'aura aucune valeur dans des cellules particulières. Jetez un œil à la capture d'écran ci-dessous où il y a des cellules vides entre les colonnes.
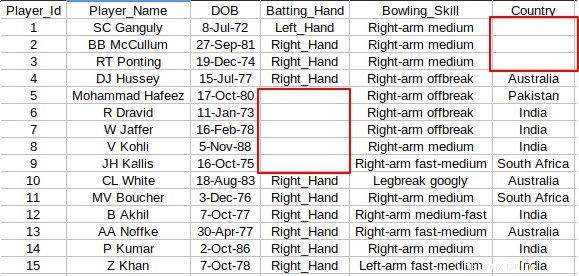
Je le remplacerais toujours par "NA" ou "Aucune valeur", donc il n'y aura pas de cellules vides. Vous pouvez utiliser le awk suivant extrait pour remplacer toute cellule vide par la valeur souhaitée. Dans ce cas, je remplace les cellules vides par "Aucune valeur".
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
La façon dont cet extrait fonctionne est que je définis le séparateur de champ et le séparateur de champ de sortie sur une virgule (FS=",";OFS="," ). Utilisation de la for loop , parcourir chaque cellule d'une ligne, et si une cellule est trouvée vide ($i == "" ) puis remplacez-le par "No value" ($i="No value" ). Vous devez rediriger les modifications vers un nouveau fichier.
Lecture suggérée :
- La redirection bash expliquée avec des exemples
1.2. Mettre l'en-tête en majuscule
Les fichiers CSV peuvent avoir ou non des en-têtes. Mais s'il y a un en-tête, je le mettrais toujours en majuscule pour une meilleure lisibilité. Vous pouvez le faire facilement en utilisant awk ou sed . Je vais vous montrer les deux façons.
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv
Ici, nous vérifions si la ligne est la première ligne en utilisant (NR==1 ) et en utilisant le toupper() fonction de la capitaliser. Le même extrait peut être écrit en une seule ligne.
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
Utiliser awk , vous devez à nouveau rediriger les modifications vers un nouveau fichier. Au lieu de cela, vous pouvez utiliser 'sed ' pour modifier les modifications directement dans le fichier. Ici \U convertit la casse en majuscule. Si vous voulez faire une conversion en minuscules, utilisez \L .
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3. Supprimer la virgule de fin
Votre fichier CSV peut avoir une virgule à la fin. Pour nettoyer les virgules de fin, vous pouvez suivre la méthode ci-dessous.
J'ai volontairement ajouté une virgule à partir des lignes 7 à 11 dans mon fichier de données.
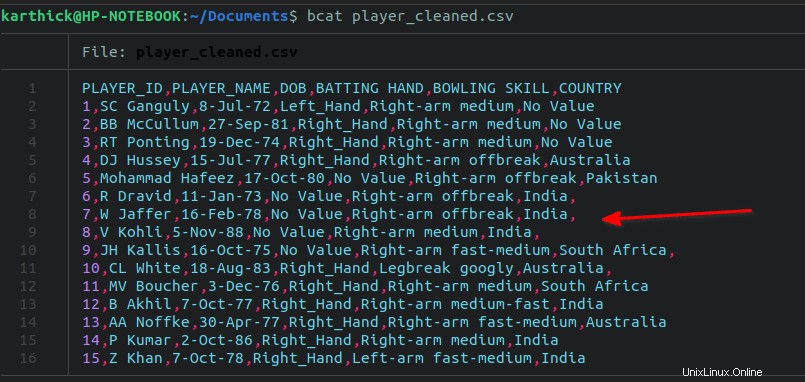
Pour supprimer toutes les virgules de fin, exécutez le sed suivant commande :
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
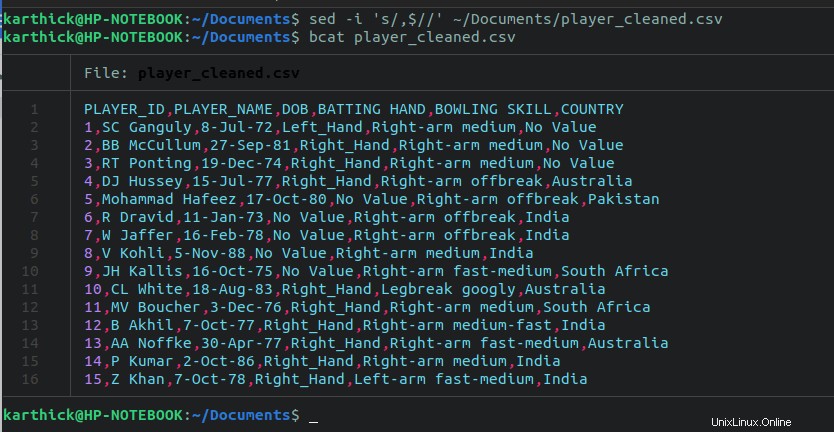
Maintenant, nous en avons fini avec la partie nettoyage. Quelques étapes supplémentaires peuvent être nécessaires pour vous, mais cela dépend de la structure de votre fichier CSV et de ce qui doit être nettoyé.
2. Jolie impression de fichier CSV dans le terminal
Si vous essayez d'afficher les fichiers CSV dans le terminal, il existe quelques options où vous pouvez imprimer le fichier au format tabulaire, ce qui vous donnera une meilleure lisibilité.
2.1. Commande de colonne
La première approche consiste à utiliser la column commande. La commande de colonne accepte un séparateur défini sur virgule et un délimiteur pour diviser la colonne définie sur tabulation dans la commande ci-dessous. Vous pouvez également définir vos propres délimiteurs personnalisés.
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
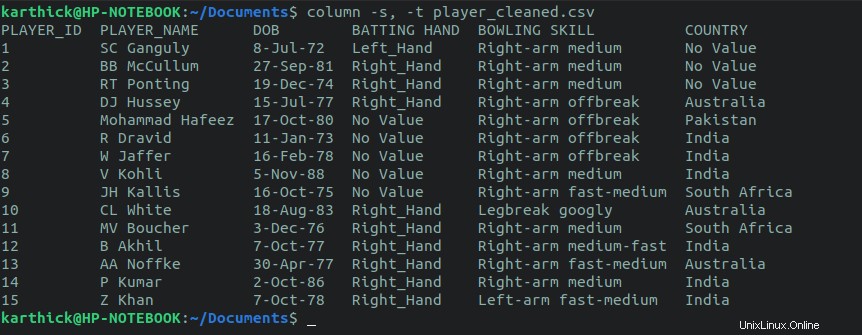
2.2. Commande de visualisation CSV
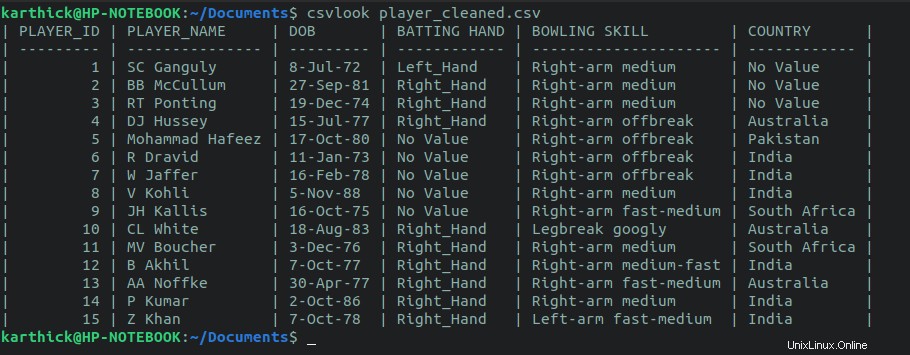
Csvlook est un utilitaire fourni avec le package csvkit. Il n'est pas nécessaire de définir un délimiteur comme nous l'avons fait avec la column commande.
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3. Jolie Table Python
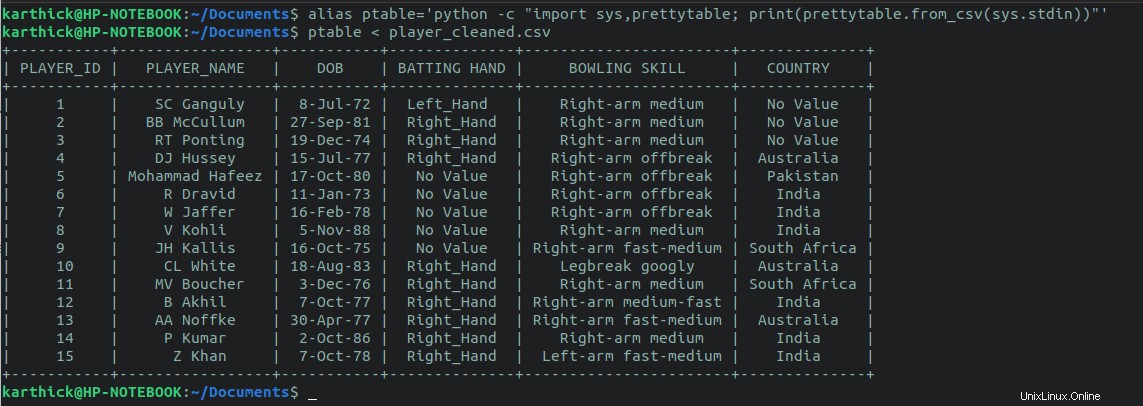
Si vous avez le python prettytable module installé, vous pouvez exécuter le one-liner suivant et rediriger le fichier CSV pour générer le tableau.
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
Vous pouvez également créer un alias pour le one-liner et passez le nom du fichier comme argument.
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3. Récupérer des données à partir d'un fichier CSV
3.1. Imprimer le nombre de lignes et de colonnes
Pour obtenir le nombre de colonnes dans le fichier CSV, exécutez la commande suivante. Ici la variable NF représente le nombre de champs séparés par une virgule comme délimiteur.
$ awk -F, 'END{print NF}' player_cleaned.csv
6
Pour obtenir le nombre de lignes, exécutez la commande suivante. Ici la variable NR représente l'enregistrement en cours (c'est-à-dire que chaque ligne est considérée comme un enregistrement.
$ awk -F, 'END{print NR}' player_cleaned.csv
16 Pour ignorer la première ligne (en-tête) et calculer le nombre de lignes, exécutez la commande suivante.
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2. Imprimer le fichier CSV entier
C'est assez simple. Vous pouvez utiliser cat ou awk pour imprimer l'intégralité du fichier CSV.
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3. Imprimer uniquement l'en-tête du fichier CSV
L'impression de l'en-tête seul vous donnera un bon aperçu du type de données que contient votre fichier CSV. Vous pouvez utiliser le head ou awk commande pour saisir l'en-tête seul.
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
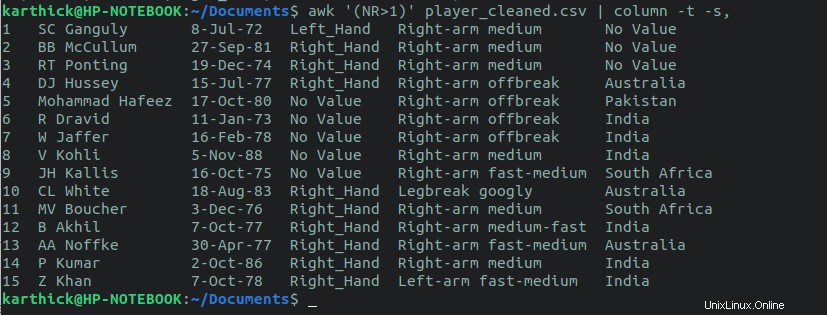
3.4. Exclure la ligne d'en-tête
Pour exclure la ligne d'en-tête et imprimer toutes les autres lignes, utilisez le awk commande. La variable awk NR > 1 fera sauter la première ligne.
$ awk '(NR>1)' player_cleansed.csv
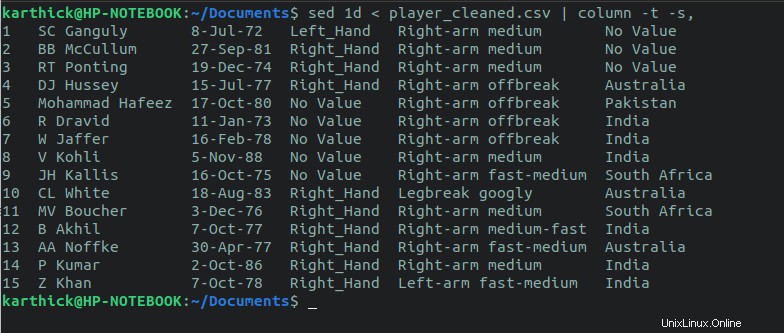
Sed peut également être utilisé pour exclure la première ligne et imprimer toutes les autres lignes. Le 1d flag supprimera la première ligne et imprimera toutes les autres lignes sur stdout (Terminal).
$ sed 1d < player_cleaned.csv
3.5. Imprimer des colonnes particulières
Nous pouvons utiliser la position de la colonne pour imprimer la colonne entière. Il existe deux approches pour y parvenir. La première approche consistera à utiliser awk et la deuxième approche consistera à utiliser des boucles . Awk sera beaucoup plus simple pour saisir la colonne.
Awk divise par défaut la ligne en fonction du délimiteur et stocke les valeurs dans $1 , $2 , $3 , etc. Le délimiteur par défaut pour awk est l'espace blanc .
Jetez un œil à l'extrait ci-dessous où le séparateur de champ (FS="," ) et séparateur de champ de sortie (OFS="," ) est défini sur une virgule. L'instruction d'impression imprimera la première colonne, la deuxième colonne et la sixième colonne.
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv Vous pouvez également écrire l'extrait ci-dessus en une seule ligne.
awk 'BEGIN{FS=",";OFS=","}{print $1,$2,$6}' player_cleansed.csv 
Maintenant, la deuxième approche serait d'utiliser des boucles.
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv Laissez-moi vous expliquer ce qui se passe exactement lorsque vous exécutez l'extrait ci-dessus.
- Nous définissons le séparateur de champ interne IFS sur une virgule.
- En utilisant la commande read, nous créons un tableau nommé "fields" et redirigeons le fichier d'entrée vers la
while loop. - Pour chaque itération, il lira ligne par ligne et stockera la ligne sous forme d'éléments de tableau dans des "champs" afin que vous puissiez utiliser la position d'index du tableau pour saisir uniquement la colonne particulière.
Remarque : La valeur de l'index commence à partir de 0..N
3.6. Imprimer la ligne correspondant à la condition
Si vous souhaitez imprimer les lignes qui correspondent à une certaine condition, vous pouvez le faire facilement en utilisant awk . Passons en revue quelques scénarios.
Pour imprimer toutes les lignes qui correspondent à une valeur dans une colonne, exécutez la commande suivante. Ici, j'essaie d'imprimer toutes les lignes qui correspondent à la valeur "Inde" dans la colonne 6.
$ awk -F , '$6 == "India"' player_cleaned.csv

Pour imprimer toutes les lignes qui ne correspondent pas à une certaine valeur, exécutez la commande suivante. Au lieu d'un opérateur d'égalité , nous utilisons un opérateur non égal .
$ awk -F , '$6 != "India"' player_cleaned.csv
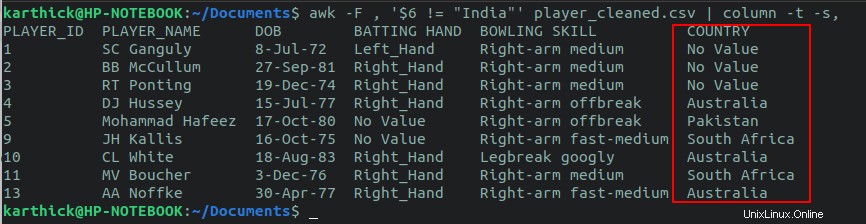
Vous pouvez également effectuer une vérification de condition sur plusieurs colonnes à l'aide de l'opérateur logique ET, logique OU. Disons que je veux vérifier toutes les lignes qui ont le pays comme "Inde" et la main au bâton comme "Right_hand".
Ici, $4 pointe vers la 4ème colonne et $6 pointe vers la 6e colonne. Le symbole && est utilisé comme opérateur logique ET pour évaluer deux conditions.
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

Si vous souhaitez inclure l'en-tête avec le résultat de la vérification conditionnelle, utilisez la commande suivante. J'imprime d'abord la première ligne en utilisant NR==1 , puis en utilisant l'opérateur logique AND exécutant la vérification conditionnelle pour imprimer les résultats.
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
Si vous souhaitez imprimer ou rediriger la sortie, exécutez la commande entière dans un sous-shell en l'entourant de crochets .
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Une remarque sur Csvkit
Jusqu'à présent, tout ce que nous avons vu dans cet article est simple et direct. Mais lorsque votre fichier CSV a une structure complexe, il devient fastidieux de l'analyser en utilisant l'approche ci-dessus. Il existe un utilitaire appelé CSVKIT , qui est un excellent utilitaire pour travailler avec des fichiers CSV dans bash.
Le problème avec l'utilitaire csvkit est qu'il est installé par défaut dans votre distribution et que vous devrez peut-être l'installer manuellement. Dans votre environnement d'entreprise, cela peut ne pas être possible car il peut y avoir certaines restrictions à l'installation de packages externes. Mais cet utilitaire vaut la peine d'être mentionné et nous allons créer un article détaillé séparé pour cela.
Conclusion
Dans ce guide, nous avons vu comment travailler avec des fichiers CSV en utilisant awk, sed. Vous pouvez également utiliser d'autres utilitaires comme cut, grep, tr, etc. pour obtenir le résultat souhaité, mais awk et sed vous simplifieront la vie et réduiront la complexité de l'écriture de nombreux codes. Si vous avez des commentaires, mentionnez-les dans la section des commentaires et nous serons heureux de les entendre.
Lecture similaire :
- Scripts bash :analyse des arguments dans les scripts bash à l'aide de getops
- Comment analyser et imprimer JSON avec les outils de ligne de commande Linux