Elastic Kubernetes Service (EKS) est un service Kubernetes géré hébergé sur AWS.
La principale raison d'utiliser EKS est de supprimer le fardeau de la gestion des pods, des nœuds, etc. L'exécution de Kubernetes dans AWS nécessite actuellement une grande expertise technique et ne relève souvent pas de la timonerie de nombreuses organisations. Avec EKS, l'infrastructure requise est gérée par l'équipe « interne » d'Amazon, ce qui laisse aux utilisateurs un moteur Kubernetes entièrement géré qui peut être utilisé via une API ou des outils kubectl standard.
EKS prendra en charge toutes les fonctionnalités de Kubernetes, y compris les espaces de noms, les paramètres de sécurité, les quotas et tolérances de ressources, les stratégies de déploiement, les autoscalers et plus encore. EKS vous permettra d'exécuter votre propre plan de contrôle, mais s'intègre également à AWS IAM afin que vous puissiez maintenir votre propre contrôle d'accès à l'API.
EKS a été construit sur la solution « Kubernetes — as-a-Service » existante d'Amazon appelée Elastic Container Service for Kubernetes (EKS). Il s'agit d'un service géré par AWS qui simplifie le déploiement, la gestion et le fonctionnement des clusters Kubernetes dans le cloud AWS.
Si vous exécutez Kubernetes sur AWS, vous êtes responsable de la gestion du plan de contrôle (c'est-à-dire les nœuds maîtres et les nœuds de travail). Vous devez également vous assurer que le serveur api est hautement disponible et tolérant aux pannes, etc.
EKS vous a enlevé la charge de gérer le plan de contrôle, ce faisant, vous pouvez désormais vous concentrer sur l'exécution de vos charges de travail Kubernetes. Il est le plus souvent utilisé pour les applications sans état comme les microservices puisque le plan de contrôle est géré par Amazon (EKS).
Dans ce guide, nous apprendrons à créer un cluster Kubernetes sur AWS avec EKS. Vous apprendrez à créer un utilisateur administratif pour votre cluster Kubernetes. Vous apprendrez également à déployer une application sur le cluster. Enfin, vous testerez votre cluster pour vous assurer que tout fonctionne correctement.
Commençons !
Prérequis
- Un compte AWS.
- Cet article part du principe que vous connaissez Kubernetes et AWS. Si ce n'est pas le cas, veuillez prendre le temps de parcourir la documentation sur les deux avant de commencer ce guide.
Création d'un utilisateur administrateur avec autorisations
Commençons par créer un utilisateur administrateur pour votre cluster.
1. Connectez-vous à votre console AWS et accédez à IAM. Cliquez sur Utilisateurs> Ajouter des utilisateurs.
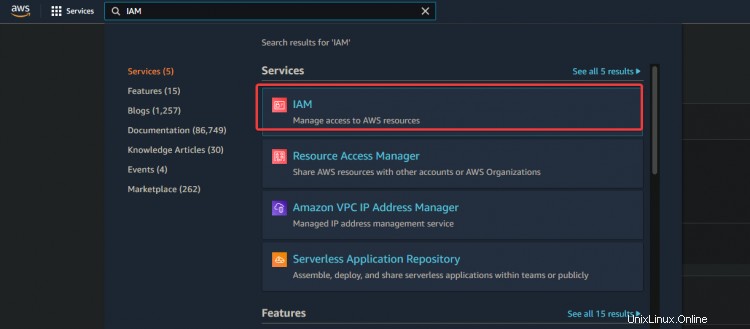

2. Sur l'écran suivant, fournissez un nom d'utilisateur comme admin . Sélectionnez Clé d'accès - Accès programmatique. Cliquez sur Suivant :Autorisations
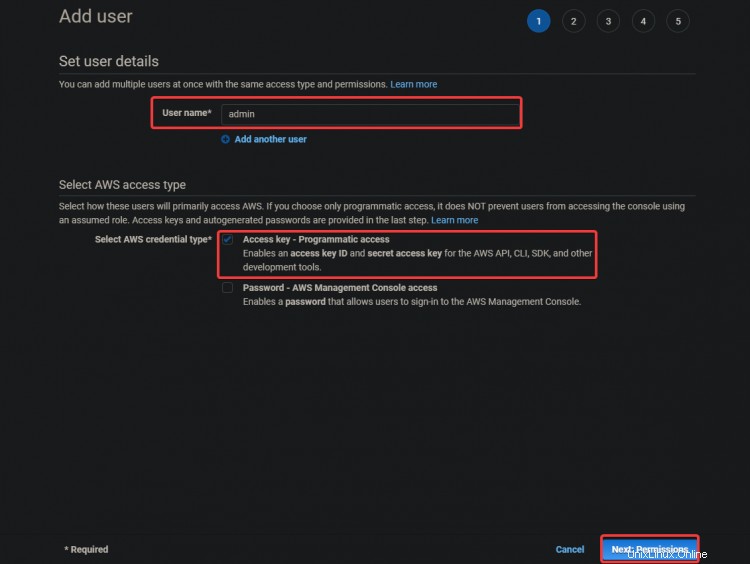
3. Sur l'écran suivant, sélectionnez Joindre directement les règles existantes. . Cliquez sur Accès Administrateur . Cliquez sur Suivant :Balises .
L'accès administrateur La stratégie est une stratégie intégrée à Amazon Elastic Container Service (ECS). Il fournit un accès complet à toutes les ressources ECS et à toutes les actions de la console ECS. Le principal avantage de cette politique est que nous n'avons pas besoin de créer ou de gérer un utilisateur supplémentaire avec des privilèges supplémentaires pour accéder au service AWS EKS.
Votre utilisateur administrateur peut créer des instances EC2, des piles CloudFormation, des compartiments S3, etc. Vous devez faire très attention à qui vous accordez ce type d'accès.
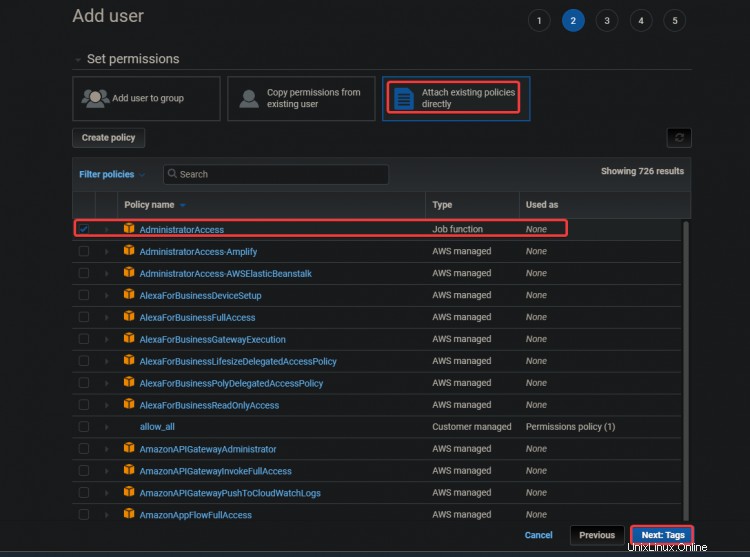
3. Sur l'écran suivant, cliquez sur Suivant :Réviser
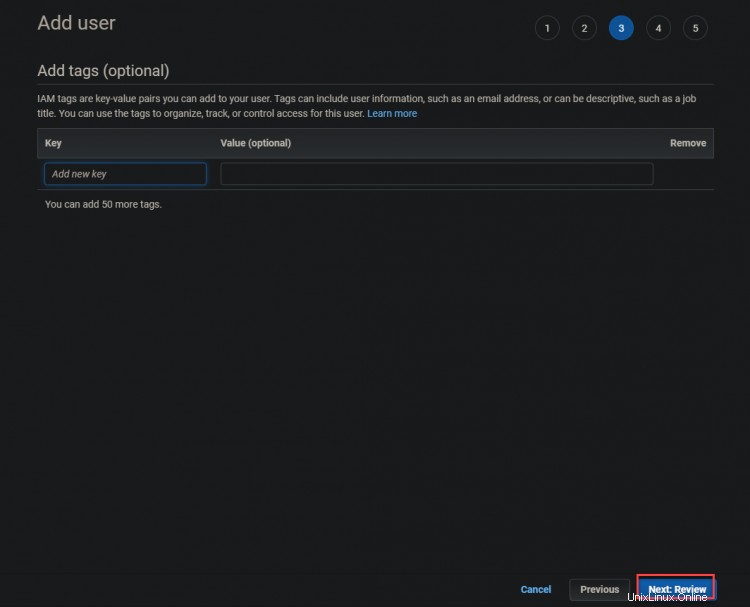
4. Sur l'écran suivant, cliquez sur Créer utilisateur .
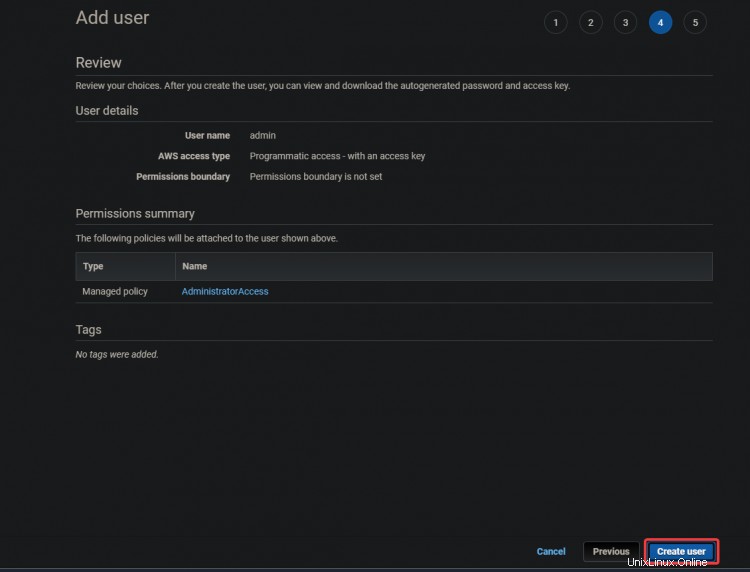
5. Sur l'écran suivant, vous obtiendrez un Succès vert message. L'identifiant de la clé d'accès et
Clés d'accès secrètes sont également affichés sur cet écran. Vous aurez besoin de ces clés pour configurer vos outils CLI ultérieurement, alors notez-les ailleurs.
Création d'une instance EC2
Maintenant que vous avez créé l'utilisateur administratif , créons une instance EC2 à utiliser comme nœud maître Kubernetes.
1. Tapez EC2 dans la zone de recherche. Cliquez sur le lien EC2. Cliquez sur Lancer l'instance .


2. Sélectionnez l'Amazon Linux 2 AMI (HVM) pour votre instance EC2. Nous utiliserons cette AMI Amazon Linux pour faciliter l'installation ultérieure de Kubernetes et d'autres outils nécessaires, tels que :kubectl !, docker, etc.
3. Sur l'écran suivant, cliquez sur Suivant :Configurer l'instance Détails .

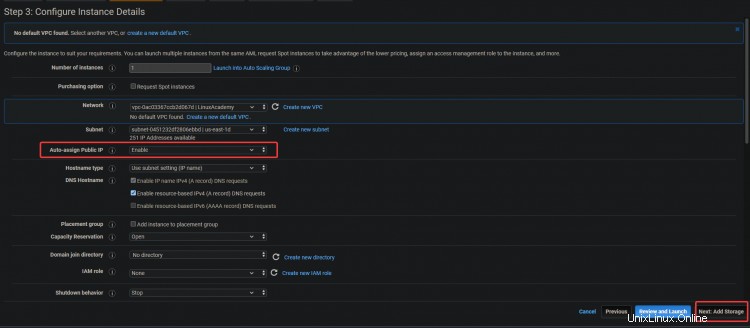
3. Sur l'écran suivant, activez l'option Auto-assign Public IP option. Étant donné que le serveur se trouve dans un sous-réseau privé, il ne sera pas accessible de l'extérieur. Vous pouvez attribuer des adresses IP publiques à vos serveurs en associant une adresse IP Elastic à l'instance. En faisant cela, votre EC2 et ELK sont accessibles. Cliquez sur Suivant :Stockage .
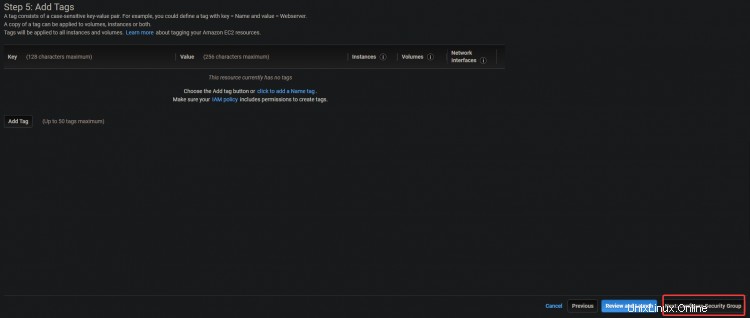
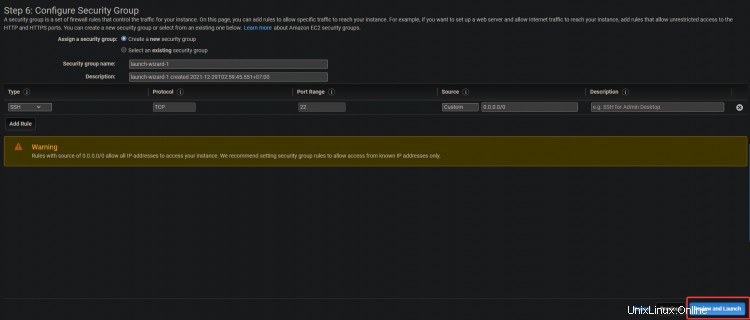
3. Sur l'écran suivant, cliquez sur Suivant :Ajouter des balises> Suivant :Configurer le groupe de sécurité .
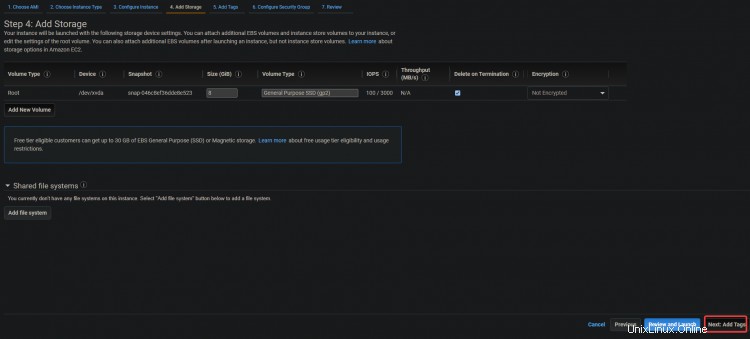
4. Sur l'écran suivant, cliquez sur Examiner et lancer> Lancer .
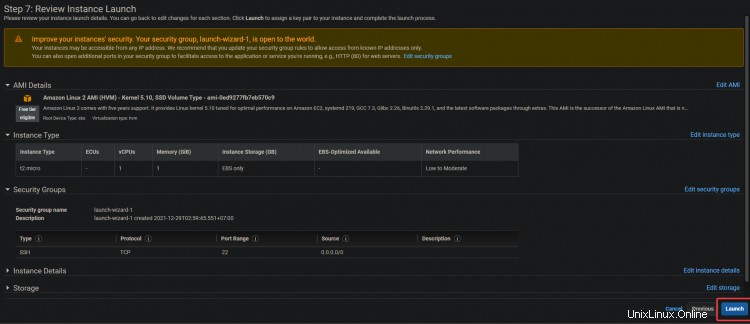
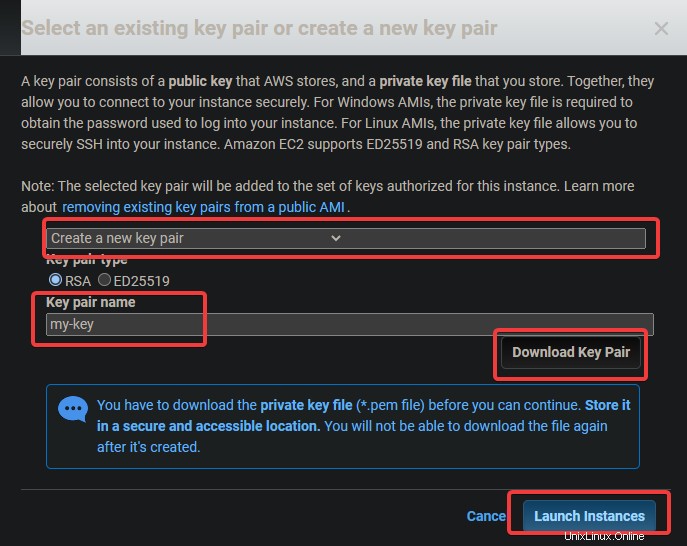
5. Une boîte de dialogue de paire de clés s'affiche. Appuyez sur Créer une nouvelle paire de clés . Donnez-lui un nom, puis téléchargez et stockez le fichier .pem dans un emplacement sécurisé. Cliquez sur Lancer instance .
Configuration des outils de ligne de commande
Maintenant que vous avez créé une instance EC2, vous devez installer le client correspondant. En termes AWS, un client est un outil de ligne de commande qui vous permet de gérer des objets cloud. Dans cette section, vous apprendrez à configurer les outils de l'interface de ligne de commande (CLI).
1. Accédez à votre tableau de bord EC2. Vous devriez voir votre nouvelle instance EC2 en cours d'exécution. Si ce n'est pas le cas, votre instance peut effectuer son premier démarrage, attendre 5 minutes et réessayer. Une fois votre instance en cours d'exécution, cliquez sur Se connecter .

2. Sur l'écran suivant, cliquez sur Se connecter .

Vous serez redirigé vers une session SSH interactive sur votre navigateur. SSH vous permet de vous connecter et d'opérer en toute sécurité sur un serveur distant. La session SSH interactive nous permettra d'installer les outils de ligne de commande pour EKS et Kubernetes directement sur votre instance EC2.

Une fois que vous vous êtes connecté à la session SSH, la première chose que vous devez faire est de vérifier votre version aws-cli. Cela permet de s'assurer que vous utilisez la dernière version d'AWS CLI. L'AWS CLI est utilisée pour configurer, gérer et travailler avec votre cluster.
Si votre version est obsolète, vous pouvez rencontrer des problèmes et des erreurs lors du processus de création du cluster. Si votre version est inférieure à 2.0, vous devrez la mettre à niveau.
3. Exécutez la commande suivante pour vérifier votre version CLI.
aws --version
Comme vous pouvez le voir dans la sortie ci-dessous, nous exécutons la version 1.18.147 de aws-cli , ce qui est très dépassé. Mettons à niveau l'interface de ligne de commande vers la dernière version disponible, qui est v2+ au moment d'écrire ces lignes.

4. Exécutez la commande ci-dessous pour télécharger la dernière version disponible de l'AWS CLI sur votre instance EC2. curl téléchargera votre fichier à partir de l'url donnée, -o le nommera comme vous le souhaitez et "awscli-exe-linux-x86_64.zip" est le fichier à télécharger
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"

5. Une fois le téléchargement terminé, exécutez la commande ci-dessous pour extraire le contenu de votre fichier téléchargé dans le répertoire actuel.
unzip awscliv2.zip
6. Ensuite, exécutez la commande which aws pour définir votre lien pour la dernière version de l'AWS CLI. Cette commande vous permettra de savoir où elle se trouve dans le PATH de votre environnement, afin que vous puissiez l'exécuter à partir de n'importe quel répertoire.
which aws
Comme vous pouvez le voir dans la sortie ci-dessous, l'AWS CLI obsolète se trouve à /usr/bin/aws .

7. Vous devez maintenant configurer votre aws-cli en exécutant une commande de mise à jour avec certains paramètres. Le premier paramètre ./aws/install nous aidera à installer l'AWS CLI dans le répertoire actuel. Le deuxième paramètre --bin-dir indique où se trouvera l'AWS CLI dans le PATH de votre environnement, et le troisième paramètre --install-dir est un chemin relatif à bin-dir. Cette commande garantira que tous vos chemins sont à jour.
sudo ./aws/install --bin-dir /usr/bin --install-dir /usr/bin/aws-cli --update
8. Réexécutez la commande aws --version pour vous assurer que vous utilisez la dernière version.
aws --version
Vous devriez voir la version de l'AWS CLI actuellement installée. Comme vous pouvez le voir dans la sortie ci-dessous, nous utilisons maintenant la v2.4.7 d'AWS CLI. Il s'agit de la dernière version et ne vous posera aucun problème lors de la configuration des étapes suivantes.

9. Maintenant que votre environnement est correctement configuré, il est temps pour vous de configurer le compte AWS avec lequel vous souhaitez communiquer via l'AWS CLI. Exécutez la commande suivante pour répertorier les variables d'environnement de votre compte actuellement configurées avec l'alias que vous souhaitez utiliser.
aws configure
Cela vous montrera toutes les variables d'environnement de votre compte AWS qui sont actuellement configurées. Vous devriez voir quelque chose comme ça dans la sortie ci-dessous. Vous devez configurer certains paramètres de configuration pour que l'AWS CLI puisse communiquer avec vos comptes nécessaires. Exécutez la commande ci-dessous, qui vous guidera à travers un assistant de configuration pour configurer votre compte AWS.
- ID de clé d'accès AWS [Aucun] :saisissez la clé d'accès AWS que vous avez notée précédemment.
- Clé d'accès secrète AWS [Aucune] :saisissez la clé d'accès secrète AWS que vous avez notée précédemment.
- Vous devez également spécifier le nom de la région par défaut où se trouvera votre cluster EKS. Vous devez choisir une région AWS où se trouvera votre cluster EKS souhaité et qui est la plus proche de vous. Dans ce didacticiel, nous avons choisi us-east-1 en raison de sa situation géographique proche de nous et de sa facilité d'utilisation pour les prochaines étapes du didacticiel.
- Format de sortie par défaut [Aucun] :saisissez json comme format de sortie par défaut, car il nous sera très utile pour afficher les fichiers de configuration ultérieurement.

Maintenant que vous avez configuré vos outils AWS CLI. Il est temps de configurer l'outil CLI Kubernetes nommé kubectl dans votre environnement afin que vous puissiez interagir avec votre cluster EKS.
Kubectl est l'interface de ligne de commande pour Kubernetes. Avec Kubectl, vous pouvez gérer des applications exécutées sur des clusters Kubernetes. Kubectl n'est pas installé par défaut sur les systèmes Linux et MacOS. Vous pouvez installer Kubectl sur d'autres systèmes en suivant les instructions sur le site Web de Kubernetes.
10. Exécutez la commande ci-dessous pour télécharger le binaire kubectl. Un binaire est un fichier informatique avec l'extension ".bin", qui n'est exécutable que sur certains types d'ordinateurs. C'est un moyen facile pour des types d'ordinateurs disparates de partager des fichiers. Nous utilisons le binaire kubectl car le binaire kubectl est indépendant de la plate-forme. Il fonctionnera sur n'importe quel système pouvant exécuter un système d'exploitation de type Unix, y compris Linux et Mac OS.
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.16.8/2020-04-16/bin/linux/amd64/kubectl
11. Exécutez la commande chmod ci-dessous pour rendre le binaire kubectl exécutable. La commande chmod est une commande Unix et Linux utilisée pour modifier les autorisations d'accès aux fichiers ou aux répertoires. La commande Linux chmod utilise le système numérique octal pour spécifier les autorisations de chaque utilisateur. Kubectl peut maintenant être utilisé sur votre machine locale.
chmod +x ./kubectl
12. Exécutez la commande ci-dessous pour créer un répertoire kubectl dans votre dossier $HOME/bin et copiez-y le binaire kubectl. La commande mkdir -p $HOME/bin crée un sous-répertoire bin dans votre répertoire personnel. La commande mkdir est utilisée pour créer de nouveaux répertoires ou dossiers. L'option -p indique à la commande mkdir de créer automatiquement tous les répertoires parents nécessaires pour le nouveau répertoire. Le $HOME/bin est une variable d'environnement qui stocke le chemin de votre répertoire personnel. Chaque utilisateur Linux a le répertoire $HOME/bin dans son système de fichiers. La construction &&est appelée un opérateur ET logique. Il est utilisé pour regrouper des commandes afin que plusieurs commandes puissent être exécutées à la fois. La construction &&n'est pas nécessaire pour que cette commande fonctionne, mais elle est là en tant que meilleure pratique.
La commande cp ./kubectl $HOME/bin/kubectl copie le fichier binaire kubectl local dans votre répertoire kubectl et renomme le fichier en kubectl. Enfin, la commande export fait ce qu'elle dit - elle exporte une variable d'environnement dans la mémoire du shell afin qu'elle puisse être utilisée par n'importe quel programme exécuté à partir de ce shell. Dans notre cas, nous devons indiquer à kubectl où se trouve notre répertoire kubectl afin qu'il puisse trouver le binaire kubectl.
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin
13. Exécutez la commande kubectl version ci-dessous pour vérifier que kubectl est correctement installé. La commande kubectl version --short --client génère une version abrégée de la version kubectl dans une réponse de l'API REST Kubernetes bien formatée et lisible par l'homme. L'option --client permet à kubectl d'imprimer la version formatée de la réponse de l'API REST de Kubernetes, qui est cohérente d'une version à l'autre.
L'option --short indique à kubectl de fournir des informations de base sous une forme compacte avec une décimale pour les flottants et un format d'heure abrégé identique à --format. Vous devriez voir une sortie comme celle ci-dessous. Cette sortie nous indique que nous avons installé avec succès kubectl et qu'il utilise la version correcte.

La dernière chose que vous devez faire dans cette section est de configurer l'outil eksctl cli pour utiliser votre cluster Amazon EKS. L'outil eksctl cli est une interface de ligne de commande qui peut gérer les clusters Amazon EKS. Il peut générer des informations d'identification de cluster, mettre à jour la spécification de cluster, créer ou supprimer des nœuds de travail et effectuer de nombreuses autres tâches.
14. Exécutez les commandes suivantes pour installer l'outil eksctl cli et vérifier sa version.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp && sudo mv /tmp/eksctl /usr/bin
eksctl version

Provisionner un cluster EKS
Maintenant que vous avez votre EC2 et les outils AWS CLI, vous pouvez maintenant provisionner votre premier cluster EKS.
1. Exécutez la commande eksctl create cluster ci-dessous pour provisionner un cluster nommé dev dans la région us-east-1 avec un maître et trois nœuds principaux.
eksctl create cluster --name dev --version 1.21 --region us-east-1 --nodegroup-name standard-workers --node-type t3.micro --nodes 3 --nodes-min 1 --nodes-max 4 --managed
La commande eksctl create cluster crée un cluster EKS dans la région us-east-1 en utilisant les valeurs par défaut recommandées par Amazon pour cette configuration spécifique et transmet tous les arguments entre guillemets ( " ) ou sous forme de variables ( ${ } ) en conséquence.
Le paramètre de nom est utilisé pour définir le nom de ce cluster EKS et c'est juste une étiquette conviviale pour votre commodité. version est la version que vous souhaitez que le cluster utilise, pour cet exemple, nous nous en tiendrons à Kubernetes v1.21.2 mais n'hésitez pas à explorer également d'autres options.
nodegroup-name est le nom d'un groupe de nœuds que ce cluster doit utiliser pour gérer les nœuds de travail. Dans cet exemple, vous resterez simple et utiliserez simplement des nœuds de calcul standard, ce qui signifie que vos nœuds de calcul auront un processeur virtuel et 3 Go de mémoire par défaut.
nodes est le nombre total de noeuds worker principaux que vous souhaitez dans votre cluster. Dans cet exemple, trois nœuds sont demandés. nodes-min et nodes-max contrôlent le nombre minimum et maximum de nœuds autorisés dans votre cluster. Dans cet exemple, au moins un mais pas plus de quatre nœuds de travail seront créés.
2. Vous pouvez accéder à votre console CloudFormation pour surveiller la progression du provisionnement.
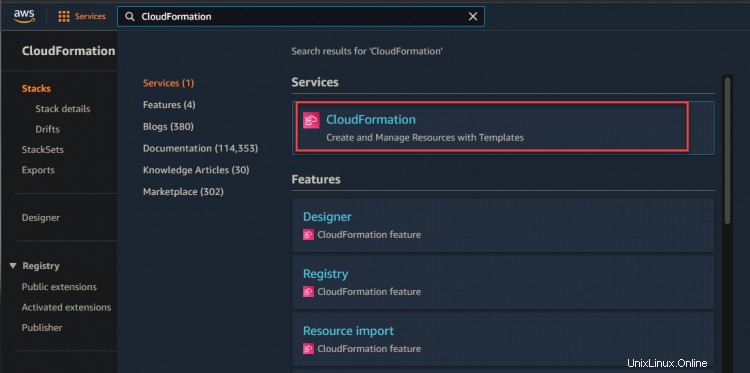
Comme indiqué ci-dessous, vous pouvez voir que votre pile de développement est en cours de création.

3. Cliquez sur le lien hypertexte dev stack> Événement. Vous verrez une liste d'événements liés au processus de création. Attendez que le processus de provisionnement soit terminé - cela peut prendre jusqu'à 15 minutes selon votre situation spécifique - et vérifiez l'état de la pile dans la console CloudFormation.

4. Après avoir attendu que la pile ait terminé le provisionnement, accédez à votre console CloudFormation, vous verrez l'état de votre pile de développement de CREATE_COMPLETE.

Maintenant, accédez à votre console EC2. Vous verrez un nœud maître et trois nœuds principaux dans le tableau de bord EC2. Cette sortie confirme que vous avez correctement configuré le cluster EKS.

5. Exécutez la commande eksctl ci-dessous pour obtenir les détails du cluster de développement, tels que l'ID de cluster et la région.
eksctl get cluster

6. Exécutez la commande aws eks update ci-dessous pour obtenir les informations d'identification du nœud de travail distant. Cette commande doit être exécutée sur n'importe quel ordinateur que vous souhaitez connecter au cluster. Il télécharge les informations d'identification pour votre kubectl afin d'accéder à distance à EKS Kubernetes Cluster, sans utiliser les clés d'accès AWS Access.
aws eks update-kubeconfig --name dev --region us-east-1

Déploiement de votre application sur le cluster EKS
Maintenant que votre cluster EKS est provisionné. Déployons votre première application sur votre cluster EKS. Dans cette section, vous apprendrez à déployer un serveur Web nginx avec un équilibreur de charge en tant qu'exemple d'application.
1. Exécutez la commande ci-dessous pour installer git sur votre système. Vous aurez besoin de git pour cloner le code du serveur Web nginx à partir de GitHub.
sudo yum install -y git
2. Exécutez la commande git clone ci-dessous pour cloner le code du serveur Web nginx de github vers votre répertoire actuel.
git clone https://github.com/ata-aws-iam/htf-elk.git
3. Exécutez la commande cd htf-elk pour remplacer le répertoire de travail par le répertoire des fichiers de configuration nginx.
cd htf-elk
4. Exécutez la commande ls pour répertorier les fichiers du répertoire en cours.
ls
Vous verrez les fichiers suivants présents dans votre répertoire nginx.

5. Exécutez la commande cat ci-dessous pour ouvrir le fichier nginx-deployment.yaml et vous verrez le contenu suivant présent dans ce fichier.
cat nginx-deployment.yaml

- apiVersion :apps/v1 est l'API principale de Kubernetes
- kind :le déploiement est le type de ressource qui sera créé pour ce fichier. Dans un déploiement, un pod est créé par conteneur.
- métadonnées :spécifie les valeurs de métadonnées à utiliser lors de la création d'un objet
- name :nginx-deployment est le nom ou l'étiquette de ce déploiement. S'il n'a pas de valeur, le nom du déploiement est tiré du nom du répertoire.
- labels :fournit des étiquettes pour l'application. Dans ce cas, il sera utilisé pour le routage des services via Elastic Load Balancing (ELB)
- env :dev décrit une variable d'environnement définie par une valeur de chaîne. C'est ainsi que vous pouvez fournir des données de configuration dynamiques à votre conteneur.
- spec :est l'endroit où vous définissez le nombre de répliques à créer. Vous pouvez spécifier les propriétés sur lesquelles vous souhaitez que chaque réplique soit basée.
- réplicas :3 créera trois réplicants de ce pod sur votre cluster. Ceux-ci seront distribués sur les noeuds worker disponibles qui correspondent au sélecteur d'étiquettes .
- containerPort :80 mappera un port du conteneur à un port sur l'hôte. Dans ce cas, il mappera le port 80 sur le conteneur au port 30000 de votre machine locale.
6. Exécutez la commande cat ci-dessous pour ouvrir le fichier de service nginx-svc.yaml. Vous verrez le contenu suivant présent dans ce fichier.
cat nginx-svc.yaml
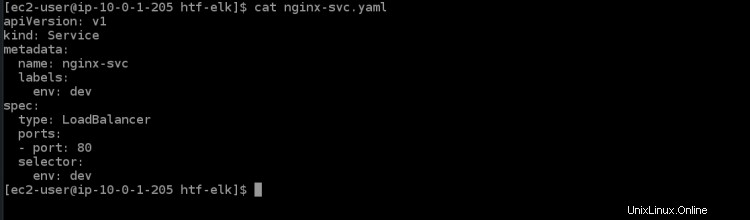
7. Exécutez la commande kubectl apply ci-dessous pour créer le service nginx dans votre cluster Kubernetes. Il faudra quelques minutes au cluster EKS pour provisionner ELB pour ce service.
kubectl apply -f ./nginx-svc.yaml

8. Exécutez le service kubectl get ci-dessous pour obtenir les détails du service nginx que vous venez de créer.
kubectl get service
Vous obtiendrez la sortie suivante. ClusterIP est l'adresse IP kubernetes interne attribuée à ce service. Le nom LoadBalancer ELB est un identifiant unique pour ce service. Il créera automatiquement un ELB sur AWS et fournira un point de terminaison public pour ce service qui peut être atteint par les services de votre choix tels que le navigateur Web (nom de domaine) ou les clients API. Il est accessible via une adresse IP de votre choix.
L'équilibreur de charge ELB avec le nom a6f8c3cf0fe3a468d8828db6059ef05e-953361268.us-east-1.elb.amazonaws.com a le port 32406, qui sera mappé au port de conteneur 80. Notez le nom d'hôte DNS de l'équilibreur de charge ELB à partir de la sortie ; vous en aurez besoin pour accéder au service plus tard.

9. Exécutez la commande kubectl apply ci-dessous pour appliquer le déploiement à votre cluster.
kubectl apply -f ./nginx-deployment.yaml

10. Exécutez le déploiement kubectl get pour obtenir les détails du déploiement nginx que vous venez de créer.
kubectl get deployment

11. Exécutez la commande ci-dessous pour accéder à votre application nginx via l'équilibreur de charge. Vous verrez la page d'accueil de nginx dans votre terminal/console, qui confirme que votre application nginx fonctionne comme prévu. Remplacez
curl "<LOAD_BALANCER_DNS_HOSTNAME>"
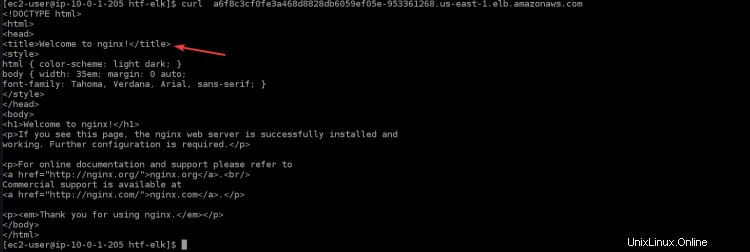
12. Vous pouvez également accéder à votre application nginx via le navigateur en copiant et en collant le nom d'hôte DNS de l'équilibreur de charge dans le navigateur.
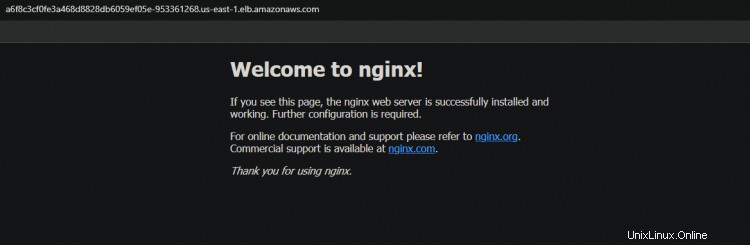
Vérification de la fonctionnalité hautement disponible (HA) pour votre cluster
Maintenant que vous avez créé votre cluster avec succès, vous pouvez tester la fonctionnalité HA pour vous assurer qu'elle fonctionne comme prévu.
Kubernetes prend en charge les déploiements multi-nœuds avec l'utilisation de contrôleurs spéciaux qui fonctionnent en tandem pour créer et gérer des pods ou des services répliqués. Certains de ces contrôleurs sont Deployments, ReplicationController, Job et DaemonSet.
Un contrôleur de déploiement est utilisé pour contrôler la réplication au niveau du pod ou du service. Lorsque votre pod est à court de ressources, il supprimera tous les pods de ce contrôleur de réplication (sauf celui qui s'exécute sur le nœud maître) et créera de nouvelles répliques de ce pod. Cela vous aidera à obtenir une disponibilité très élevée de vos applications.
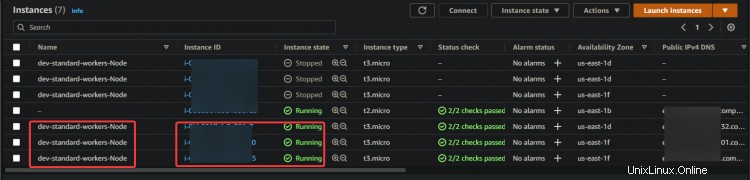
1. Accédez à votre tableau de bord EC2 et arrêtez les trois nœuds de travail.

2. Exécutez la commande ci-dessous pour vérifier l'état de vos pods. Vous obtiendrez différents statuts :Résiliation , En cours d'exécution , et En attente pour tous vos pods. Parce qu'une fois que vous avez arrêté tous les nœuds de travail, EKS essaiera de redémarrer tous les nœuds de travail et les pods à nouveau. Vous pouvez également voir de nouveaux nœuds, que vous pouvez identifier par leur âge (50 ans ).
kubectl get pod

Le démarrage de la nouvelle instance EC2 et des pods prend un certain temps. Une fois que tous les nœuds de travail sont démarrés, vous verrez toutes les nouvelles instances EC2 revenir à Running statut.
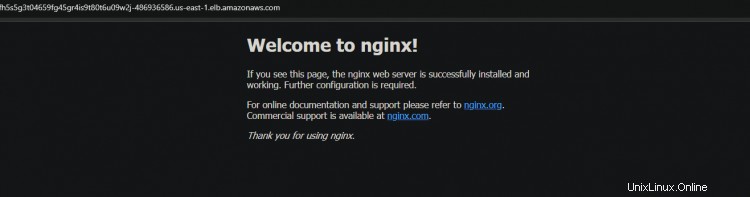
3. Réexécutez le service kubectl get. Vous pouvez voir qu'ESK va créer un nouveau service nginx et un nouveau nom DNS pour votre équilibreur de charge.
kubectl get service

Copiez et collez le nouveau DNS dans votre navigateur. Vous recevrez à nouveau l'accueil de la page Nginx. Ce résultat confirme que votre haute disponibilité fonctionne comme prévu.
Conclusion
Dans cet article, vous avez appris à configurer votre cluster EKS. Vous avez également vérifié que la fonctionnalité hautement disponible fonctionne en arrêtant tous vos nœuds de travail et en vérifiant l'état de vos pods. Vous devriez maintenant pouvoir créer et gérer des clusters EKS à l'aide de kubectl.