Le mécanisme de sauvegarde dans Elasticsearch s'appelle Snapshot. Un instantané est une sauvegarde effectuée à partir d'un cluster Elasticsearch en cours d'exécution. Il n'est pas nécessaire de démonter le cluster, ce qui permet d'éviter les fenêtres de maintenance des applications. Un instantané d'un index individuel ou de l'ensemble du cluster peut être pris et stocké dans un référentiel sur un système de fichiers partagé.
Les instantanés dans Elasticsearch sont pris de manière incrémentielle. Cela signifie que lorsqu'il crée un instantané d'un index, Elasticsearch évite de copier les données déjà stockées dans le cadre d'un instantané antérieur du même index. Par conséquent, il peut être efficace de prendre régulièrement des instantanés du cluster.
De la même manière que nous pouvons effectuer une sauvegarde du cluster en cours d'exécution, nous pouvons également restaurer un instantané dans un cluster en cours d'exécution. Lorsque nous restaurons un index, nous pouvons même modifier le nom de l'index restauré ainsi que certains de ses paramètres.
Pour effectuer des sauvegardes, nous devons enregistrer un référentiel d'instantanés avant de pouvoir effectuer les opérations d'instantané et de restauration. Afin d'enregistrer le référentiel de système de fichiers partagé pour le cluster, il est nécessaire de monter le même système de fichiers partagé au même emplacement sur tous les nœuds maîtres et de données. Cet emplacement doit être enregistré dans le fichier de configuration sur tous les nœuds maîtres et de données.
Dans cet article, nous allons vérifier le référentiel partagé NFS et voir les étapes pour prendre un instantané et le restaurer.
Pré-requis
- Répertoire partagé NFS disponible et monté sur les 3 nœuds d'Elasticsearch au même emplacement
- Cluster Elasticsearch de 3 nœuds sur 3 serveurs Ubuntu.
Ce que nous allons faire
- Vérifiez la configuration du serveur NFS.
- Vérifier la configuration du cluster Elasticsearch
- Enregistrer un référentiel pour effectuer des sauvegardes.
- Effectuer une sauvegarde et une restauration.
Vérifiez la configuration du serveur/client NFS.
Dans cet article, nous ne parlerons pas de la configuration NFS car elle n'entre pas dans le cadre de cet article. Mais pour sauvegarder Elasticsearch, nous aurions besoin de la configuration suivante.
es-node-1(10.11.10.61) : NFS Client
es-node-2(10.11.10.62) : NFS Client
es-node-3(10.11.10.63) : NFS Client
NFS Server(10.11.10.64) : NFS Server
Ici,
Le serveur NFS a partagé son "/home/ubuntu/shared/" répertoire avec les nœuds Elasticsearch.
Chaque Elasticsearch a son répertoire local "/home/ubuntu/mounted" monté sur le répertoire partagé de NFS "/home/ubuntu/shared/" . Nous devons nous assurer que la propriété de tous les répertoires appartient au même utilisateur avec lequel nous lancerions Elasticsearch.
Une fois que nous avons cette configuration en place, nous pouvons continuer.
Vérifier la configuration du cluster Elasticsearch
Effectuez les configurations suivantes pour configurer Elasticsearch afin qu'il fonctionne en mode Cluster :
Ici, si vous avez configuré un cluster Elasticsearch, vous devez être conscient de la configuration suivante.
La seule configuration que nous devons effectuer pour séparer Elasticsearch Cluster Backup de la configuration de cluster Elasticsearch existante est "path.repo :["/home/ubuntu/mounted"] " :
vim config/elasticsearch.yml
path.repo: ["/home/ubuntu/mounted"]
Gardez ce même sur chaque nœud.
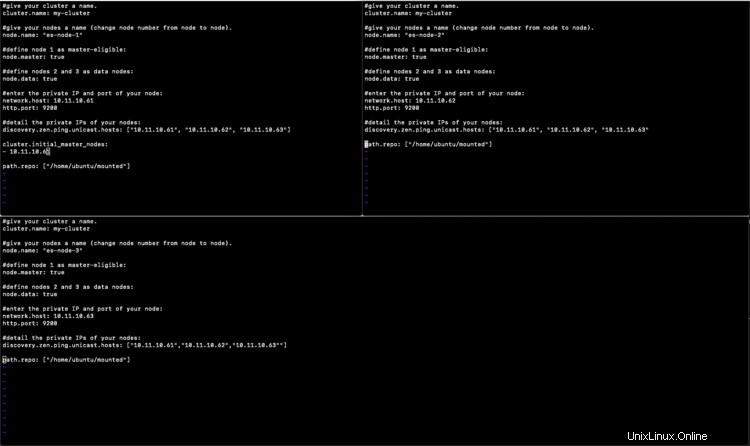
Configuration sur Node1
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-1"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.61
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"]
cluster.initial_master_nodes:
- 10.11.10.61
path.repo: ["/home/ubuntu/mounted"]
Configuration sur Node2
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-2"
#define node 2 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.62
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"
path.repo: ["/home/ubuntu/mounted"]
Configuration sur Node3
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-3"
#define node 3 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.63
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61","10.11.10.62","10.11.10.63""]
path.repo: ["/home/ubuntu/mounted"]
Une fois que vous avez toute cette configuration en place, démarrez tous les nœuds Elasticsearch, en démarrant d'abord le maître initial.
Enregistrer un référentiel pour effectuer des sauvegardes
Vérifiez les référentiels existants à l'aide de la commande suivante.
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Si nous obtenons une réponse vide, cela indique que nous n'avons pas encore configuré de référentiels
Pour configurer un référentiel, exécutez la commande suivante.
curl -XPUT 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup' -d {
"type": "fs",
"settings": {
"location": "/home/ubuntu/mounted",
"compress": true
}
}' Ici, "my_backup" dans la commande ci-dessus est le nom du référentiel.
Nous pouvons vérifier les référentiels enregistrés à l'aide de la commande suivante
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Sauvegarde et restauration d'un cluster Elasticsearch
Effectuer une sauvegarde
Une fois que nous avons créé un référentiel, nous sommes prêts à effectuer une sauvegarde.
Utilisez la commande suivante pour effectuer une sauvegarde nommée "snapshot_name"
curl -XPUT "https://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name?wait_for_completion=true"
Restaurer une sauvegarde
L'instantané que nous avons pris peut être restauré à l'aide de la commande suivante.
Utilisez la commande suivante pour restaurer la sauvegarde nommée "snapshot_name"
curl -XPOST "http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name/_restore?wait_for_completion=true"
Conclusion
Dans cet article, nous avons vu les étapes pour enregistrer un dépôt et faire une sauvegarde et le restaurer.