Présentation
MongoDB est un programme de base de données NoSQL basé sur des documents à usage général. Comme avec d'autres systèmes de gestion de bases de données non relationnelles, MongoDB se concentre sur l'évolutivité et la rapidité des requêtes.
Kubernetes est en synergie avec MongoDB pour créer des déploiements de bases de données hautement évolutifs et portables. Ces déploiements sont utiles pour travailler avec une grande quantité de données et des charges élevées.
Ce didacticiel vous apprendra à déployer MongoDB sur Kubernetes. Le guide comprend des étapes pour exécuter une instance MongoDB autonome et un jeu de réplicas.

Exigences
- Un cluster Kubernetes avec kubectl.
- Accès administrateur à votre système.
Déployer une instance MongoDB autonome
MongoDB peut être déployé sur Kubernetes en tant qu'instance autonome. Ce déploiement n'est pas adapté à une utilisation en production, mais il convient aux tests et à certains aspects du développement.
Suivez les étapes ci-dessous pour déployer une instance MongoDB autonome.
Étape 1 :Étiquetez le nœud
Étiquetez le nœud qui sera utilisé pour le déploiement de MongoDB. L'étiquette est utilisée plus tard pour attribuer des pods à un nœud spécifique.
Pour ce faire :
1. Répertoriez les nœuds de votre cluster :
kubectl get nodes2. Choisissez le nœud de déploiement dans la liste de la sortie de la commande.

3. Utilisez kubectl pour étiqueter le nœud avec une paire clé-valeur.
kubectl label nodes <node> <key>=<value>La sortie confirme que l'étiquette a été ajoutée avec succès.

Étape 2 :Créer une classe de stockage
StorageClass aide les pods à provisionner les revendications de volume persistantes sur le nœud. Pour créer une StorageClass :
1. Utilisez un éditeur de texte pour créer un fichier YAML pour stocker la configuration de la classe de stockage.
nano StorageClass.yaml
2. Spécifiez votre configuration de classe de stockage dans le fichier. L'exemple ci-dessous définit le mongodb-storageclass :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: mongodb-storageclass
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true3. Enregistrez les modifications et quittez l'éditeur.
Étape 3 :Créer un stockage persistant
Provisionnez le stockage pour le déploiement MongoDB en créant un volume persistant et une revendication de volume persistant :
1. Créez un fichier YAML pour la configuration du volume persistant.
nano PersistentVolume.yaml
2. Dans le fichier, allouez le stockage qui appartient à la classe de stockage définie à l'étape précédente. Spécifiez le nœud qui sera utilisé dans le déploiement du pod dans nodeAffinity section. Le nœud est identifié à l'aide du libellé créé à l'étape 1 .
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
storage: 2Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: mongodb-storageclass
local:
path: /mnt/data
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: size
operator: In
values:
- large3. Créez un autre YAML pour la configuration de la demande de volume persistant :
nano PersistentVolumeClaim.yaml
4. Définissez la revendication nommée mongodb-pvc et demandez à Kubernetes de réclamer les volumes appartenant à mongodb-storageclass .
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mongodb-pvc
spec:
storageClassName: mongodb-storageclass
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 1GiÉtape 4 :Créer une ConfigMap
Le fichier ConfigMap stocke les informations de configuration non chiffrées utilisées par les pods.
1. Créez un fichier YAML pour stocker la configuration du déploiement :
nano ConfigMap.yaml2. Utilisez le fichier pour stocker des informations sur les chemins système, les utilisateurs et les rôles. Voici un exemple de fichier ConfigMap :
apiVersion: v1
kind: ConfigMap
metadata:
name: mongodb-configmap
data:
mongo.conf: |
storage:
dbPath: /data/db
ensure-users.js: |
const targetDbStr = 'test';
const rootUser = cat('/etc/k8-test/admin/MONGO_ROOT_USERNAME');
const rootPass = cat('/etc/k8-test/admin/MONGO_ROOT_PASSWORD');
const usersStr = cat('/etc/k8-test/MONGO_USERS_LIST');
const adminDb = db.getSiblingDB('admin');
adminDb.auth(rootUser, rootPass);
print('Successfully authenticated admin user');
const targetDb = db.getSiblingDB(targetDbStr);
const customRoles = adminDb
.getRoles({rolesInfo: 1, showBuiltinRoles: false})
.map(role => role.role)
.filter(Boolean);
usersStr
.trim()
.split(';')
.map(s => s.split(':'))
.forEach(user => {
const username = user[0];
const rolesStr = user[1];
const password = user[2];
if (!rolesStr || !password) {
return;
}
const roles = rolesStr.split(',');
const userDoc = {
user: username,
pwd: password,
};
userDoc.roles = roles.map(role => {
if (!~customRoles.indexOf(role)) {
return role;
}
return {role: role, db: 'admin'};
});
try {
targetDb.createUser(userDoc);
} catch (err) {
if (!~err.message.toLowerCase().indexOf('duplicate')) {
throw err;
}
}
});Étape 5 :Créer un StatefulSet
StatefulSet est un contrôleur Kubernetes utilisé pour déployer des applications avec état. Les pods d'application avec état nécessitent des identités uniques, car ils communiquent avec d'autres pods.
Pour créer un StatefulSet :
1. Utilisez un éditeur de texte pour créer un fichier YAML :
nano StatefulSet.yaml
2. Insérez les informations de déploiement dans le fichier, y compris l'image MongoDB Docker à utiliser. Le fichier référence également le ConfigMap créé précédemment et PersistentVolumeClaim :
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb-test
spec:
serviceName: mongodb-test
replicas: 1
selector:
matchLabels:
app: database
template:
metadata:
labels:
app: database
selector: mongodb-test
spec:
containers:
- name: mongodb-test
image: mongo:4.0.8
env:
- name: MONGO_INITDB_ROOT_USERNAME_FILE
value: /etc/k8-test/admin/MONGO_ROOT_USERNAME
- name: MONGO_INITDB_ROOT_PASSWORD_FILE
value: /etc/k8-test/admin/MONGO_ROOT_PASSWORD
volumeMounts:
- name: k8-test
mountPath: /etc/k8-test
readOnly: true
- name: mongodb-scripts
mountPath: /docker-entrypoint-initdb.d
readOnly: true
- name: mongodb-configmap
mountPath: /config
readOnly: true
- name: mongodb-data
mountPath: /data/db
nodeSelector:
size: large
volumes:
- name: k8-test
secret:
secretName: mongodb-secret
items:
- key: MONGO_ROOT_USERNAME
path: admin/MONGO_ROOT_USERNAME
mode: 0444
- key: MONGO_ROOT_PASSWORD
path: admin/MONGO_ROOT_PASSWORD
mode: 0444
- key: MONGO_USERNAME
path: MONGO_USERNAME
mode: 0444
- key: MONGO_PASSWORD
path: MONGO_PASSWORD
mode: 0444
- key: MONGO_USERS_LIST
path: MONGO_USERS_LIST
mode: 0444
- name: mongodb-scripts
configMap:
name: mongodb-configmap
items:
- key: ensure-users.js
path: ensure-users.js
- name: mongodb-configmap
configMap:
name: mongodb-configmap
items:
- key: mongo.conf
path: mongo.conf
- name: mongodb-data
persistentVolumeClaim:
claimName: mongodb-pvcÉtape 6 :Créez un secret
L'objet Secret est utilisé pour stocker des informations sensibles sur le déploiement.
1. Créez un YAML secret avec votre éditeur de texte.
nano Secret.yaml2. Fournissez des informations pour accéder à la base de données MongoDB.
apiVersion: v1
kind: Secret
metadata:
name: mongodb-secret
type: Opaque
data:
MONGO_ROOT_USERNAME: YWRtaW4K
MONGO_ROOT_PASSWORD: cGFzc3dvcmQK
MONGO_USERNAME: dGVzdAo=
MONGO_PASSWORD: cGFzc3dvcmQK
MONGO_USERS_LIST: dGVzdDpkYkFkbWluLHJlYWRXcml0ZTpwYXNzd29yZAo=3. Enregistrez les modifications et quittez.
Étape 7 :Créer un service MongoDB
Pour créer un service MongoDB :
1. Créez un objet de service sans tête.
nano Service.yamlLe service sans tête permet aux utilisateurs de se connecter directement aux pods.
2. Ajoutez le nom et la définition du service dans le fichier YAML.
apiVersion: v1
kind: Service
metadata:
name: mongodb-test
labels:
app: database
spec:
clusterIP: None
selector:
app: database3. Enregistrez les modifications et quittez le fichier.
Étape 8 :Appliquer la configuration MongoDB avec Kustomize
Utilisez Kustomize pour appliquer facilement les fichiers de configuration MongoDB :
1. Créez un kustomization.yaml fichier :
nano kustomization.yaml
2. Dans les resources , répertoriez tous les fichiers YAML créés lors des étapes précédentes :
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ConfigMap.yaml
- PersistentVolumeClaim.yaml
- PersistentVolume.yaml
- Secret.yaml
- Service.yaml
- StatefulSet.yaml
- StorageClass.yaml
Enregistrez le fichier dans le même répertoire que les autres fichiers.
3. Déployez MongoDB avec la commande suivante :
kubectl apply -k .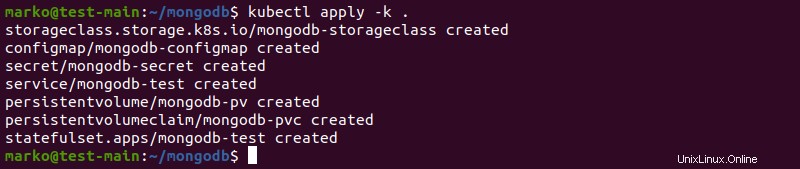
4. Utilisez kubectl pour vérifier si le pod est prêt.
kubectl get pod
Lorsque le pod affiche 1/1 dans le READY colonne, passez à l'étape suivante.

Étape 9 :Connectez-vous à l'instance autonome de MongoDB
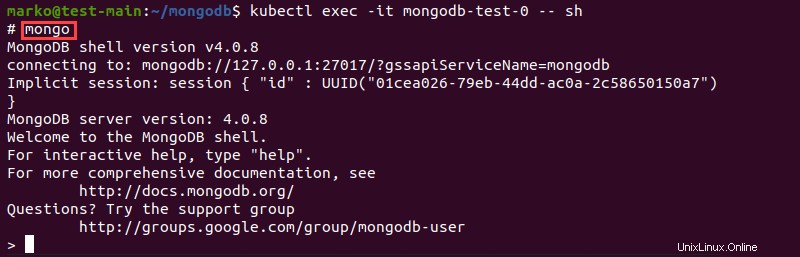
1. Connectez-vous au pod MongoDB à l'aide de la commande kubectl suivante :
kubectl exec -it mongodb-test-0 -- sh
2. Lorsque le # s'affiche, saisissez :
mongoChargements du shell MongoDB.
3. Passez à la base de données de test :
use test4. Authentifiez-vous avec la commande suivante :
db.auth('[username]','[password]')
Numéro 1 dans la sortie confirme l'authentification réussie.

Déployer un ReplicaSet
Déploiement de MongoDB en tant que ReplicaSet garantit que le nombre spécifié de pods s'exécutent à un moment donné. Les déploiements de ReplicaSet sont recommandés pour les environnements de production.
Étape 1 :Configurer le contrôle d'accès basé sur les rôles (RBAC)
L'activation du contrôle d'accès basé sur les rôles est l'une des meilleures pratiques de sécurité de Kubernetes. RBAC garantit qu'aucun utilisateur ne dispose de plus d'autorisations que nécessaire.
Pour configurer RBAC :
1. Créez un fichier YAML avec un éditeur de texte.
nano rbac.yaml2. Fournissez des règles d'accès pour votre déploiement MongoDB. L'exemple ci-dessous montre un fichier RBAC YAML :
apiVersion: v1
kind: ServiceAccount
metadata:
name: mongo-account
namespace: default
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: mongo-role
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["*"]
- apiGroups: [""]
resources: ["deployments"]
verbs: ["list", "watch"]
- apiGroups: [""]
resources: ["services"]
verbs: ["*"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["get","list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: mongo_role_binding
subjects:
- kind: ServiceAccount
name: mongo-account
namespace: default
roleRef:
kind: ClusterRole
name: mongo-role
apiGroup: rbac.authorization.k8s.io3. Enregistrez le fichier et appliquez-le avec kubectl :
kubectl apply -f rbac.yamlÉtape 2 :Créer un déploiement StatefulSet
1. Créez un YAML de déploiement StatefulSet :
nano StatefulSet.yaml2. Spécifiez le nombre de répliques dans le fichier, l'image Docker MongoDB à utiliser et fournissez un modèle de demande de volume pour la fourniture de volume dynamique :
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mongodb-replica
namespace: default
spec:
serviceName: mongo
replicas: 2
selector:
matchLabels:
app: mongo
template:
metadata:
labels:
app: mongo
selector: mongo
spec:
terminationGracePeriodSeconds: 30
serviceAccount: mongo-account
containers:
- name: mongodb
image: docker.io/mongo:4.2
env:
command: ["/bin/sh"]
args: ["-c", "mongod --replSet=rs0 --bind_ip_all"]
resources:
limits:
cpu: 1
memory: 1500Mi
requests:
cpu: 1
memory: 1000Mi
ports:
- name: mongo-port
containerPort: 27017
volumeMounts:
- name: mongo-data
mountPath: /data/db
volumeClaimTemplates:
- metadata:
name: mongo-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi3. Enregistrez le fichier et utilisez kubectl apply pour créer un déploiement :
kubectl apply -f StatefulSet.yamlÉtape 3 :Créer un service sans écran
Pour créer un service sans tête :
1. Créez un fichier YAML de service :
nano Service.yaml2. Définissez un service permettant une communication directe avec les pods :
apiVersion: v1
kind: Service
metadata:
name: mongo
namespace: default
labels:
name: mongo
spec:
ports:
- port: 27017
targetPort: 27017
clusterIP: None
selector:
app: mongo3. Appliquez le YAML avec kubectl.
kubectl apply -f Service.yamlÉtape 4 :Configurer l'hôte de réplication
Pour configurer la réplication de pod :
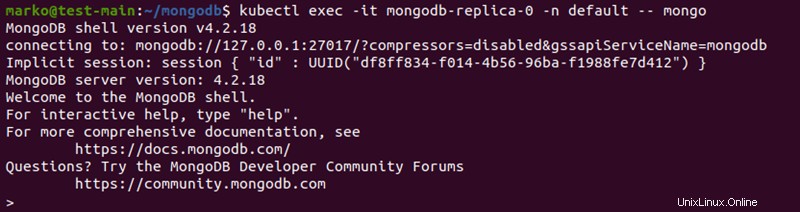
1. Entrez dans le pod à l'aide de kubectl exec :
kubectl exec -it mongodb-replica-0 -n default -- mongoLe message de bienvenue du shell MongoDB s'affiche.
2. Lancez la réplication en tapant la commande suivante à l'invite du shell MongoDB :
rs.initiate()
Le "ok" : 1 indique que l'initiation a réussi.

3. Définissez la variable appelée cfg . La variable exécute rs.conf() .
var cfg = rs.conf()4. Utilisez la variable pour ajouter le serveur principal à la configuration :
cfg.members[0].host="mongodb-replica-0.mongo:27017"La sortie affiche le nom du serveur principal.

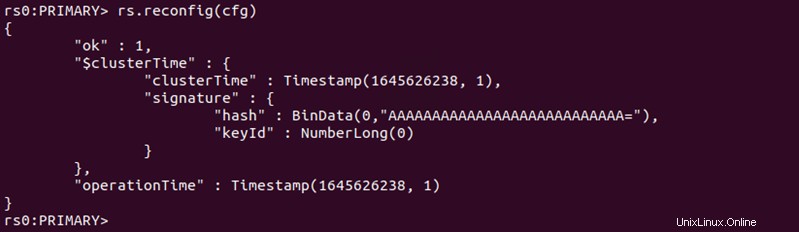
5. Confirmez la configuration en exécutant la commande suivante :
rs.reconfig(cfg)
Le "ok" : 1 confirme que la configuration a réussi.
6. Utilisez le rs.add() commande pour ajouter un autre pod à la configuration.
rs.add("mongodb-replica-1.mongo:27017")La sortie indique que le réplica a été ajouté.
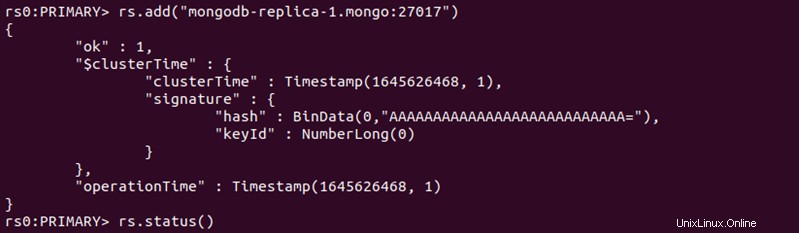
7. Vérifiez l'état du système en tapant :
rs.status()
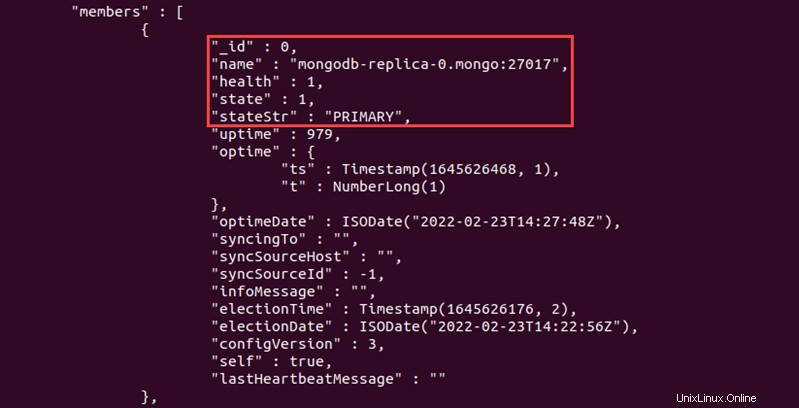
Les "members" La section doit afficher deux répliques. Le réplica principal est répertorié en haut de la sortie.
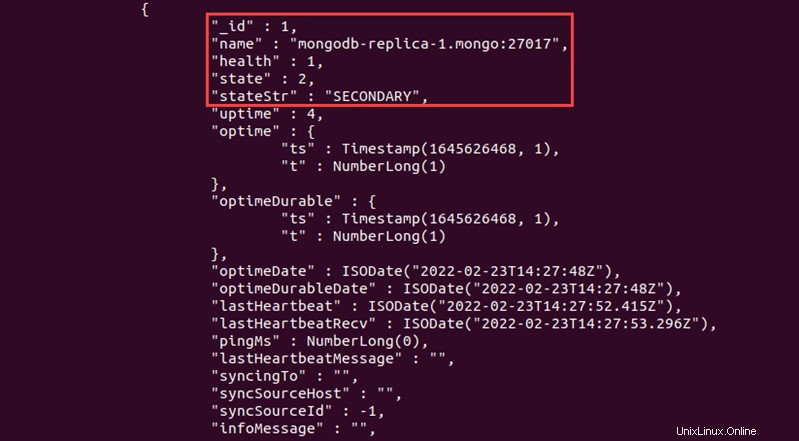
Le réplica secondaire se trouve sous le réplica principal.
Le déploiement ReplicaSet de MongoDB est configuré et prêt à fonctionner.