Les administrateurs système disposent de nombreux outils pour afficher et gérer les processus en cours d'exécution. Pour moi, ceux-ci étaient principalement top , au sommet , et htop . Il y a quelques années, j'ai découvert Glances, un outil qui affiche des informations qu'aucun de mes autres favoris n'affiche. Tous ces outils surveillent l'utilisation du processeur et de la mémoire, et la plupart d'entre eux répertorient des informations sur les processus en cours d'exécution (à tout le moins). Cependant, Glances surveille également les E/S du système de fichiers, les E/S réseau et les lectures de capteurs qui peuvent afficher les températures du processeur et d'autres matériels, ainsi que la vitesse des ventilateurs et l'utilisation du disque par périphérique matériel et volume logique.
Regards
J'ai mentionné Glances dans mon article 4 outils open source pour la surveillance du système Linux , mais je vais approfondir cela dans cet article. Si vous avez lu mon article précédent, certaines de ces informations vous sont peut-être familières, mais vous devriez également trouver de nouvelles choses ici.
Glances est multiplateforme car il est écrit en Python. Il peut être installé sur Windows et d'autres hôtes avec les versions actuelles de Python installées. La plupart des distributions Linux (Fedora dans mon cas) ont Glances dans leurs référentiels. Si ce n'est pas le cas, ou si vous utilisez un système d'exploitation différent (tel que Windows), ou si vous souhaitez simplement l'obtenir directement à partir de la source, vous pouvez trouver des instructions pour le télécharger et l'installer dans le dépôt GitHub de Glances.
Je suggère d'exécuter Glances sur une machine de test pendant que vous essayez les commandes de cet article. Si vous n'avez pas d'hôte physique disponible pour les tests, vous pouvez explorer Glances sur une machine virtuelle (VM), mais vous ne verrez pas la section des capteurs matériels ; après tout, une machine virtuelle n'a pas de matériel réel.
Pour démarrer Glances sur un hôte Linux, ouvrez une session de terminal et entrez la commande glances .
Glances comporte trois sections principales - Résumé, Processus et Alertes - ainsi qu'une barre latérale. Je vais les explorer et d'autres détails pour utiliser Glances maintenant.
Section Résumé
Dans ses premières lignes, la section Résumé de Glances contient une grande partie des mêmes informations que celles que vous trouverez dans les sections de résumé des autres moniteurs. Si vous disposez de suffisamment d'espace horizontal dans votre terminal, Glances peut afficher l'utilisation du processeur avec un graphique à barres et un indicateur numérique. sinon il n'affichera que le nombre.
J'aime mieux la section Résumé de Glances que celles des autres moniteurs (comme top ); Je pense qu'il fournit les bonnes informations dans un format facilement compréhensible.
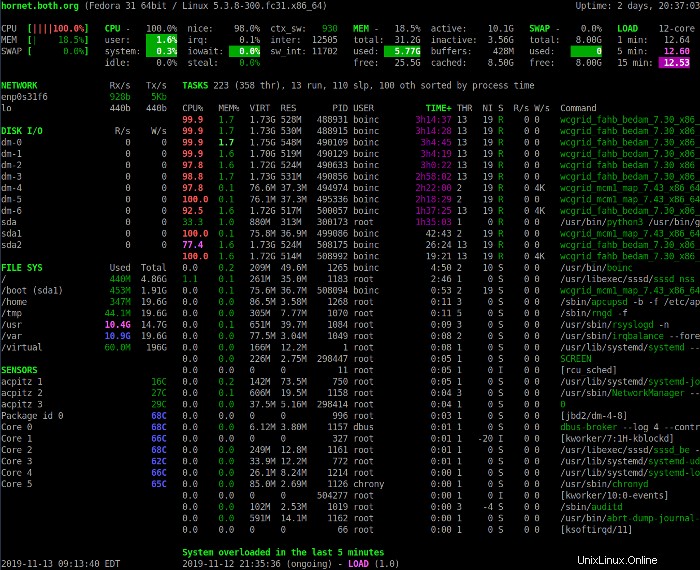
La section Résumé ci-dessus fournit un aperçu de l'état du système. La première ligne affiche le nom d'hôte, la distribution Linux, la version du noyau et la disponibilité du système.
Les quatre lignes suivantes affichent les statistiques d'UC, d'utilisation de la mémoire, d'échange et de charge. La colonne de gauche affiche les pourcentages d'UC, de mémoire et d'espace d'échange utilisés. Il affiche également les statistiques combinées de tous les processeurs présents dans le système.
Appuyez sur le 1 pour basculer entre l'affichage consolidé de l'utilisation du processeur et l'affichage des processeurs individuels. L'image suivante montre l'affichage Coups d'œil avec les statistiques individuelles du processeur.
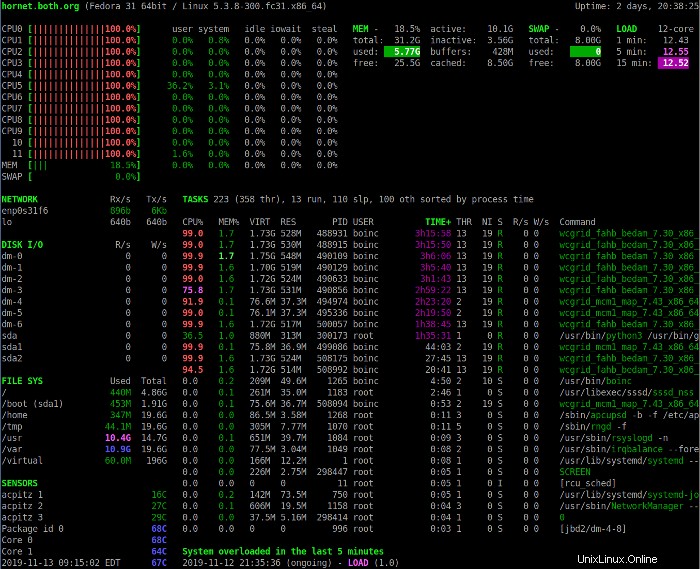
Cette vue inclut des statistiques CPU supplémentaires. Dans les deux modes d'affichage, les descriptions des champs d'utilisation du CPU peuvent vous aider à interpréter les données affichées dans la section CPU. Notez que les processeurs sont numérotés à partir de 0 (zéro).
| CPU | Il s'agit de l'utilisation actuelle du processeur en pourcentage du total disponible. |
| utilisateur | Ce sont les applications et autres programmes exécutés dans l'espace utilisateur, c'est-à-dire pas dans le noyau. |
| système | Ce sont des fonctions au niveau du noyau. Il n'inclut pas le temps CPU pris par le noyau lui-même, juste les appels système du noyau. |
| inactif | Il s'agit du temps d'inactivité, c'est-à-dire le temps non utilisé par un processus en cours d'exécution. |
| sympa | Il s'agit du temps utilisé par les processus qui s'exécutent à un niveau positif et agréable. |
| irq | Ce sont les requêtes d'interruption qui prennent du temps CPU. |
| j'attends | Ce sont des cycles CPU qui sont passés à attendre que des E/S se produisent — c'est du temps CPU perdu. |
| voler | Le pourcentage de cycles CPU pendant lesquels un CPU virtuel attend un CPU réel pendant que l'hyperviseur gère un autre processeur virtuel. |
| ctx-sw | Il s'agit du nombre de changements de contexte par seconde ; il représente le nombre de fois par seconde que le CPU passe d'un processus à un autre. |
| entre | C'est le nombre d'interruptions matérielles par seconde. Une interruption matérielle se produit lorsqu'un périphérique matériel, tel qu'un disque dur, indique à un processeur qu'il a terminé un transfert de données ou qu'une carte d'interface réseau est prête à accepter plus de données. |
| sw_int | Les interruptions logicielles indiquent au CPU qu'une tâche demandée est terminée ou que le logiciel est prêt pour quelque chose. Celles-ci ont tendance à être plus courantes dans les logiciels au niveau du noyau. |
À propos des beaux chiffres
Les nombres de Nice sont le mécanisme utilisé par les administrateurs pour affecter la priorité d'un processus. Il n'est pas possible de modifier directement la priorité d'un processus, mais la modification du nombre gentil peut modifier les résultats de l'algorithme de définition des priorités du planificateur du noyau. Les bons nombres vont de -20 à +19 où les nombres plus élevés sont plus agréables. Le nombre agréable par défaut est 0 et la priorité par défaut est 20. Définir le nombre agréable supérieur à zéro augmente quelque peu le nombre de priorité, rendant ainsi le processus plus agréable et donc moins gourmand en cycles CPU. Définir le nombre agréable sur un nombre plus négatif entraîne un nombre de priorité inférieur, ce qui rend le processus moins agréable. Les nombres agréables peuvent être modifiés à l'aide de la commande renice ou depuis top, atop et htop.
Mémoire
La partie Mémoire de la section Résumé contient des statistiques sur l'utilisation de la mémoire.
| MEM | Cela montre l'utilisation de la mémoire en pourcentage de la quantité totale disponible. |
| total | Il s'agit de la quantité totale de mémoire RAM installée sur l'hôte, moins toute quantité affectée à la carte graphique. |
| utilisé | Il s'agit de la quantité totale de mémoire utilisée par le système et les programmes d'application, mais sans le cache ni les tampons. |
| gratuit | Il s'agit de la quantité de mémoire libre. |
| actif | Il s'agit de la quantité de mémoire activement utilisée. La mémoire inactive est susceptible d'être échangée sur le disque en cas de besoin. |
| inactif | Il s'agit de la mémoire utilisée mais qui n'a pas été consultée depuis un certain temps. |
| tampons | Il s'agit de la mémoire utilisée pour l'espace tampon ; il est généralement utilisé par les communications et les E/S telles que la mise en réseau. Les données sont reçues et stockées jusqu'à ce que le logiciel puisse les récupérer pour les utiliser ou qu'elles puissent être envoyées à un périphérique de stockage ou transmises au réseau. |
| en cache | Il s'agit de la mémoire utilisée pour stocker les données pour le transfert sur disque jusqu'à ce qu'elles puissent être utilisées par un programme ou stockées sur le disque. |
La section Swap est explicite si vous comprenez un peu l'espace de swap et son fonctionnement. Cela montre combien d'espace d'échange total est disponible, combien est utilisé et combien il en reste.
La partie Charge de la section Résumé affiche les moyennes de charge sur une, cinq et 15 minutes.
Vous pouvez utiliser les touches numériques 1 , 3 , 4 , et 5 pour modifier votre vision des données de cette section. Les 2 la touche active et désactive la barre latérale gauche.
En savoir plus sur les moyennes de charge
Les moyennes de charge sont généralement mal comprises, même si elles constituent un critère clé pour mesurer l'utilisation du processeur. Mais qu'est-ce que cela signifie vraiment quand je dis que la moyenne de charge d'une (ou cinq ou 10) minute est de 4,04, par exemple ? La charge moyenne peut être considérée comme une mesure de la demande du processeur ; c'est un nombre qui représente le nombre moyen d'instructions en attente de temps CPU, c'est donc une véritable mesure des performances du CPU.
En savoir plus sur les administrateurs système
- Activer le blog Sysadmin
- L'entreprise automatisée :un guide pour gérer l'informatique avec l'automatisation
- Livre électronique :Automatisation Ansible pour les administrateurs système
- Témoignages du terrain :guide de l'administrateur système sur l'automatisation informatique
- eBook :Un guide de Kubernetes pour les SRE et les administrateurs système
- Derniers articles sur l'administrateur système
Par exemple, un processeur système à processeur unique entièrement utilisé aurait une moyenne de charge de 1. Cela signifie que le processeur suit exactement la demande; en d'autres termes, il a une utilisation parfaite. Une charge moyenne inférieure à 1 signifie que le processeur est sous-utilisé, et une charge moyenne supérieure à 1 signifie que le processeur est surutilisé et qu'il existe une demande refoulée et insatisfaite. Par exemple, une charge moyenne de 1,5 dans un système à un seul processeur indique qu'un tiers des instructions du processeur doivent attendre pour être exécutées que la précédente soit terminée.
Ceci est également vrai pour les processeurs multiples. Si un système à quatre CPU a une moyenne de charge de 4, alors il a une utilisation parfaite. S'il a une charge moyenne de 3,24, par exemple, trois de ses processeurs sont pleinement utilisés et un est utilisé à environ 24 %. Dans l'exemple ci-dessus, un système à quatre processeurs a une moyenne de charge sur une minute de 4,04, ce qui signifie qu'il n'y a pas de capacité restante entre les quatre processeurs et que quelques instructions sont obligées d'attendre. Un système à quatre processeurs parfaitement utilisé afficherait une charge moyenne de 4,00, ce qui signifie que le système est entièrement chargé mais pas surchargé.
La condition de charge moyenne optimale est que la charge moyenne soit égale au nombre total de CPU dans un système. Cela signifierait que chaque processeur est pleinement utilisé et qu'aucune instruction ne doit être forcée d'attendre. Mais la réalité est désordonnée et les conditions optimales sont rarement réunies. Si un hôte fonctionnait à 100 % d'utilisation, cela ne permettrait pas de pics dans les exigences de charge du processeur.
Les moyennes de charge à plus long terme indiquent les tendances d'utilisation globales.
Journal Linux a publié un excellent article sur les charges moyennes, la théorie, les calculs sous-jacents et comment les interpréter, dans son numéro du 1er décembre 2006. Malheureusement, Linux Journal a cessé de paraître, et ses archives ne sont plus disponibles directement, donc le lien est vers une archive tierce.
Rechercher des porcs CPU
L'une des raisons d'utiliser un outil comme Glances est de trouver des processus qui prennent trop de temps CPU. Ouvrez une nouvelle session de terminal (différente de celle qui exécute Glances), puis entrez et démarrez le programme Bash gourmand en CPU suivant.
X=0;while [ 1 ];do echo $X;X=$((X+1));doneCe programme est un porc CPU et utilisera tous les cycles CPU disponibles. Laissez-le s'exécuter pendant que vous terminez cet article et expérimentez avec Glances. Cela vous donnera une idée de ce à quoi ressemble un programme qui accapare les cycles du processeur. Assurez-vous d'observer les effets sur les moyennes de charge au fil du temps, ainsi que le temps cumulé dans le TIME+ colonne pour ce processus.
Section processus
La section Processus affiche des informations standard sur chaque processus en cours d'exécution. Selon le mode de visualisation et la taille de l'écran du terminal, différentes colonnes d'informations seront affichées pour les processus en cours. Le mode par défaut avec un terminal suffisamment large affiche les colonnes répertoriées ci-dessous. Les colonnes affichées changent automatiquement si l'écran du terminal est redimensionné. Les colonnes suivantes sont généralement affichées pour chaque processus de gauche à droite.
| CPU % | Il s'agit de la quantité de temps CPU en pourcentage d'un seul cœur. Par exemple, 98 % représente 98 % des cycles CPU disponibles pour un seul cœur. Plusieurs processus peuvent afficher jusqu'à 100 % d'utilisation du processeur. |
| MEM% | Il s'agit de la quantité de mémoire RAM utilisée par le processus en pourcentage de la mémoire virtuelle totale de l'hôte. |
| VIRT | Il s'agit de la quantité de mémoire virtuelle utilisée par le processus dans un format lisible par l'homme, par exemple 12 Mo pour 12 mégaoctets. |
| RES | Cela fait référence à la quantité de mémoire physique (résidente) utilisée par le processus. Encore une fois, c'est dans un format lisible par l'homme, avec un indicateur de K , M , ou G , pour spécifier des kilo-octets, des mégaoctets ou des gigaoctets. |
| PID | Chaque processus a un numéro d'identification, appelé le PID. Ce nombre peut être utilisé dans des commandes, telles que renice et tuer , pour gérer le processus. N'oubliez pas que le tuer l'utilitaire peut envoyer des signaux à un autre processus en plus du signal "kill". |
| UTILISATEUR | Il s'agit du nom de l'utilisateur propriétaire du processus. |
| TIME+ | Cela indique la quantité cumulée de temps CPU accumulée par le processus depuis son démarrage. |
| THR | Il s'agit du nombre total de threads en cours d'exécution pour ce processus. |
| NI | C'est le nombre gentil du processus. |
| S | Ceci est l'état actuel ; ça peut être (R )unning, (S ) en train de dormir, (je )dle, T ou t lorsque le processus est arrêté lors d'une trace de débogage, ou (Z )ombie. Un zombie est un processus qui a été tué mais qui n'est pas complètement mort, il continue donc à consommer certaines ressources système, telles que la RAM. |
| R/s et W/s | Ce sont les lectures et écritures de disque par seconde. |
| Commande | C'est la commande utilisée pour démarrer le processus. |
Glances détermine généralement automatiquement la colonne de tri par défaut. Les processus peuvent être triés automatiquement (a ), ou par CPU (c ), mémoire (m ), nom (p ), utilisateur (u ), taux d'E/S (i ), ou le temps (t ). Les processus sont automatiquement triés par la ressource la plus utilisée. Dans les images ci-dessus, le TIME+ colonne est en surbrillance.
Section Alertes
Coups d'œil affiche également des avertissements et des alertes critiques, y compris l'heure et la durée de l'événement, au bas de l'écran. Cela peut être utile lorsque vous essayez de diagnostiquer des problèmes et que vous ne pouvez pas regarder l'écran pendant des heures. Ces journaux d'alertes peuvent être activés ou désactivés avec le l (L minuscule), les avertissements peuvent être effacés avec la touche w clé, tandis que les alertes et les avertissements peuvent tous être effacés avec x .
Barre latérale
Glances a une très belle barre latérale sur la gauche qui affiche des informations qui ne sont pas disponibles en top ou htop . Tandis qu'au sommet affiche certaines de ces données, Glances est le seul moniteur qui affiche des données sur les capteurs. Après tout, il est parfois agréable de voir les températures à l'intérieur de votre ordinateur.
Les modules individuels, le disque, le système de fichiers, le réseau et les capteurs peuvent être activés et désactivés à l'aide de d , f , n , et s clés, respectivement. La barre latérale entière peut être basculée en utilisant 2 . Les statistiques Docker peuvent être affichées dans la barre latérale avec D .
Notez que les capteurs matériels ne s'affichent pas lorsque Glances s'exécute sur une machine virtuelle.
Obtenir de l'aide
Vous pouvez obtenir de l'aide en appuyant sur h clé; fermer la page d'aide en appuyant sur h de nouveau. La page d'aide est plutôt concise, mais elle montre les options interactives disponibles et comment les activer et les désactiver. La page de manuel contient des explications concises sur les options qui peuvent être utilisées lors du lancement de Glances.
Vous pouvez appuyer sur q ou Échap pour quitter Coups d'œil.
Configuration
Glances ne nécessite pas de fichier de configuration pour fonctionner correctement. Si vous choisissez d'en avoir un, l'instance système du fichier de configuration sera située dans /etc/glances/glances.conf . Les utilisateurs individuels peuvent avoir une instance locale sur ~/.config/glances/glances.conf , qui remplacera la configuration globale. L'objectif principal de ces fichiers de configuration est de définir des seuils pour les avertissements et les alertes critiques. Vous pouvez également spécifier si certains modules sont affichés par défaut ou non.
Le fichier /usr/local/share/doc/glances/README.rst contient des informations utiles supplémentaires, y compris des modules Python facultatifs que vous pouvez installer pour prendre en charge certaines fonctionnalités facultatives de Glances.
Options de ligne de commande
Glances fournit des options de ligne de commande qui lui permettent de démarrer dans des modes d'affichage spécifiques. Par exemple, la commande coups d'œil -2 démarre le programme avec la barre latérale gauche désactivée.
À distance et plus
En le démarrant en mode serveur, vous pouvez utiliser Glances pour surveiller les hôtes distants :
[root@testvm1 ~]# glances -sVous pouvez ensuite vous connecter au serveur depuis le client avec :
[root@testvm2 ~]# glances -c @testvm1Glances peut afficher une liste des serveurs Glances ainsi qu'un résumé de leur activité. Il dispose également d'une interface Web vous permettant de surveiller les serveurs Glances distants à partir d'un navigateur. Les versions récentes de Glances peuvent également afficher les statistiques Docker.
Il existe également des modules enfichables pour Glances qui fournissent des données de mesure non disponibles dans le programme de base.
Limites
Bien que Glances puisse surveiller de nombreux aspects d'un hôte, il ne peut pas gérer les processus. Il ne peut pas changer le nombre gentil d'un processus ni en tuer un, comme top et htop pouvez. Glances n'est pas un outil interactif. Il est utilisé strictement pour la surveillance. Outils externes comme tuer et renice peut être utilisé pour gérer les processus.
Les aperçus ne peuvent afficher que les processus qui utilisent la majorité des ressources spécifiées, telles que le temps CPU, dans l'espace disponible. S'il y a de la place pour lister seulement 10 processus, c'est tout ce que vous pourrez voir. Glances ne fournit pas d'options de défilement ou de tri inversé qui vous permettraient de voir autre chose que les processus X supérieurs.
L'impact de la mesure
L'effet d'observateur est une théorie physique qui stipule que "le simple fait d'observer une situation ou un phénomène modifie nécessairement ce phénomène". Cela est également vrai lors de la mesure des performances du système Linux.
Le simple fait d'utiliser un outil de surveillance modifie l'utilisation des ressources du système, y compris la mémoire et le temps CPU. Le haut Utility et la plupart des autres moniteurs utilisent peut-être 2 à 3 % du temps CPU d'un système. L'utilitaire Glances a beaucoup plus d'impact que les autres; il utilise généralement entre 10% et 20% du temps CPU, et je l'ai vu utiliser jusqu'à 40% d'un CPU dans un très grand système actif avec 32 CPU. C'est beaucoup, alors tenez compte de son impact lorsque vous envisagez d'utiliser Glances comme moniteur.
Mon opinion personnelle est que c'est un petit prix à payer lorsque vous avez besoin des fonctionnalités de Glances.
Résumé
Malgré son manque de fonctionnalités interactives, telles que la capacité de renicer ou tuer processus, et sa charge CPU élevée, je trouve que Glances est un outil très utile. La documentation complète de Glances est disponible sur Internet, et la page de manuel de Glances propose des options de démarrage et des informations de commande interactives.
Des parties de cet article sont basées sur le nouveau livre de David Both, Using and Administering Linux:Volume 2 – Zero to SysAdmin:Advanced Topics.