Apache Hadoop est un framework open source utilisé pour gérer, stocker et traiter les données de diverses applications de Big Data exécutées sous des systèmes en cluster. Il est écrit en Java avec du code natif en C et des scripts shell. Il utilise un système de fichiers distribué (HDFS) et passe d'un seul serveur à des milliers de machines.
Apache Hadoop est basé sur les quatre composants principaux :
- Hadoop Common : Il s'agit de la collection d'utilitaires et de bibliothèques nécessaires aux autres modules Hadoop.
- HDFS : Également connu sous le nom de système de fichiers distribué Hadoop distribué sur plusieurs nœuds.
- MapReduce : Il s'agit d'un framework utilisé pour écrire des applications afin de traiter d'énormes quantités de données.
- FIL Hadoop : Également connue sous le nom de Yet Another Resource Negotiator, la couche de gestion des ressources de Hadoop.
Dans ce tutoriel, nous expliquerons comment configurer un cluster Hadoop à nœud unique sur Ubuntu 20.04.
Prérequis
- Un serveur exécutant Ubuntu 20.04 avec 4 Go de RAM.
- Un mot de passe root est configuré sur votre serveur.
Mettre à jour les packages système
Avant de commencer, il est recommandé de mettre à jour vos packages système vers la dernière version. Vous pouvez le faire avec la commande suivante :
apt-get update -y
apt-get upgrade -y
Une fois votre système mis à jour, redémarrez-le pour appliquer les modifications.
Installer Java
Apache Hadoop est une application basée sur Java. Vous devrez donc installer Java sur votre système. Vous pouvez l'installer avec la commande suivante :
apt-get install default-jdk default-jre -y
Une fois installé, vous pouvez vérifier la version installée de Java avec la commande suivante :
java -version
Vous devriez obtenir le résultat suivant :
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Créer un utilisateur Hadoop et configurer SSH sans mot de passe
Tout d'abord, créez un nouvel utilisateur nommé hadoop avec la commande suivante :
adduser hadoop
Ensuite, ajoutez l'utilisateur hadoop au groupe sudo
usermod -aG sudo hadoop
Ensuite, connectez-vous avec l'utilisateur hadoop et générez une paire de clés SSH avec la commande suivante :
su - hadoop
ssh-keygen -t rsa
Vous devriez obtenir le résultat suivant :
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
Ensuite, ajoutez cette clé aux clés ssh autorisées et donnez l'autorisation appropriée :
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Ensuite, vérifiez le SSH sans mot de passe avec la commande suivante :
ssh localhost
Une fois que vous êtes connecté sans mot de passe, vous pouvez passer à l'étape suivante.
Installer Hadoop
Tout d'abord, connectez-vous avec l'utilisateur hadoop et téléchargez la dernière version de Hadoop avec la commande suivante :
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Une fois le téléchargement terminé, extrayez le fichier téléchargé avec la commande suivante :
tar -xvzf hadoop-3.2.1.tar.gz
Ensuite, déplacez le répertoire extrait vers /usr/local/ :
sudo mv hadoop-3.2.1 /usr/local/hadoop
Ensuite, créez un répertoire pour stocker le journal avec la commande suivante :
sudo mkdir /usr/local/hadoop/logs
Ensuite, changez la propriété du répertoire hadoop en hadoop :
sudo chown -R hadoop:hadoop /usr/local/hadoop
Ensuite, vous devrez configurer les variables d'environnement Hadoop. Vous pouvez le faire en éditant le fichier ~/.bashrc :
nano ~/.bashrc
Ajoutez les lignes suivantes :
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Enregistrez et fermez le fichier lorsque vous avez terminé. Ensuite, activez les variables d'environnement avec la commande suivante :
source ~/.bashrc
Configurer Hadoop
Dans cette section, nous allons apprendre à configurer Hadoop sur un seul nœud.
Configurer les variables d'environnement Java
Ensuite, vous devrez définir les variables d'environnement Java dans hadoop-env.sh pour configurer les paramètres de projet liés à YARN, HDFS, MapReduce et Hadoop.
Commencez par localiser le chemin Java correct à l'aide de la commande suivante :
which javac
Vous devriez voir le résultat suivant :
/usr/bin/javac
Ensuite, recherchez le répertoire OpenJDK avec la commande suivante :
readlink -f /usr/bin/javac
Vous devriez voir le résultat suivant :
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
Ensuite, éditez le fichier hadoop-env.sh et définissez le chemin Java :
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Ajoutez les lignes suivantes :
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Ensuite, vous devrez également télécharger le fichier d'activation Javax. Vous pouvez le télécharger avec la commande suivante :
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Vous pouvez maintenant vérifier la version de Hadoop à l'aide de la commande suivante :
hadoop version
Vous devriez obtenir le résultat suivant :
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Configurer le fichier core-site.xml
Ensuite, vous devrez spécifier l'URL de votre NameNode. Vous pouvez le faire en éditant le fichier core-site.xml :
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Ajoutez les lignes suivantes :
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Enregistrez et fermez le fichier lorsque vous avez terminé :
Configurer le fichier hdfs-site.xml
Ensuite, vous devrez définir l'emplacement de stockage des métadonnées du nœud, du fichier fsimage et du fichier journal d'édition. Vous pouvez le faire en éditant le fichier hdfs-site.xml. Tout d'abord, créez un répertoire pour stocker les métadonnées des nœuds :
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs Ensuite, éditez le fichier hdfs-site.xml et définissez l'emplacement du répertoire :
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Ajoutez les lignes suivantes :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Enregistrez et fermez le fichier.
Configurer le fichier mapred-site.xml
Ensuite, vous devrez définir les valeurs de MapReduce. Vous pouvez le définir en éditant le fichier mapred-site.xml :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Ajoutez les lignes suivantes :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Enregistrez et fermez le fichier.
Configurer le fichier yarn-site.xml
Ensuite, vous devrez éditer le fichier yarn-site.xml et définir les paramètres liés au YARN :
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Ajoutez les lignes suivantes :
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Enregistrez et fermez le fichier lorsque vous avez terminé.
Formater le nœud de nom HDFS
Ensuite, vous devrez valider la configuration Hadoop et formater le NameNode HDFS.
Tout d'abord, connectez-vous avec l'utilisateur Hadoop et formatez le NameNode HDFS avec la commande suivante :
su - hadoop
hdfs namenode -format
Vous devriez obtenir le résultat suivant :
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Démarrer le cluster Hadoop
Commencez par démarrer le NameNode et le DataNode avec la commande suivante :
start-dfs.sh
Vous devriez obtenir le résultat suivant :
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
Ensuite, démarrez la ressource YARN et les gestionnaires de nœuds en exécutant la commande suivante :
start-yarn.sh
Vous devriez obtenir le résultat suivant :
Starting resourcemanager Starting nodemanagers
Vous pouvez maintenant les vérifier avec la commande suivante :
jps
Vous devriez obtenir le résultat suivant :
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Accéder à l'interface Web Hadoop
Vous pouvez désormais accéder au Hadoop NameNode à l'aide de l'URL http://your-server-ip:9870. Vous devriez voir l'écran suivant :
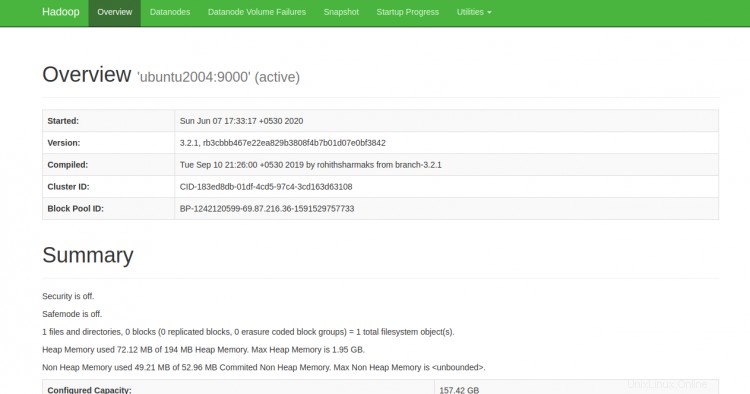
Vous pouvez également accéder aux DataNodes individuels à l'aide de l'URL http://your-server-ip:9864. Vous devriez voir l'écran suivant :
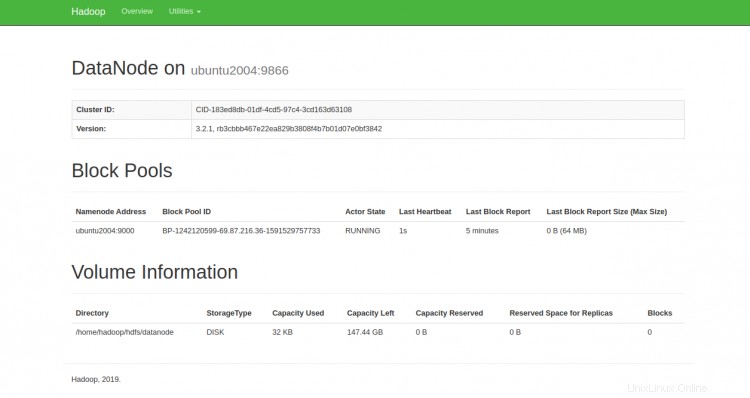
Pour accéder au gestionnaire de ressources YARN, utilisez l'URL http://your-server-ip:8088. Vous devriez voir l'écran suivant :
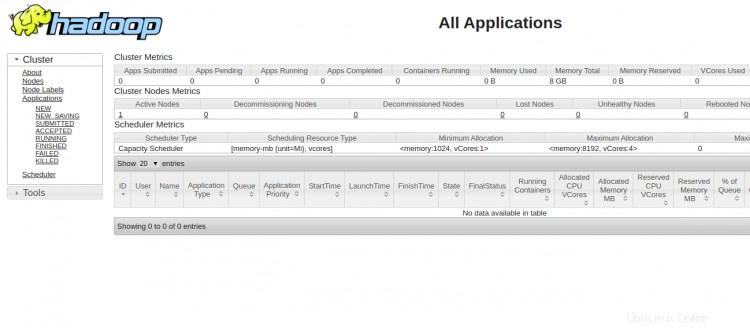
Conclusion
Toutes nos félicitations! vous avez installé Hadoop avec succès sur un seul nœud. Vous pouvez maintenant commencer à explorer les commandes HDFS de base et concevoir un cluster Hadoop entièrement distribué. N'hésitez pas à me demander si vous avez des questions.