Tesseract est l'un des moteurs OCR open source les plus puissants disponibles aujourd'hui. OCR signifie Reconnaissance Optique de Caractères. C'est le processus d'extraction de textes à partir d'images. Par exemple, considérez l'image suivante qui contient du texte qui doit être extrait :

La sortie du moteur OCR, une fois le traitement effectué, ressemblera à ceci :
Open Access Button
C'est ainsi que fonctionne l'OCR. Il est utile dans de nombreuses applications telles que la reconnaissance de plaques d'immatriculation de véhicules, la conversion de copies numérisées de documents au format Word, l'extraction automatique de détails à partir de reçus, etc. Il constitue également la première étape de nombreuses tâches de traitement du langage naturel. Dans ce didacticiel, nous verrons comment installer et configurer rapidement Tesseract, imagemagick et comment les utiliser pour obtenir les meilleurs résultats possibles avec le prétraitement des images.
Le prétraitement des images est une partie importante de la réalisation d'OCR avec Tesseract. Cela garantit que la précision du texte extrait est élevée et réduit l'erreur. Nous allons passer en revue quelques opérations de base à effectuer sur l'image qui l'utilise. Imagemagick est un outil basé sur la ligne de commande de traitement d'image, qui nous aide à effectuer des opérations telles que le recadrage, le redimensionnement, la modification des schémas de couleurs, etc.
1 Installer Tesseract
L'installation de tesseract est assez simple, exécutez les commandes suivantes :
sudo apt update sudo apt install tesseract-ocr
Cela installe le moteur Tesseract. L'image ci-dessous montre la sortie lorsqu'elle est correctement installée :
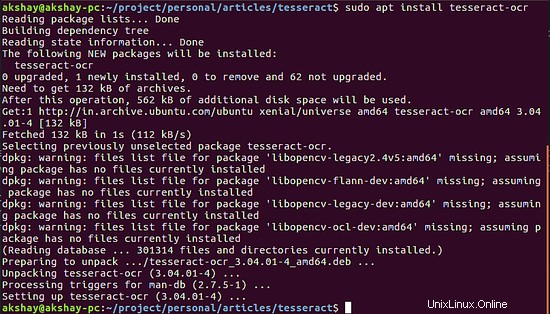
La prochaine chose à faire est d'installer les modules linguistiques. Tesseract est très robuste et peut extraire plus de 100 langues différentes, à condition que les modules linguistiques soient téléchargés. Vous pouvez télécharger un pack de langue particulier en utilisant la commande générique ci-dessous :
sudo apt-get install tesseract-ocr-[lang]
Dans la commande ci-dessus, remplacez "[lang]" par la langue que vous souhaitez télécharger. Voici des exemples pour l'anglais et le français :
sudo apt-get install tesseract-ocr-eng sudo apt-get install tesseract-ocr-fra
Habituellement, le tesseract est livré avec le pack anglais par défaut. L'image ci-dessous montre que l'anglais était déjà installé et que le français devait être téléchargé et installé :
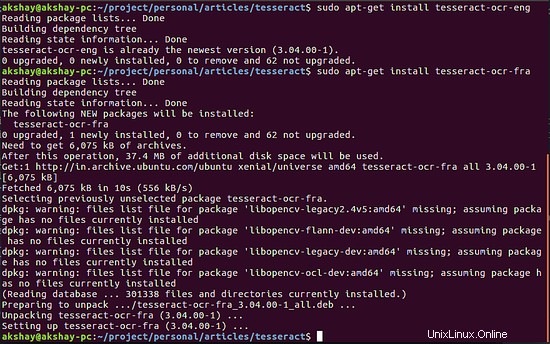
Alternativement, si vous souhaitez que tous les modules linguistiques soient téléchargés, vous pouvez exécuter la commande suivante :
sudo apt-get install tesseract-ocr-all
Ceci termine l'installation de Tesseract.
2 Installer Imagemagick Exécutez la commande suivante pour installer imagemagick
sudo apt install imagemagick
Cet outil s'utilise depuis la ligne de commande à l'aide de la commande convert. Pour vérifier que l'installation est correcte, exécutez la commande suivante et le résultat devrait ressembler à l'image ci-dessous :
convert -h
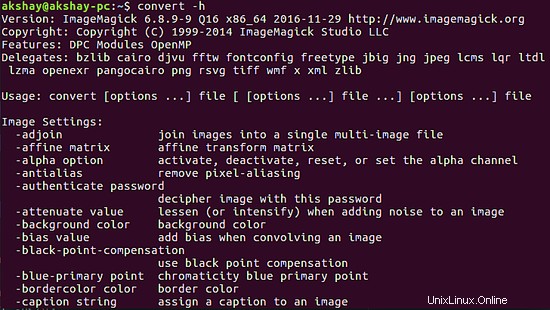
3 Utilisation de Tesseract
Tesseract est capable de prendre des images de nombreux formats différents comme jpg, png, tiff, etc. et d'en extraire du texte. Cette section se concentre sur l'exécution de tesseract et dans la section suivante, nous verrons comment nous pouvons améliorer la précision. Voici quelques commandes de base pour exécuter tesseract :
Pour obtenir la sortie dans le terminal, exécutez la commande générique avec le chemin de l'image
tesseract [image_path] sortie standard
Pour stocker la sortie OCR dans un fichier, exécutez la commande générique suivante :
tesseract [image_path] [file_name]
Après deux images, montrez l'image utilisée et le résultat de l'exécution des commandes ci-dessus sur cette image

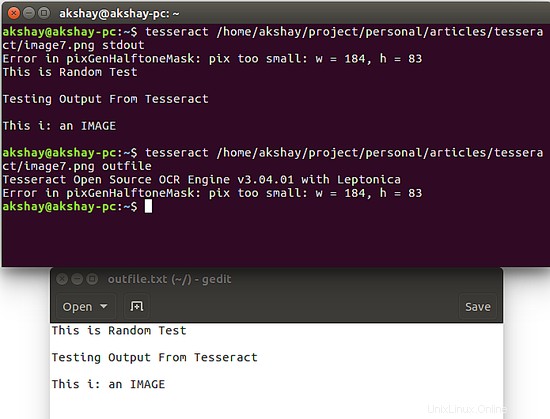
Comme vous pouvez le constater, l'exécution de la deuxième commande a conduit à la création d'un fichier appelé "outfile.txt" dans lequel la sortie peut être trouvée.
4 Pré-traitement des images
À partir de la sortie précédente, vous avez peut-être observé qu'il y a une erreur dans la sortie, ainsi qu'une erreur indiquant que la taille des pixels est petite. C'est l'un des inconvénients de Tesseract, il s'attend à ce que vous donniez une image traitée sur laquelle il peut effectuer une OCR. Dans cette section, nous allons passer en revue certaines des tactiques que vous pouvez utiliser avec l'aide d'imagemagick pour améliorer la qualité de l'image et ainsi augmenter la précision de la sortie.
4.1 redimensionnement
Le redimensionnement est l'une des astuces les plus utiles pour améliorer la précision de l'OCR. En effet, la plupart du temps, les images ont une taille de police très petite qui ne peut pas être lue correctement par Tesseract. Vous pouvez redimensionner une image à l'aide de la commande suivante. Le pourcentage indique la limite de redimensionnement. Puisque nous voulons augmenter la taille, nous devons donner une valeur supérieure à 100. Ici, nous avons donné une valeur de 150 % (utilisez une méthode d'essai et d'erreur pour déterminer le % de redimensionnement parfait pour votre cas d'utilisation).
convert -resize 150% [input_file_path] [output_file_path]
dans la commande ci-dessus, remplacez [input_file_path] par le chemin de l'image qui doit être redimensionnée et [output_file_path] par le chemin de l'image où la sortie doit être stockée. L'image suivante est la sortie lorsque j'ai exécuté la commande :convert -resize 150% image7.png image7_resize.png
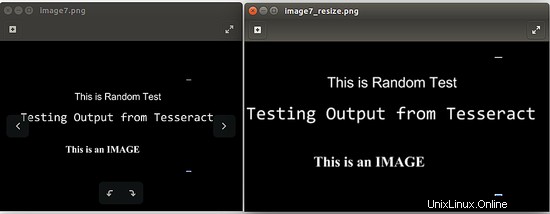
4.2 Utiliser des images en niveaux de gris
Si vous avez une image colorée, il est conseillé de la convertir d'abord en niveaux de gris. Il y a de fortes chances que cela suffise pour obtenir la précision OCR que vous souhaitez. Sinon, pour poursuivre le traitement, vous pouvez utiliser les images en niveaux de gris pour binariser l'image. Utilisez la commande suivante pour convertir votre image afin de la convertir en niveaux de gris
convert [input_file_path] -type Grayscale [output_file_path]
L'image suivante montre la sortie pour l'exécution de la commande convert image6_resize.png -type Grayscale image6_gray.png
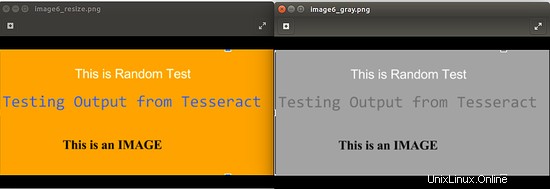
4.3 Binariser l'image
La binarisation ou le seuillage implique la conversion de l'image uniquement en valeurs de noir et blanc. Chaque pixel de cette image n'a qu'une des deux valeurs, noir ou blanc. Cela réduit considérablement la complexité des images. Si vous avez des images avec du bruit ou des images avec des ombres, ou beaucoup de texte, vous pouvez utiliser cette méthode de prétraitement. Pour binariser cette image, assurez-vous d'abord d'avoir une image en niveaux de gris, puis utilisez la commande suivante :
convert [input_file_path] -threshold 55% [output_file_path]
Le pourcentage de seuil peut varier pour obtenir le meilleur résultat pour votre cas d'utilisation. L'image ci-dessous montre un exemple. Il est important de noter que pour l'image à portée de main, la binarisation n'est pas la meilleure option car elle perd certaines données.
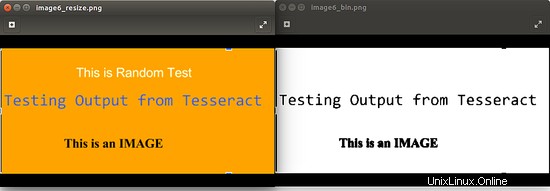
Les points suivants doivent être gardés à l'esprit avant d'appliquer une ou toutes les techniques de prétraitement mentionnées ci-dessus :
- Selon le cas d'utilisation, une ou plusieurs étapes de prétraitement seront utiles.
- lorsqu'une étape de prétraitement entraîne une diminution de la précision, elle doit être ignorée des étapes de prétraitement.
- Les pourcentages lors du redimensionnement ou du seuillage varient d'une image à l'autre, et donc une méthode d'essai et d'erreur doit être appliquée pour obtenir la meilleure valeur de pourcentage possible pour donner la plus grande précision lorsque Tesseract est exécuté
Une fois que vous avez terminé le prétraitement, exécutez Tesseract avec l'image traitée pour vérifier l'exactitude. Tesseract est très puissant mais présente certaines limites en ce qui concerne le type d'image qui est donnée en entrée. J'espère que vous avez trouvé ce tutoriel utile.