Présentation
Apache Hive est un système d'entrepôt de données d'entreprise utilisé pour interroger, gérer et analyser les données stockées dans le système de fichiers distribué Hadoop.
Le langage de requête Hive (HiveQL) facilite les requêtes dans un shell d'interface de ligne de commande Hive. Hadoop peut utiliser HiveQL comme pont pour communiquer avec les systèmes de gestion de bases de données relationnelles et effectuer des tâches basées sur des commandes de type SQL.
Ce guide simple vous montre comment installer Apache Hive sur Ubuntu 20.04 .

Prérequis
Apache Hive est basé sur Hadoop et nécessite un framework Hadoop entièrement fonctionnel.
Installer Apache Hive sur Ubuntu
Pour configurer Apache Hive, vous devez d'abord télécharger et décompresser Hive. Ensuite, vous devez personnaliser les fichiers et paramètres suivants :
- Modifier .bashrc fichier
- Modifier hive-config.sh fichier
- Créer des répertoires Hive dans HDFS
- Configurer hive-site.xml fichier
- Lancer la base de données Derby
Étape 1 :Téléchargez et décompressez Hive
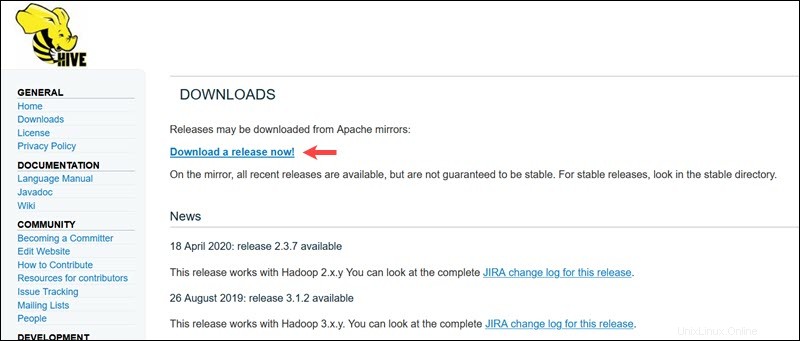
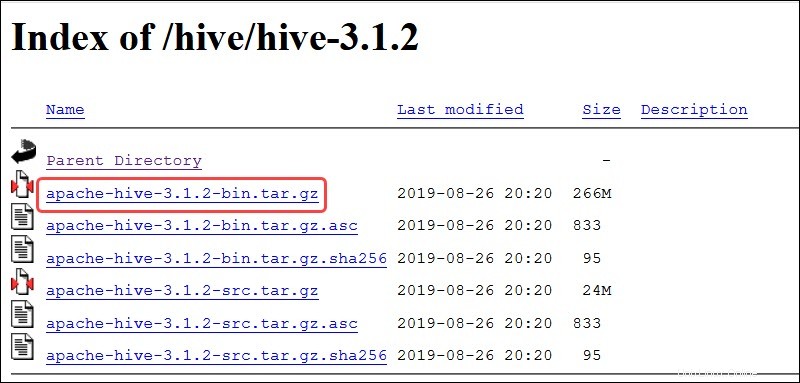
Visitez la page de téléchargement officielle d'Apache Hive et déterminez quelle version de Hive est la mieux adaptée à votre édition Hadoop. Une fois que vous avez déterminé la version dont vous avez besoin, sélectionnez Télécharger une version maintenant ! option.
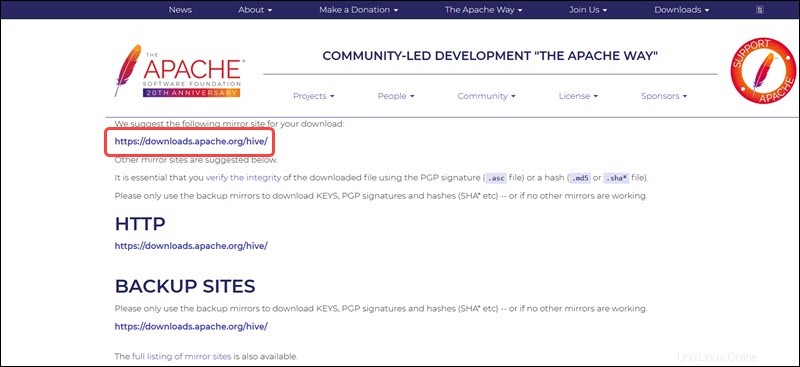
Le lien miroir sur la page suivante mène aux répertoires contenant les packages tar Hive disponibles. Cette page fournit également des instructions utiles sur la façon de valider l'intégrité des fichiers récupérés à partir de sites miroirs.
Le système Ubuntu présenté dans ce guide dispose déjà de Hadoop 3.2.1 installée. Cette version Hadoop est compatible avec Hive 3.1.2 relâcher.
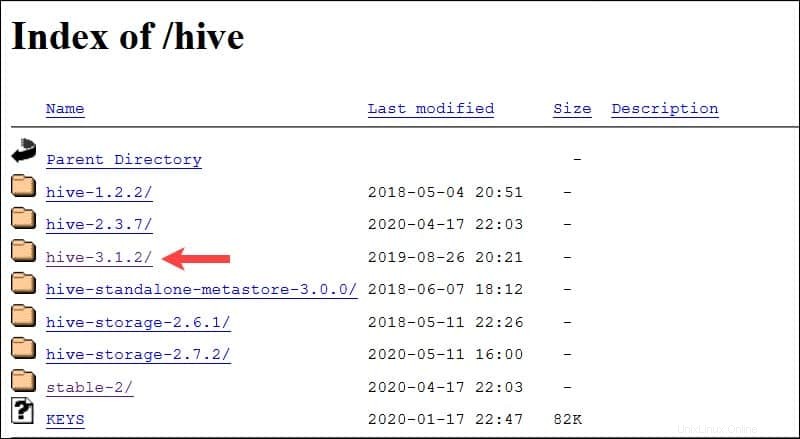
Sélectionnez apache-hive-3.1.2-bin.tar.gz fichier pour commencer le processus de téléchargement.
Vous pouvez également accéder à votre ligne de commande Ubuntu et télécharger les fichiers Hive compressés à l'aide de et wget commande suivie du chemin de téléchargement :
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz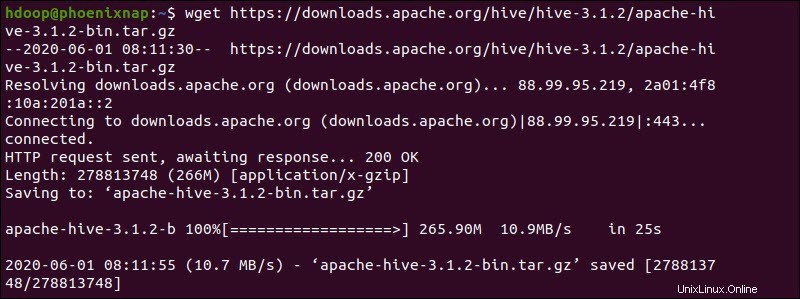
Une fois le processus de téléchargement terminé, décompressez le package Hive compressé :
tar xzf apache-hive-3.1.2-bin.tar.gzLes fichiers binaires Hive sont maintenant situés dans apache-hive-3.1.2-bin répertoire.

Étape 2 :Configurer les variables d'environnement Hive (bashrc)
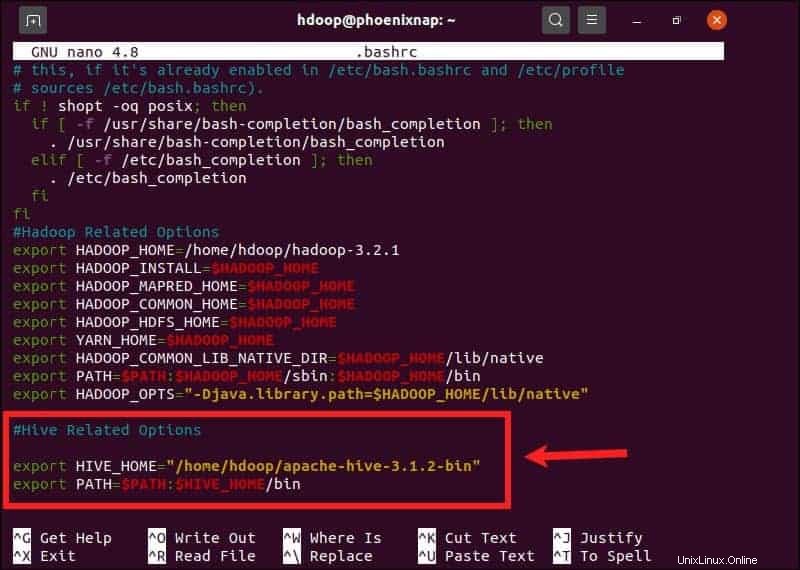
Le $HIVE_HOME la variable d'environnement doit diriger le shell client vers apache-hive-3.1.2-bin annuaire. Modifiez le .bashrc fichier de configuration du shell à l'aide d'un éditeur de texte de votre choix (nous utiliserons nano) :
sudo nano .bashrcAjoutez les variables d'environnement Hive suivantes au .bashrc fichier :
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binLes variables d'environnement Hadoop sont situées dans le même fichier.
Enregistrez et quittez le .bashrc fichier une fois que vous avez ajouté les variables Hive. Appliquez les modifications à l'environnement actuel avec la commande suivante :
source ~/.bashrcÉtape 3 :Modifier le fichier hive-config.sh
Apache Hive doit pouvoir interagir avec le système de fichiers distribué Hadoop. Accéder à hive-config.sh fichier en utilisant le $HIVE_HOME créé précédemment variables :
sudo nano $HIVE_HOME/bin/hive-config.sh
Ajoutez le HADOOP_HOME variable et le chemin complet vers votre répertoire Hadoop :
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Enregistrez les modifications et quittez hive-config.sh fichier.
Étape 4 :Créer des répertoires Hive dans HDFS
Créez deux répertoires distincts pour stocker les données dans la couche HDFS :
- Le temporaire, tmp répertoire va stocker les résultats intermédiaires des processus Hive.
- L'entrepôt répertoire va stocker les tables liées à Hive.
Créer un répertoire tmp
Créer un tmp répertoire dans la couche de stockage HDFS. Ce répertoire va stocker les données intermédiaires que Hive envoie au HDFS :
hdfs dfs -mkdir /tmpAjoutez des autorisations d'écriture et d'exécution aux membres du groupe tmp :
hdfs dfs -chmod g+w /tmpVérifiez si les autorisations ont été correctement ajoutées :
hdfs dfs -ls /La sortie confirme que les utilisateurs disposent désormais des autorisations d'écriture et d'exécution.

Créer un répertoire d'entrepôt
Créer l'entrepôt répertoire dans le répertoire /user/hive/ répertoire parent :
hdfs dfs -mkdir -p /user/hive/warehouseAjouter écrire et exécuter autorisations d'entrepôt membres du groupe :
hdfs dfs -chmod g+w /user/hive/warehouseVérifiez si les autorisations ont été correctement ajoutées :
hdfs dfs -ls /user/hiveLa sortie confirme que les utilisateurs disposent désormais des autorisations d'écriture et d'exécution.

Étape 5 :Configurer le fichier hive-site.xml (facultatif)
Les distributions Apache Hive contiennent des fichiers de configuration de modèle par défaut. Les fichiers de modèle sont situés dans le Hive conf répertoire et définir les paramètres Hive par défaut.
Utilisez la commande suivante pour localiser le bon fichier :
cd $HIVE_HOME/conf
Lister les fichiers contenus dans le dossier à l'aide de ls commande.

Utilisez le hive-default.xml.template pour créer le hive-site.xml fichier :
cp hive-default.xml.template hive-site.xmlAccéder au fichier hive-site.xml fichier à l'aide de l'éditeur de texte nano :
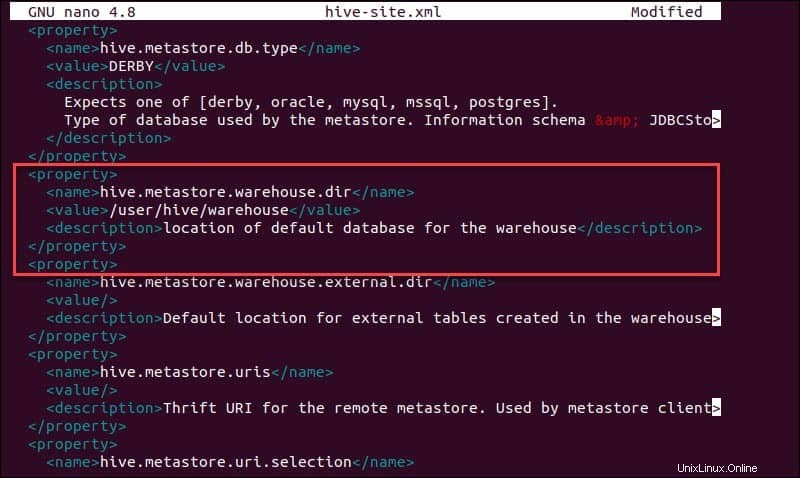
sudo nano hive-site.xmlL'utilisation de Hive en mode autonome plutôt que dans un cluster Apache Hadoop réel est une option sûre pour les nouveaux arrivants. Vous pouvez configurer le système pour utiliser votre stockage local plutôt que la couche HDFS en définissant le hive.metastore.warehouse.dir valeur du paramètre à l'emplacement de votre entrepôt Hive répertoire.
Étape 6 :Lancer la base de données Derby
Apache Hive utilise la base de données Derby pour stocker les métadonnées. Initier la base de données Derby, depuis le Hive bin répertoire à l'aide de schematool commande :
$HIVE_HOME/bin/schematool -dbType derby -initSchemaLe processus peut prendre quelques instants.
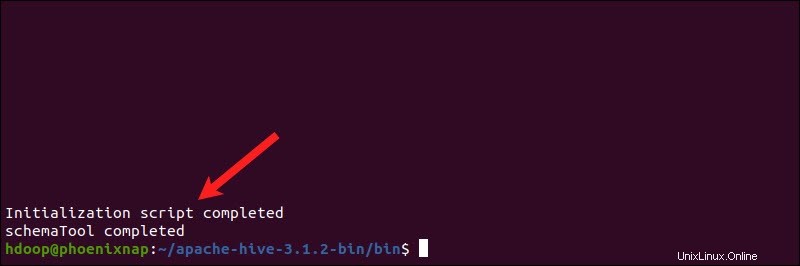
Derby est le magasin de métadonnées par défaut pour Hive. Si vous envisagez d'utiliser une solution de base de données différente, telle que MySQL ou PostgreSQL, vous pouvez spécifier un type de base de données dans le hive-site.xml fichier.
Comment réparer l'erreur d'incompatibilité de goyave dans Hive
Si la base de données Derby ne démarre pas correctement, vous pouvez recevoir une erreur avec le contenu suivant :
"Exception dans le fil "main" java.lang.NoSuchMethodError :com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V"
Cette erreur indique qu'il y a très probablement un problème d'incompatibilité entre Hadoop et Hive guava versions.
Localisez le pot de goyave fichier dans la ruche lib répertoire :
ls $HIVE_HOME/lib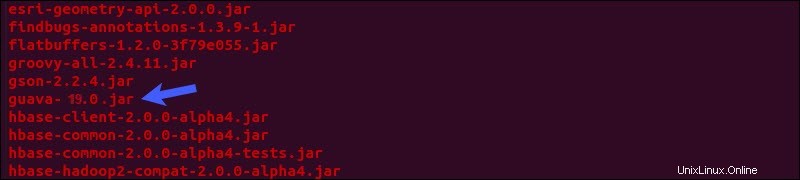
Localisez le pot de goyave fichier dans la lib Hadoop répertoire également :
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Les deux versions répertoriées ne sont pas compatibles et sont à l'origine de l'erreur. Retirez la goyave existante fichier de la ruche lib répertoire :
rm $HIVE_HOME/lib/guava-19.0.jarCopiez la goyave fichier de la lib Hadoop répertoire de la ruche lib répertoire :
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Utilisez l'outil schematool commande à nouveau pour lancer la base de données Derby :
$HIVE_HOME/bin/schematool -dbType derby -initSchemaLancer le shell client Hive sur Ubuntu
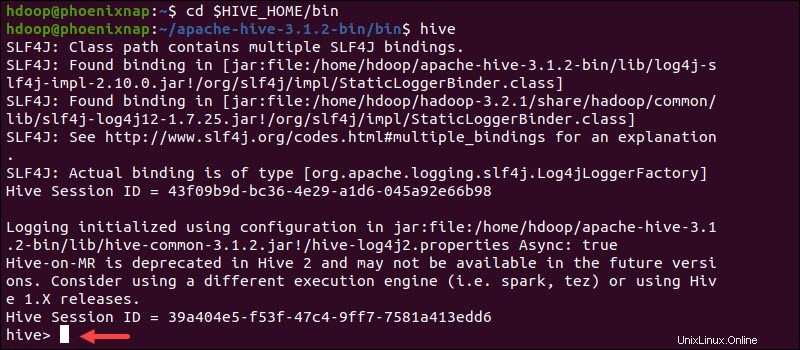
Démarrez l'interface de ligne de commande Hive à l'aide des commandes suivantes :
cd $HIVE_HOME/binhiveVous pouvez maintenant émettre des commandes de type SQL et interagir directement avec HDFS.