Présentation
Elasticsearch est un moteur de recherche évolutif en temps réel déployé en clusters. Combiné à l'orchestration Kubernetes, Elasticsearch est facile à configurer, à gérer et à faire évoluer.
Le déploiement d'un cluster Elasticsearch par défaut crée trois pods. Chaque pod remplit les trois fonctions :maître, données et client. Cependant, la meilleure pratique serait de déployer manuellement plusieurs pods Elasticsearch dédiés pour chaque rôle.
Cet article explique comment déployer manuellement Elasticsearch sur Kubernetes sur sept pods et à l'aide d'un graphique Helm prédéfini.

Prérequis
- Un cluster Kubernetes (nous avons utilisé Minikube).
- Le gestionnaire de paquets Helm.
- L'outil de ligne de commande kubectl.
- Accès à la ligne de commande ou au terminal.
Comment déployer manuellement Elasticsearch sur Kubernetes
La meilleure pratique consiste à utiliser sept pods dans le cluster Elasticsearch :
- Trois pods maîtres pour gérer le cluster.
- Deux pods de données pour stocker les données et traiter les requêtes.
- Deux pods client (ou de coordination) pour diriger le trafic.
Le déploiement manuel d'Elasticsearch sur Kubernetes avec sept pods dédiés est un processus simple qui nécessite de définir des valeurs Helm par rôle.
Étape 1 :Configurer Kubernetes
1. Le cluster nécessite des ressources importantes. Réglez les processeurs Minikube sur un minimum de 4 et la mémoire sur 8192 Mo :
minikube config set cpus 4
minikube config set memory 8192
2. Ouvrez le terminal et démarrez minikube avec les paramètres suivants :
minikube start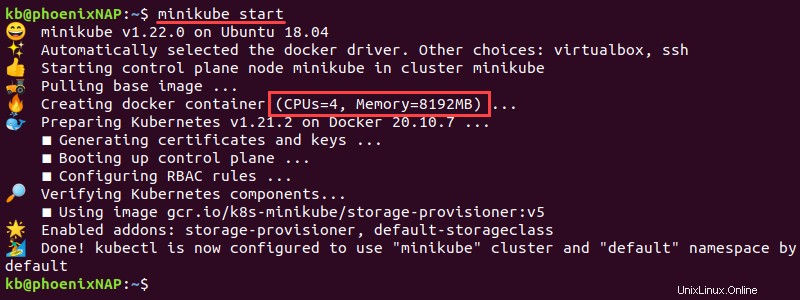
L'instance démarre avec la mémoire et les processeurs configurés.
3. Minikube nécessite un values.yaml fichier pour exécuter Elasticsearch. Téléchargez le fichier avec :
curl -O https://raw.githubusercontent.com/elastic/helm-charts/master/elasticsearch/examples/minikube/values.yaml
Le fichier contient des informations utilisées à l'étape suivante pour les trois configurations de pod.
Étape 2 :Configurer les valeurs par rôle de pod
1. Copiez le contenu de values.yaml fichier en utilisant le cp commande dans trois fichiers de configuration de pod différents :
cp values.yaml master.yaml
cp values.yaml data.yaml
cp values.yaml client.yaml
2. Recherchez les quatre fichiers YAML à l'aide de ls commande :
ls -l *.yaml3. Ouvrez le fichier master.yaml fichier avec un éditeur de texte et ajoutez la configuration suivante au début :
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
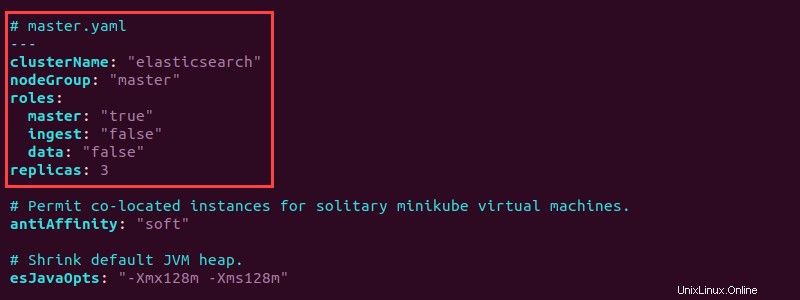
La configuration définit le groupe de nœuds sur maître dans elasticsearch cluster et définit le rôle principal sur "true" . De plus, le master.yaml crée trois répliques de nœud principal.
Le fichier master.yaml complet ressemble à ceci :
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
# Permit co-located instances for solitary minikube virtual machines.
antiAffinity: "soft
# Shrink default JVM heap.
esJavaOpts: "-Xmx128m -Xms128m"
# Allocate smaller chunks of memory per pod.
resources:
requests:
cpu: "100m"
memory: "512M"
limits:
cpu: "1000m"
memory: "512M"
# Request smaller persistent volumes.
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 100M
4. Enregistrez le fichier et fermez.
5. Ouvrez le fichier data.yaml fichier et ajoutez les informations suivantes en haut pour configurer les pods de données :
# data.yaml
---
clusterName: "elasticsearch"
nodeGroup: "data"
roles:
master: "false"
ingest: "true"
data: "true"
replicas: 2
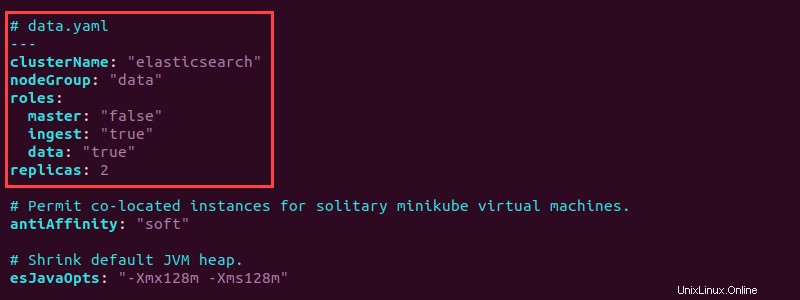
La configuration crée deux répliques de pod de données. Définissez les rôles de données et d'ingestion sur "true" . Enregistrez le fichier et fermez.
6. Ouvrez le fichier client.yaml fichier et ajoutez les informations de configuration suivantes en haut :
# client.yaml
---
clusterName: "elasticsearch"
nodeGroup: "client"
roles:
master: "false"
ingest: "false"
data: "false"
replicas: 2
service:
type: "LoadBalancer"
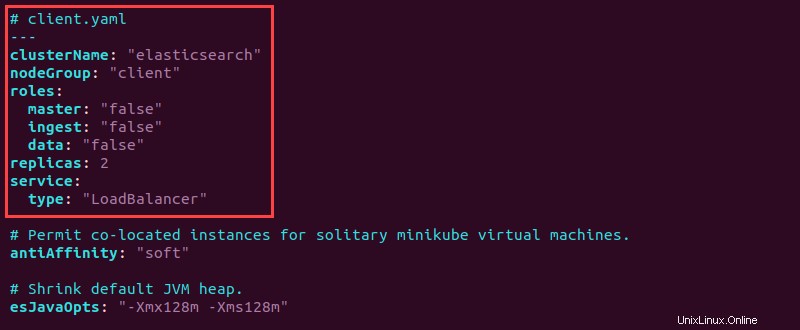
7. Enregistrez le fichier et fermez.
Le client a tous les rôles définis sur "false" puisque le client gère les demandes de service. Le type de service est désigné comme "LoadBalancer" pour équilibrer les demandes de service uniformément sur tous les nœuds.
Étape 3 :Déployer les pods Elasticsearch par rôle
1. Ajoutez le référentiel Helm :
helm repo add elastic https://helm.elastic.co
2. Utilisez l'helm install commande trois fois, une fois pour chaque fichier YAML personnalisé créé à l'étape précédente :
helm install elasticsearch-multi-master elastic/elasticsearch -f ./master.yaml
helm install elasticsearch-multi-data elastic/elasticsearch -f ./data.yaml
helm install elasticsearch-multi-client elastic/elasticsearch -f ./client.yaml
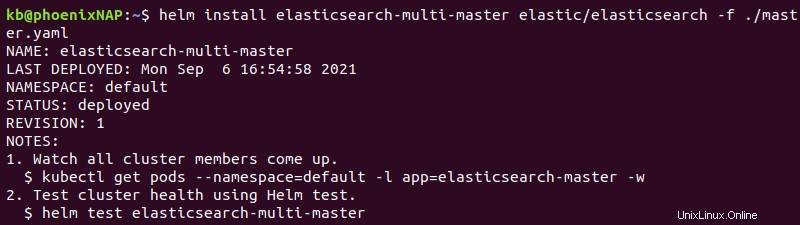
La sortie imprime les détails du déploiement.
3. Attendez que les membres du cluster se déploient. Utilisez la commande suivante pour inspecter la progression et confirmer l'achèvement :
kubectl get pods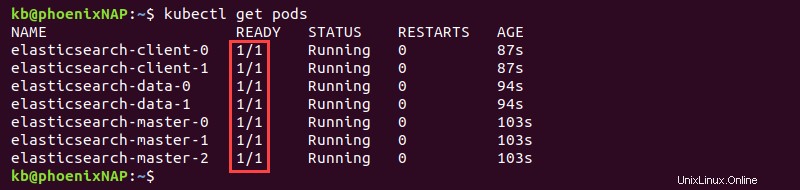
La sortie affiche le PRÊT colonne avec des valeurs 1/1 une fois le déploiement terminé pour les sept pods.
Étape 4 :Tester la connexion
1. Pour accéder à Elasticsearch localement, transférez le port 9200 en utilisant le kubectl commande :
kubectl port-forward service/elasticsearch-master
La commande transmet la connexion et la maintient ouverte. Laissez la fenêtre du terminal ouverte et passez à l'étape suivante.
2. Dans un autre onglet de terminal, testez la connexion avec :
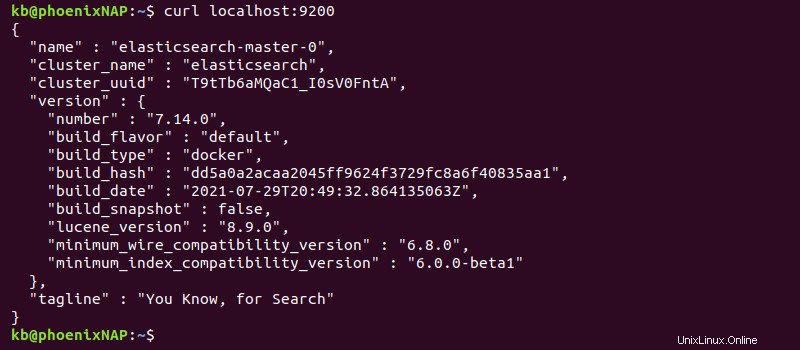
curl localhost:9200La sortie imprime les informations de déploiement.
Vous pouvez également accéder à localhost :9200 depuis le navigateur.
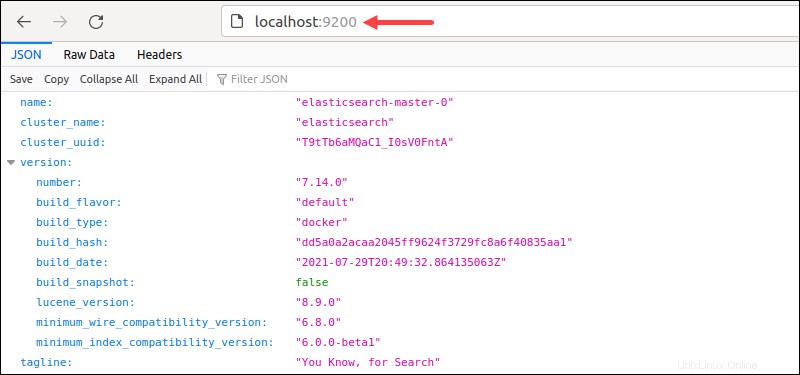
La sortie affiche les détails du cluster au format JSON, indiquant que le déploiement a réussi.
Comment déployer Elasticsearch avec sept pods à l'aide d'un graphique Helm prédéfini
Un graphique Helm prédéfini pour le déploiement d'Elasticsearch sur sept pods dédiés est disponible dans le référentiel Bitnami. L'installation du graphique de cette manière évite de créer manuellement des fichiers de configuration.
Étape 1 :Configurer Kubernetes
1. Allouez au moins 4 processeurs et 8 192 Mo de mémoire :
minikube config set cpus 4
minikube config set memory 8192
2. Démarrez Minikube :
minikube startL'instance Minikube démarre avec la configuration spécifiée.
Étape 2 :Ajoutez le référentiel Bitnami et déployez le graphique Elasticsearch
1. Ajoutez le référentiel Bitnami Helm avec :
helm repo add bitnami https://charts.bitnami.com/bitnami
2. Installez le graphique en exécutant :
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch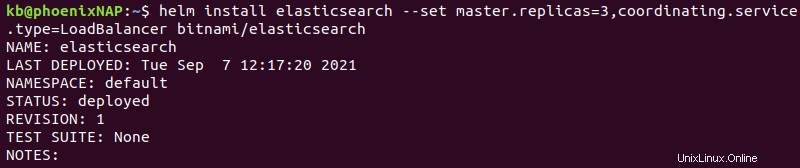
La commande a les options suivantes :
- Elasticsearch s'installe sous le nom de version
elasticsearch. master.replicas=3ajoute trois réplicas maîtres au cluster. Nous vous recommandons de vous en tenir à trois nœuds maîtres.coordinating.service.type=LoadBalancerdéfinit les nœuds clients pour équilibrer les demandes de service uniformément sur tous les nœuds.
3. Surveillez le déploiement avec :
kubectl get pods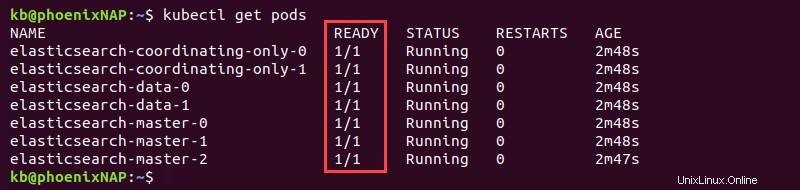
Les sept modules affichent 1/1 dans le PRÊT lorsqu'Elasticsearch est entièrement déployé.
Étape 3 :Tester la connexion
1. Transférer la connexion au port 9200 :
kubectl port-forward svc/elasticsearch-master 9200Laissez la connexion ouverte et passez à l'étape suivante.
2. Dans un autre onglet du terminal, vérifiez la connexion avec :
curl localhost:9200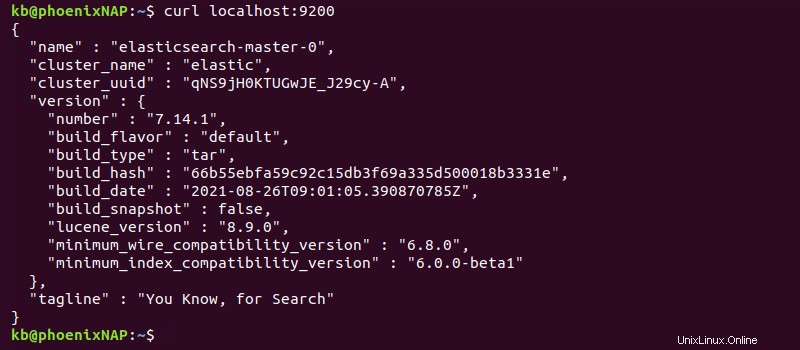
Vous pouvez également accéder à la même adresse à partir du navigateur pour afficher les informations de déploiement au format JSON.