Présentation
Apprendre à créer un Spark DataFrame est l'une des premières étapes pratiques dans l'environnement Spark. Spark DataFrames aide à fournir une vue sur la structure de données et d'autres fonctions de manipulation de données. Différentes méthodes existent selon la source de données et le format de stockage des données des fichiers.
Cet article explique comment créer manuellement un Spark DataFrame en Python à l'aide de PySpark.

Prérequis
- Python 3 installé et configuré.
- PySpark installé et configuré.
- Un environnement de développement Python prêt à tester les exemples de code (nous utilisons le bloc-notes Jupyter).
Méthodes de création de Spark DataFrame
Il existe trois façons de créer manuellement un DataFrame dans Spark :
1. Créez une liste et analysez-la en tant que DataFrame à l'aide de toDataFrame() méthode de SparkSession .
2. Convertir un RDD en DataFrame en utilisant le toDF() méthode.
3. Importez un fichier dans une SparkSession directement en tant que DataFrame.
Les exemples utilisent des exemples de données et un RDD pour la démonstration, bien que les principes généraux s'appliquent à des structures de données similaires.
Créer DataFrame à partir d'une liste de données
Pour créer un Spark DataFrame à partir d'une liste de données :
1. Générez un exemple de liste de dictionnaires avec des données sur les jouets :
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importez et créez une SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
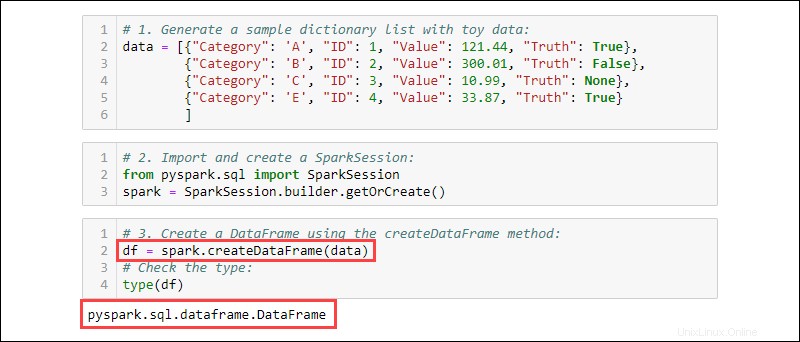
3. Créez un DataFrame à l'aide de createDataFrame méthode. Vérifiez le type de données pour confirmer que la variable est un DataFrame :
df = spark.createDataFrame(data)
type(df)
Créer DataFrame à partir de RDD
Un événement typique lorsque vous travaillez dans Spark consiste à créer un DataFrame à partir d'un RDD existant. Créez un exemple de RDD, puis convertissez-le en DataFrame.
1. Créez une liste de dictionnaires contenant des données sur les jouets :
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
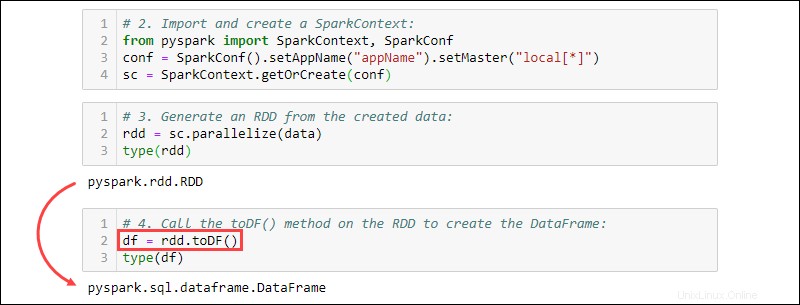
2. Importez et créez un SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3. Générez un RDD à partir des données créées. Vérifiez le type pour confirmer que l'objet est un RDD :
rdd = sc.parallelize(data)
type(rdd)
4. Appelez le toDF() méthode sur le RDD pour créer le DataFrame. Testez le type d'objet pour confirmer :
df = rdd.toDF()
type(df)
Créer un DataFrame à partir de sources de données
Spark peut gérer un large éventail de sources de données externes pour construire des DataFrames. La syntaxe générale pour lire à partir d'un fichier est :
spark.read.format('<data source>').load('<file path/file name>')Le nom et le chemin de la source de données sont tous deux de type chaîne. Des sources de données spécifiques ont également une syntaxe alternative pour importer des fichiers en tant que DataFrames.
Création à partir d'un fichier CSV
Créez un Spark DataFrame en lisant directement à partir d'un fichier CSV :
df = spark.read.csv('<file name>.csv')Lire plusieurs fichiers CSV dans un seul DataFrame en fournissant une liste de chemins :
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
Par défaut, Spark ajoute un en-tête pour chaque colonne. Si un fichier CSV a un en-tête que vous souhaitez inclure, ajoutez l'option méthode lors de l'importation :
df = spark.read.csv('<file name>.csv').option('header', 'true')
Les options individuelles se cumulent en les appelant les unes après les autres. Vous pouvez également utiliser les options lorsque plus d'options sont nécessaires lors de l'importation :
df = spark.read.csv('<file name>.csv').options(header = True)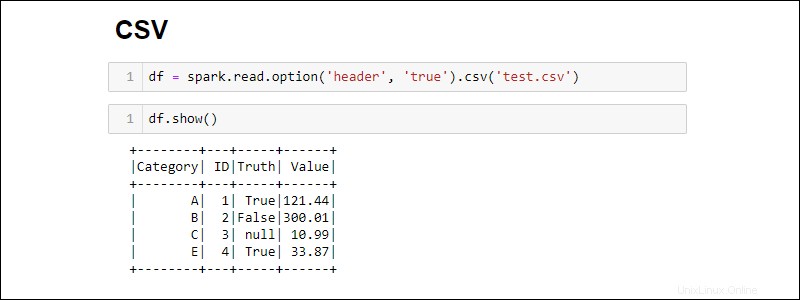
Notez que la syntaxe est différente lors de l'utilisation option vs options .
Création à partir d'un fichier TXT
Créez un DataFrame à partir d'un fichier texte avec :
df = spark.read.text('<file name>.txt')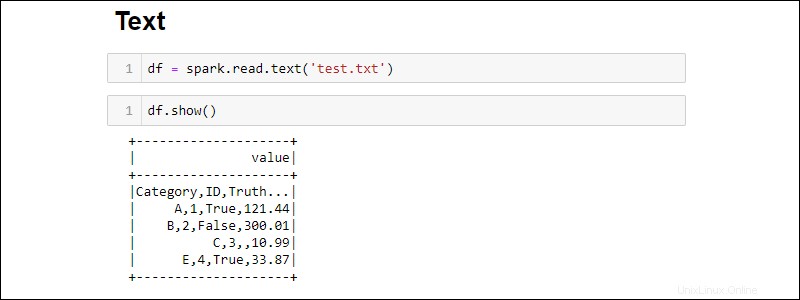
Le csv est une autre façon de lire à partir d'un txt type de fichier dans un DataFrame. Par exemple :
df = spark.read.option('header', 'true').csv('<file name>.txt')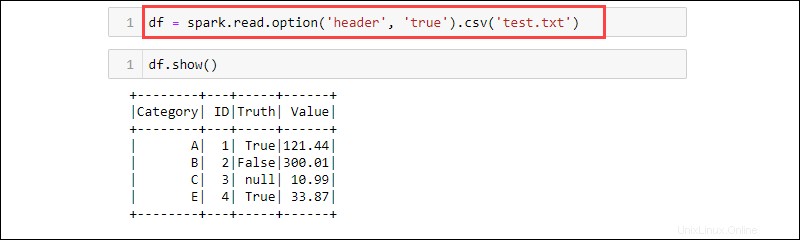
CSV est un format textuel où le délimiteur est une virgule (,) et la fonction est donc capable de lire des données à partir d'un fichier texte.
Création à partir d'un fichier JSON
Créez un Spark DataFrame à partir d'un fichier JSON en exécutant :
df = spark.read.json('<file name>.json')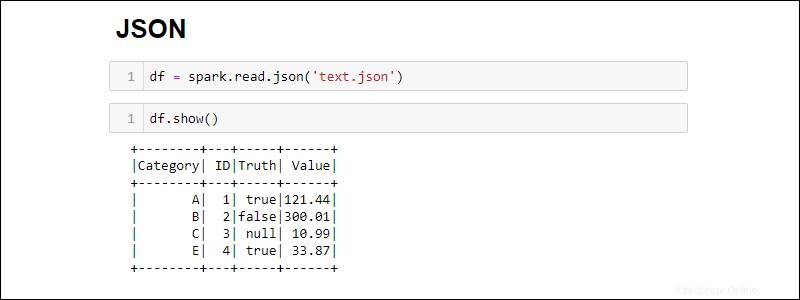
Création à partir d'un fichier XML
La compatibilité des fichiers XML n'est pas disponible par défaut. Installez les dépendances pour créer un DataFrame à partir d'une source XML.
1. Téléchargez la dépendance Spark XML. Enregistrez le .jar fichier dans le dossier Spark jar.
2. Lisez un fichier XML dans un DataFrame en exécutant :
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
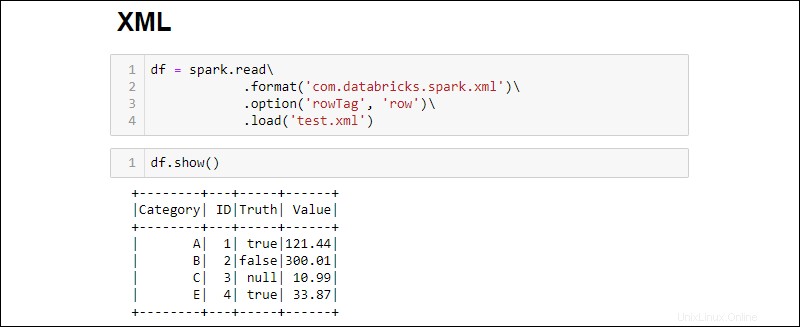
Changer le rowTag option si chaque ligne de votre XML le fichier est étiqueté différemment.
Créer DataFrame à partir de la base de données RDBMS
La lecture à partir d'un SGBDR nécessite un connecteur de pilote. L'exemple explique comment se connecter et extraire des données d'une base de données MySQL. Des étapes similaires fonctionnent pour d'autres types de bases de données.
1. Téléchargez le connecteur MySQL Java Driver. Enregistrez le .jar fichier dans le dossier Spark jar.
2. Exécutez le serveur SQL et établissez une connexion.
3. Établissez une connexion et récupérez toute la table de la base de données MySQL dans un DataFrame :
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
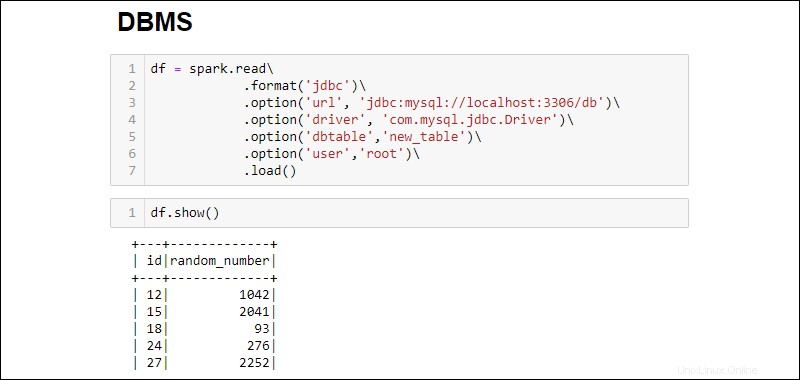
Les options ajoutées sont les suivantes :
- L'URL est
localhost:3306si le serveur s'exécute localement. Sinon, récupérez l'URL de votre serveur de base de données. - Nom de la base de données étend l'URL pour accéder à une base de données spécifique sur le serveur. Par exemple, si une base de données est nommée
dbet que le serveur s'exécute localement, l'URL complète pour établir une connexion estjdbc:mysql://localhost:3306/db. - Nom du tableau garantit que toute la table de la base de données est extraite dans le DataFrame. Utilisez
.option('query', '<query>')au lieu de.option('dbtable', '<table name>')pour exécuter une requête spécifique au lieu de sélectionner une table entière. - Utiliser le nom d'utilisateur et mot de passe de la base de données pour établir la connexion. Lors de l'exécution sans mot de passe, omettez l'option spécifiée.