Présentation
Apache Hive est un outil d'entreposage de données utilisé pour effectuer des requêtes et analyser des données structurées dans Apache Hadoop. Il utilise un langage de type SQL appelé HiveQL.
Dans cet article, découvrez comment créer une table dans Hive et charger des données. Nous vous montrerons également les commandes HiveQL cruciales pour afficher les données.

Prérequis
- Un système exécutant Linux
- Un compte utilisateur avec sudo ou racine privilèges
- Accès à une fenêtre de terminal/ligne de commande
- Travailler avec Hadoop mise en place
- Travail Ruche mise en place
Créer et charger une table dans Hive
Une table dans Hive est un ensemble de données qui utilise un schéma pour trier les données selon des identifiants donnés.
La syntaxe générale pour créer une table dans Hive est :
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT 'col_comment'],, ...)
[COMMENT 'table_comment']
[ROW FORMAT row_format]
[FIELDS TERMINATED BY char]
[STORED AS file_format];
Suivez les étapes ci-dessous pour créer une table dans Hive.
Étape 1 :Créer une base de données
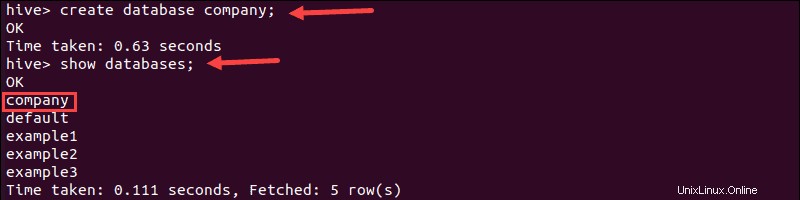
1. Créez une base de données nommée "société" en exécutant la commande create commande :
create database company;Le terminal imprime un message de confirmation et le temps nécessaire pour effectuer l'action.
2. Ensuite, vérifiez que la base de données est créée en exécutant le show commande :
show databases;3. Recherchez la base de données "entreprise" dans la liste :
4. Ouvrez la base de données "société" en utilisant la commande suivante :
use company;
Étape 2 :Créer une table dans Hive
La base de données "société" ne contient aucune table après la création initiale. Créons une table dont les identifiants correspondront au fichier .txt à partir duquel vous souhaitez transférer des données.
1. Créez un fichier "employees.txt" dans le dossier /hdoop annuaire. Le fichier doit contenir des données sur les employés :

2. Organisez les données du fichier « employees.txt » en colonnes. Les noms de colonne dans notre exemple sont :
- ID
- Nom
- Pays
- Département
- Salaire
3. Utilisez les noms de colonne lors de la création d'une table. Créez la table en exécutant la commande suivante :
create table employees (id int, name string, country string, department string, salary int)
4. Créez un schéma logique qui organise les données du fichier .txt dans les colonnes correspondantes. Dans le fichier "employees.txt", les données sont séparées par un '-' . Pour créer un type de schéma logique :
row format delimited fields terminated by '-';Le terminal imprime un message de confirmation :

5. Vérifiez si la table est créée en exécutant le show commande :
show tables;
Étape 3 :Charger des données à partir d'un fichier
Vous avez créé une table, mais elle est vide car les données ne sont pas chargées depuis le fichier "employees.txt" situé dans le dossier /hdoop répertoire.
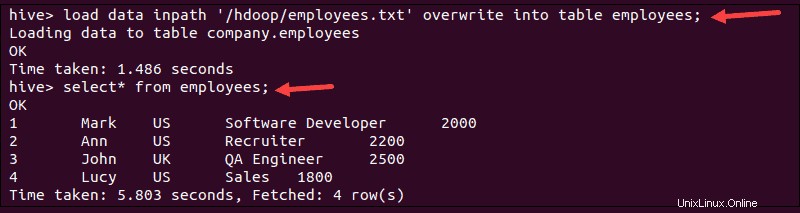
1. Charger les données en exécutant le load commande :
load data inpath '/hdoop/employees.txt' overwrite into table employees;
2. Vérifiez si les données sont chargées en exécutant la commande select commande :
select * from employees;Le terminal imprime les données importées du employees.txt fichier :
Afficher les données de la ruche
Vous disposez de plusieurs options pour afficher les données du tableau. En utilisant les options suivantes, vous pouvez manipuler plus efficacement de grandes quantités de données.
Afficher les colonnes
Afficher les colonnes d'un tableau en exécutant le desc commande :
desc employees;La sortie affiche les noms et les propriétés des colonnes :

Afficher les données sélectionnées
Supposons que vous souhaitiez afficher les employés et leur pays d'origine. Sélectionnez et affichez les données en exécutant select commande :
select name,country from employees;La sortie contient la liste des employés et leurs pays :
