Présentation
MapReduce est un module de traitement du projet Apache Hadoop. Hadoop est une plate-forme conçue pour s'attaquer au Big Data à l'aide d'un réseau d'ordinateurs pour stocker et traiter les données.
Ce qui est si attrayant avec Hadoop, c'est que des serveurs dédiés abordables suffisent pour faire fonctionner un cluster. Vous pouvez utiliser du matériel grand public à faible coût pour gérer vos données.
Hadoop est hautement évolutif. Vous pouvez commencer avec une seule machine, puis étendre votre cluster à un nombre infini de serveurs. Les deux principaux composants par défaut de cette bibliothèque de logiciels sont :
- MapReduce
- HDFS – Système de fichiers distribué Hadoop
Dans cet article, nous parlerons du premier des deux modules. Vous allez apprendre qu'est-ce que MapReduce, comment cela fonctionne et la terminologie de base de Hadoop MapReduce .

Qu'est-ce que Hadoop MapReduce ?
Le modèle de programmation de Hadoop MapReduce facilite le traitement des mégadonnées stockées sur HDFS.
En utilisant les ressources de plusieurs machines interconnectées, MapReduce gère efficacement une grande quantité de données structurées et non structurées .
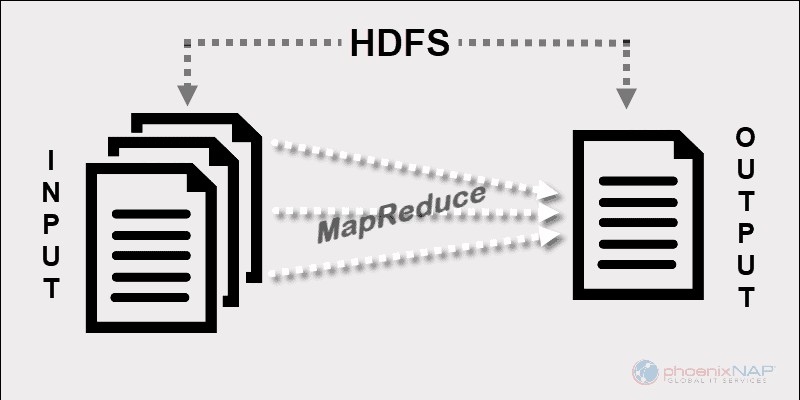
Avant Spark et d'autres frameworks modernes, cette plate-forme était le seul acteur dans le domaine du traitement distribué du Big Data.
MapReduce attribue des fragments de données sur les nœuds d'un cluster Hadoop. L'objectif est de diviser un ensemble de données en morceaux et d'utiliser un algorithme pour traiter ces morceaux en même temps. Le traitement parallèle sur plusieurs machines augmente considérablement la vitesse de traitement même des pétaoctets de données.
Applications de traitement de données distribuées
Ce cadre permet l'écriture d'applications pour le traitement distribué des données. Généralement, Java est ce que la plupart des programmeurs utilisent puisque Hadoop est basé sur Java .
Cependant, vous pouvez écrire des applications MapReduce dans d'autres langages, tels que Ruby ou Python. Quel que soit le langage utilisé par un développeur, vous n'avez pas à vous soucier du matériel sur lequel le cluster Hadoop s'exécute.
Évolutivité
L'infrastructure Hadoop peut utiliser des serveurs d'entreprise, ainsi que du matériel de base. Les créateurs de MapReduce avaient l'évolutivité à l'esprit. Il n'est pas nécessaire de réécrire une application si vous ajoutez d'autres machines. Modifiez simplement la configuration du cluster et MapReduce continue de fonctionner sans interruption.
Ce qui rend MapReduce si efficace, c'est qu'il s'exécute sur les mêmes nœuds que HDFS. Le planificateur attribue des tâches aux nœuds où les données résident déjà. Cette manière de faire augmente le débit disponible dans un cluster.
Comment fonctionne MapReduce
À un niveau élevé, MapReduce divise les données d'entrée en fragments et les distribue sur différentes machines.
Les fragments d'entrée sont constitués de paires clé-valeur. Les tâches de carte parallèles traitent les données fragmentées sur les machines d'un cluster. La sortie de mappage sert alors d'entrée pour l'étape de réduction. La tâche de réduction combine le résultat dans une sortie de paire clé-valeur particulière et écrit les données sur HDFS.
Le système de fichiers distribué Hadoop s'exécute généralement sur le même ensemble de machines que le logiciel MapReduce. Lorsque le framework exécute une tâche sur les nœuds qui stockent également les données, le temps nécessaire pour effectuer les tâches est considérablement réduit.
Terminologie de base de Hadoop MapReduce
Comme nous l'avons mentionné ci-dessus, MapReduce est une couche de traitement dans un environnement Hadoop. MapReduce travaille sur des tâches liées à un travail. L'idée est de traiter une grande demande en la découpant en unités plus petites.
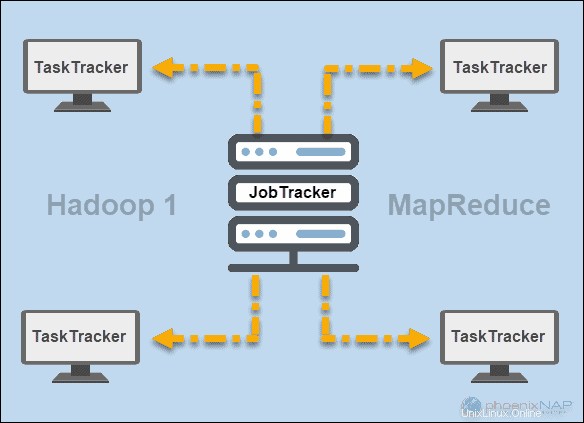
JobTracker et TaskTracker
Aux débuts de Hadoop (version 1), JobTracker et TaskTracker les démons exécutaient des opérations dans MapReduce. À l'époque, un cluster Hadoop ne pouvait prendre en charge que les applications MapReduce.
Un JobTracker contrôlait la distribution des demandes d'application aux ressources de calcul d'un cluster. Puisqu'il surveillait l'exécution et l'état de MapReduce, il résidait sur un nœud maître.
Un TaskTracker traité les demandes provenant du JobTracker. Tous les trackers de tâches ont été distribués sur les nœuds esclaves dans un cluster Hadoop.
FIL
Plus tard dans Hadoop version 2 et ultérieure, YARN est devenu le principal gestionnaire de ressources et de planification. D'où le nom Yet Another Resource Manager . Yarn a également travaillé avec d'autres frameworks pour le traitement distribué dans un cluster Hadoop.
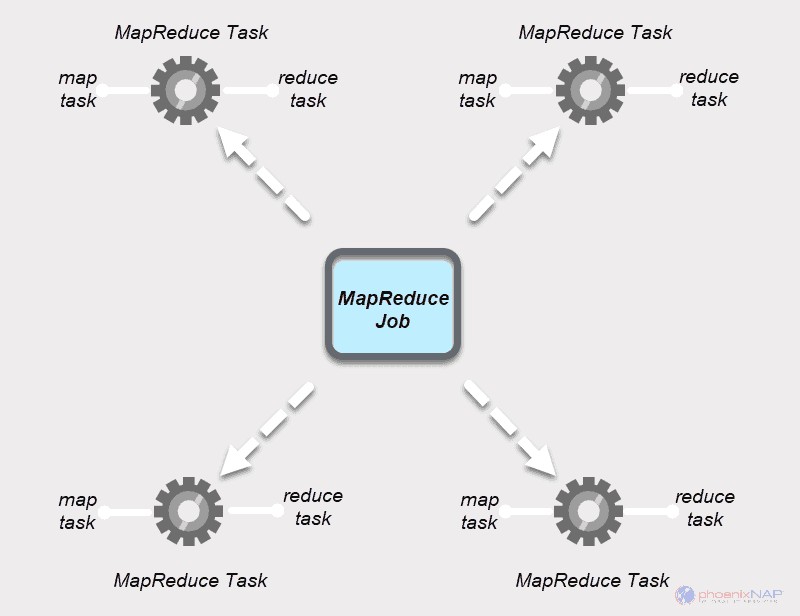
Tâche MapReduce
Une tâche MapReduce est la première unité de travail du processus MapReduce. Il s'agit d'une tâche que les processus Map et Reduce doivent accomplir. Un travail est divisé en tâches plus petites sur un groupe de machines pour une exécution plus rapide.
Les tâches doivent être suffisamment importantes pour justifier le temps de traitement des tâches. Si vous divisez une tâche en segments inhabituellement petits, le temps total pour préparer les fractionnements et créer des tâches peut dépasser le temps nécessaire pour produire la sortie réelle de la tâche.
Tâche MapReduce
Les travaux MapReduce ont deux types de tâches.
Une tâche cartographique est une instance unique d'une application MapReduce. Ces tâches déterminent les enregistrements à traiter à partir d'un bloc de données. Les données d'entrée sont divisées et analysées, en parallèle, sur les ressources de calcul attribuées dans un cluster Hadoop. Cette étape d'une tâche MapReduce prépare la sortie de la paire
A Réduire la tâche traite une sortie d'une tâche cartographique. Semblable à l'étape de la carte, toutes les tâches de réduction se produisent en même temps et fonctionnent indépendamment. Les données sont agrégées et combinées pour fournir le résultat souhaité. Le résultat final est un ensemble réduit de paires
Les étapes Mapper et Réduire comportent chacune deux parties.
La Carte la première partie traite du fractionnement des données d'entrée qui sont affectées à des tâches cartographiques individuelles. Ensuite, le mappage La fonction crée la sortie sous la forme de paires clé-valeur intermédiaires.
Le Réduire l'étape a un mélange et une étape de réduction. Mélange prend la sortie de la carte et crée une liste de paires clé-valeur-liste associées. Ensuite, réduire agrège les résultats du brassage pour produire la sortie finale demandée par l'application MapReduce.
Comment Hadoop Map et Reduce fonctionnent ensemble
Comme son nom l'indique, MapReduce fonctionne en traitant les données d'entrée en deux étapes - Map et Réduire . Pour le démontrer, nous allons utiliser un exemple simple avec le comptage du nombre d'occurrences de mots dans chaque document.
Le résultat final que nous recherchons est :Combien de fois les mots Apache, Hadoop, Class et Track apparaissent au total dans tous les documents .
À des fins d'illustration, l'exemple d'environnement se compose de trois nœuds. L'entrée contient six documents distribués dans le cluster. Nous allons faire simple ici, mais dans des circonstances réelles, il n'y a pas de limite. Vous pouvez avoir des milliers de serveurs et des milliards de documents.
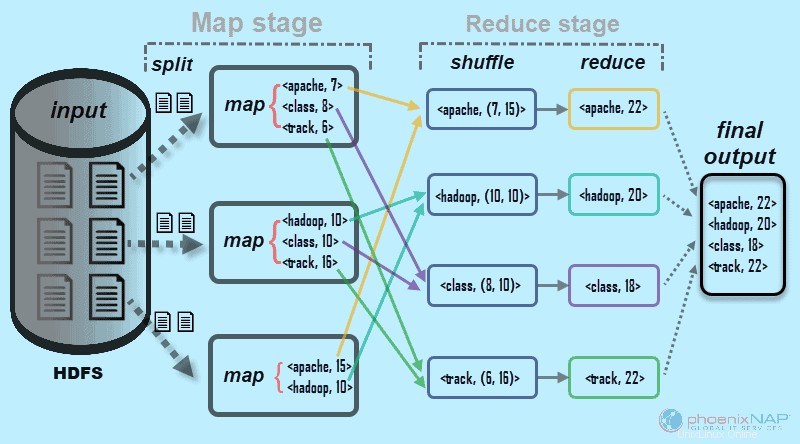
1. Tout d'abord, à l'étape de la carte , les données d'entrée (les six documents) sont divisées et répartis sur le cluster (les trois serveurs). Dans ce cas, chaque tâche cartographique fonctionne sur un fractionnement contenant deux documents. Pendant le mappage, il n'y a pas de communication entre les nœuds. Ils fonctionnent indépendamment.
Ce processus est effectué en tâches parallèles sur tous les nœuds pour tous les documents et donne une sortie unique.
L'étape de mélange assure les clés Apache, Hadoop, Class, et Suivre sont triés pour l'étape de réduction. Ce processus regroupe les valeurs par clés sous la forme de
Dans notre exemple du diagramme, les tâches de réduction obtiennent les résultats individuels suivants :
L'exemple que nous avons utilisé ici est basique. MapReduce effectue des tâches beaucoup plus compliquées.
Certains des cas d'utilisation incluent :
- Transformer les journaux Apache en valeurs séparées par des tabulations (TSV).
- Déterminer le nombre d'adresses IP uniques dans les données du blog
- Effectuer une modélisation et une analyse statistiques complexes
- Exécution d'algorithmes de machine learning à l'aide de différents frameworks, tels que Mahout
Comment les partitions Hadoop mappent les données d'entrée
Le partitionneur est responsable du traitement de la sortie de la carte. Une fois que MapReduce divise les données en morceaux et les affecte aux tâches de mappage, le framework partitionne les données clé-valeur. Ce processus a lieu avant que la sortie finale de la tâche de mappeur ne soit produite.
MapReduce partitionne et trie la sortie en fonction de la clé. Ici, toutes les valeurs des clés individuelles sont regroupées et le partitionneur crée une liste contenant les valeurs associées à chaque clé. En envoyant toutes les valeurs d'une seule clé au même réducteur, le partitionneur assure une distribution égale de la sortie de carte vers le réducteur.
Le partitionneur par défaut est bien configuré pour de nombreux cas d'utilisation, mais vous pouvez reconfigurer la façon dont MapReduce partitionne les données.
Si vous utilisez un partitionneur personnalisé, assurez-vous que la taille des données préparées pour chaque réducteur est à peu près la même. Lorsque vous partitionnez les données de manière inégale, une tâche de réduction peut prendre beaucoup plus de temps. Cela ralentirait l'ensemble du travail MapReduce.