La surveillance est l'une des activités essentielles dans le monde DevOps. et je n'ai même pas besoin de vous convaincre de la raison pour laquelle la surveillance est une bonne idée. Vous le savez déjà, n'est-ce pas ?
Vous pouvez bien sûr vous en tenir aux outils de ligne de commande pour surveiller votre serveur et les conteneurs docker qui y sont exécutés, une approche basée sur l'interface graphique ajoute la commodité d'analyser les mesures de performance avec une expérience intuitive pour observer plusieurs paramètres à la fois sur l'écran Il rend également il est plus facile de partager le tableau de bord de surveillance avec des personnes moins techniques.
Dans ce tutoriel, je vais vous montrer comment configurer la surveillance des conteneurs docker avec dockprom et la présenter sous une forme visuellement attrayante grâce à Grafana.
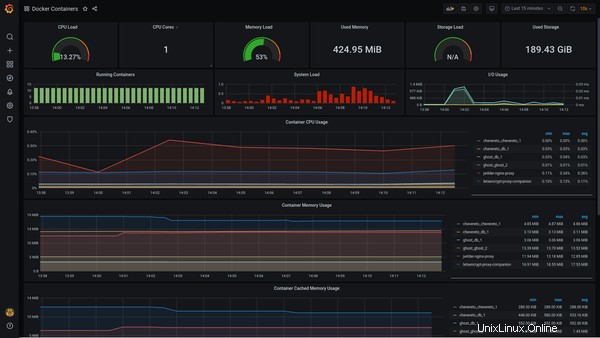
Surveillance de l'hôte docker et des conteneurs avec Dockprom
Dockprom est l'une de ces piles qui exécute divers outils de surveillance en tant qu'ensemble d'outils collectifs pour vos besoins de surveillance de serveur.
stefanprodan/dockprom Surveillance des hôtes et des conteneurs Docker avec Prometheus, Grafana, cAdvisor, NodeExporter et AlertManager - stefanprodan/dockprom GitHubstefanprodan
GitHubstefanprodan 
Gardez à l'esprit que l'exemple ici sera basé sur la configuration du proxy inverse Nginx. La configuration officielle de Dockprom est basée sur Caddy.
Chez Linux Handbook et High On Cloud, nous utilisons Nginx dans la pratique courante. J'ai donc repensé la configuration de Dockprom pour qu'elle soit basée sur Nginx au lieu de Caddy. Le résultat semble très simpliste comme nos précédents déploiements Nginx.
Essentiels pour la configuration de Dockprom
Dockprom utilise les outils suivants pour fournir une solution de surveillance pour votre hôte et vos conteneurs Docker.
Grafana
Grafana vous permet d'interroger, de visualiser et d'alerter sur les métriques et les journaux, peu importe où ils sont stockés. Ce sera la principale et la seule interface Web à travers laquelle vous utiliserez toutes les applications dorsales restantes partagées dans les sections des outils restants.
C'est donc ici que vous devez ajouter les variables d'environnement populaires basées sur Nginx que vous avez utilisées pour accéder à nos applications depuis n'importe où sur le Web :
Environnementenvironment:
- VIRTUAL_HOST=dockprom.domain.com
- LETSENCRYPT_HOST=dockprom.domain.com
Assurez-vous de modifier cela en fonction de votre domaine ou sous-domaine.
Prométhée
Prometheus est une boîte à outils open source de surveillance et d'alerte des systèmes utilisée par des milliers de personnes dans le monde.
Pushgateway
Le Pushgateway est un service intermédiaire qui vous permet de pousser les métriques des travaux qui ne peuvent pas être récupérés. Vous voudrez peut-être lire ceci pour vraiment savoir si vous en avez réellement besoin. En effet, il existe des cas limités où cela serait nécessaire.
Gestionnaire d'alertes
L'Alertmanager gère les alertes envoyées par les applications clientes telles que le serveur Prometheus. Il se charge de les dédupliquer, de les regrouper et de les acheminer vers l'intégration de récepteur appropriée, telle que la messagerie électronique, PagerDuty ou OpsGenie. Il prend également en charge le silence et l'inhibition des alertes.
cAdvisor
cAdvisor est un outil open source de Google qui fournit aux utilisateurs de conteneurs une compréhension de l'utilisation des ressources et des caractéristiques de performance de leurs conteneurs en cours d'exécution.
Dans cette configuration particulière, j'étais confronté à un problème de récupération de deux métriques basées sur deux erreurs respectives après le déploiement de la configuration officielle de cAdvisor indiquée dans la pile Dockprom :
Failed to get system UUID: open /etc/machine-id: no such file or directory
Could not configure a source for OOM detection, disabling OOM events: open /dev/kmsg: no such file or directory
J'ai recherché le référentiel officiel de cAdvisor où des solutions avaient été fournies. Le premier a fonctionné mais le second n'était pas tout à fait ce que je cherchais, car cette solution était basée sur un docker run commande de lancement basée.
Un correctif Docker Compose était nécessaire. J'ai d'abord essayé de monter /dev/kmsg mais cela n'allait pas faire le travail. Enfin, basé sur le docker run solution basée, j'ai trouvé que sur des lignes similaires, Docker Compose fournit un indicateur séparé appelé devices qui peut être utilisé pour monter /dev/kmsg comme appareil. Vous pouvez lire à ce sujet ici.
Ainsi, le correctif pour le premier problème consistait à ajouter ce qui suit aux lignes de la section des volumes :
volumes volumes:
---
---
- /etc/machine-id:/etc/machine-id:ro
- /var/lib/dbus/machine-id:/var/lib/dbus/machine-id:ro
Le second est comme on vient de le voir :
Appareils devices:
- /dev/kmsg:/dev/kmsg
Notez à quel point ces mesures sont importantes pour le montage à partir de l'hôte, car c'est l'hôte que vous souhaitez surveiller via Docker.
Exportateur de nœuds
L'exportateur de nœuds Prometheus expose une grande variété de métriques liées au matériel et au noyau. C'est similaire à la façon dont les métriques sont exposées dans cAdvisor.
En regroupant tout ce qui précède, votre fichier Docker Compose complet ressemblera à ceci :
version: '3.7'
networks:
net:
external: true
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus:v2.24.0
container_name: prometheus
volumes:
- ./prometheus:/etc/prometheus
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--storage.tsdb.retention.time=200h'
- '--web.enable-lifecycle'
restart: on-failure
networks:
- net
labels:
org.label-schema.group: "monitoring"
alertmanager:
image: prom/alertmanager:v0.21.0
container_name: alertmanager
volumes:
- ./alertmanager:/etc/alertmanager
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
restart: on-failure
networks:
- net
labels:
org.label-schema.group: "monitoring"
nodeexporter:
image: prom/node-exporter:v1.0.1
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
restart: on-failure
networks:
- net
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:v0.38.7
container_name: cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
- /etc/machine-id:/etc/machine-id:ro
- /var/lib/dbus/machine-id:/var/lib/dbus/machine-id:ro
#- /dev/kmsg:/dev/kmsg:rw
#command: ["start", "--privileged"]
restart: on-failure
devices:
- /dev/kmsg:/dev/kmsg
networks:
- net
labels:
org.label-schema.group: "monitoring"
grafana:
image: grafana/grafana:7.3.7
container_name: grafana
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_USERS_ALLOW_SIGN_UP=false
restart: on-failure
networks:
- net
environment:
- VIRTUAL_HOST=dockprom.domain.com
- LETSENCRYPT_HOST=dockprom.domain.com
labels:
org.label-schema.group: "monitoring"
pushgateway:
image: prom/pushgateway:v1.3.1
container_name: pushgateway
restart: on-failure
networks:
- net
labels:
org.label-schema.group: "monitoring"
Si vous êtes curieux, vous pouvez vérifier et comparer le fichier ci-dessus avec le design officiel de Dockprom.
Meilleure disponibilité - Surveillance Web gratuite et page d'étatPlate-forme de surveillance de la disponibilité radicalement meilleure avec alertes d'appel téléphonique, pages d'état et gestion des incidents intégrée. Forfait gratuit inclus ! Jipi de Metrics Watch
Jipi de Metrics Watch 
Configuration de l'hôte Docker et de la surveillance des conteneurs
Maintenant que j'ai partagé ce que Dockprom Stack implémente avec les définitions officielles des outils de surveillance de serveur, permettez-moi maintenant d'énumérer le processus étape par étape de déploiement de cette conception de Dockprom basée sur Nginx ainsi que les correctifs essentiels de cAdvisor.
À des fins de test, vous pouvez utiliser une nanode de 1 Go sur Linode pour tester la configuration, mais à des fins de production, le serveur doit disposer d'au moins 4 Go. C'est principalement à cause de Prometheus.
Linode | Le cloud ouvert indépendant pour les développeursNotre mission est d'accélérer l'innovation en rendant le cloud computing simple, abordable et accessible à tous. Linode
Linode  Je suppose que vous connaissez le concept de Docker et Docker Compose. Notez également que vous ne pouvez surveiller que les conteneurs Docker exécutés sur le même serveur.
Je suppose que vous connaissez le concept de Docker et Docker Compose. Notez également que vous ne pouvez surveiller que les conteneurs Docker exécutés sur le même serveur. Étape 1 :Récupérez la configuration officielle de Dockprom
Ouvrez un terminal sur le serveur et saisissez la commande suivante :
git clone https://github.com/stefanprodan/dockprom
cd dockprom
Étape 2 :Réviser le fichier docker-compose.yml
Comme j'ai discuté et partagé le fichier docker-compose.yml basé sur Nginx il y a quelques instants sous la section Node Exporter. Veuillez modifier le fichier et le réviser.
Étape 3 :Lancez la configuration !
En supposant que vous êtes dans le même répertoire dockprom, exécutez la commande Docker Compose pour lancer la pile Dockprom :
docker-compose up -d
Étape 4 :Accéder à la pile Dockprom via Grafana
N'oubliez pas que vous avez également défini votre URL d'accès dans la configuration Grafana pour l'accès Web ? Vous pouvez maintenant l'utiliser pour obtenir un accès complet à la pile.
Le nom d'utilisateur et le mot de passe ont été définis sur admin . Il est fortement recommandé de le remplacer par un mot de passe fort. Un panneau de connexion Web typique ressemble à :
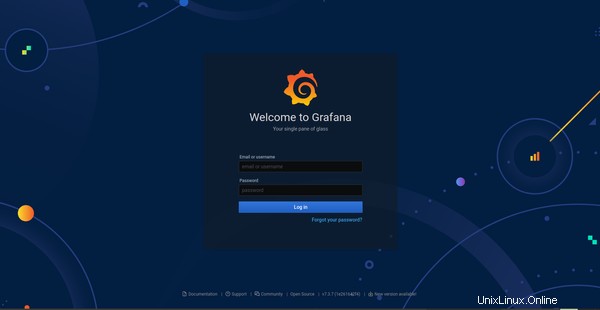
Attendez un moment que l'interface se charge :

Astuce bonus
Après vous être connecté à Grafana, naviguer rapidement vers les statistiques de métriques peut être écrasant au début, c'est pourquoi je partagerai le lien direct vers le panneau du tableau de bord pour un accès immédiat :https://dockprom.domain.com/dashboards
Comme vous pouvez le voir, il vous suffit d'ajouter /dashboards à votre propre domaine ou sous-domaine. À partir de cette page, vous pouvez surveiller les métriques pour :
- Conteneurs Docker
- Système hôte
- Prométhée
- Nginx
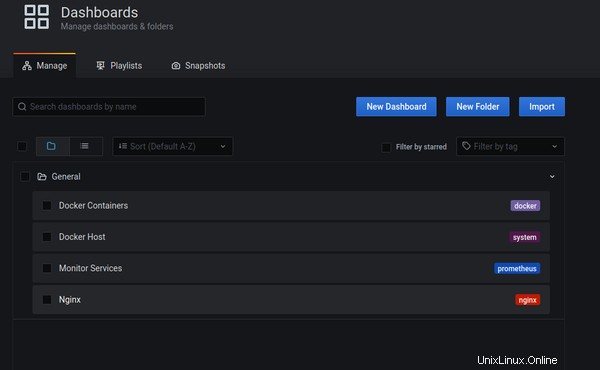
Veuillez noter que Nginx (4ème et dernier sur la liste ci-dessus) afficherait des statistiques vides s'il n'était pas directement installé sur l'hôte. Cela ne doit pas être confondu avec Jwilder Nginx puisqu'il s'exécute sur Docker. Vous auriez à surveiller spécifiquement le conteneur Nginx dans un tel cas.
Voici l'écran Grafana pour la surveillance de l'hôte Docker :
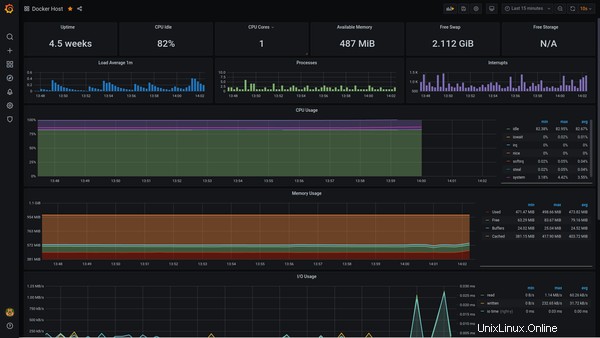
J'avais déjà partagé la capture d'écran de la surveillance des conteneurs au début de cet article :
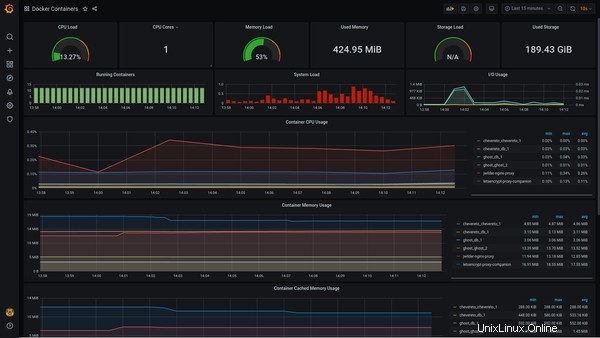
J'espère que ce bref tutoriel vous aidera à configurer cette pile ingénieuse sur votre serveur. Encore une fois, cela est utile pour un seul serveur. Si vous avez des conteneurs sur plusieurs serveurs, vous pouvez utiliser Swarmprom du même développeur.
stefanprodan/swarmpromInstrumentation Docker Swarm avec Prometheus, Grafana, cAdvisor, Node Exporter et Alert Manager - stefanprodan/swarmpromGitHubstefanprodan Si vous avez des commentaires ou des suggestions, n'hésitez pas à partager vos points de vue dans la section ci-dessous.