PostgreSQL La base de données prend en charge plusieurs solutions de réplication pour créer des applications à haute disponibilité, évolutives et tolérantes aux pannes, dont l'une est Write-Ahead Log (WAL ) Expédition. Cette solution permet d'implémenter un serveur de secours à l'aide de l'envoi de journaux basé sur des fichiers ou de la réplication en continu, ou, si possible, d'une combinaison des deux approches.
Avec la réplication en continu, un serveur de base de données de secours (esclave de réplication) est configuré pour se connecter au serveur maître/primaire, qui diffuse WAL les enregistrements vers le standby au fur et à mesure qu'ils sont générés, sans attendre le WAL dossier à remplir.
Par défaut, la réplication en continu est asynchrone où les données sont écrites sur le(s) serveur(s) de secours après qu'une transaction a été validée sur le serveur principal. Cela signifie qu'il y a un petit délai entre la validation d'une transaction sur le serveur maître et le moment où les modifications deviennent visibles sur le serveur de secours. L'un des inconvénients de cette approche est qu'en cas de panne du serveur maître, toute transaction non validée peut ne pas être répliquée, ce qui peut entraîner une perte de données.
Ce guide montre comment configurer un Postgresql 12 réplication de streaming maître-veille sur CentOS 8 . Nous utiliserons des "emplacements de réplication ” pour le standby comme solution pour éviter que le serveur maître ne recycle l'ancien WAL segments avant que le standby ne les ait reçus.
Notez que par rapport à d'autres méthodes, les emplacements de réplication ne conservent que le nombre de segments dont on sait qu'ils sont nécessaires.
Environnement de test :
Ce guide suppose que vous êtes connecté à vos serveurs de base de données maître et de secours en tant que racine via SSH (utilisez Sudo si nécessaire si vous êtes connecté en tant qu'utilisateur normal avec des droits d'administrateur) :
Postgresql master database server: 10.20.20.9 Postgresql standby database server: 10.20.20.8
Les deux serveurs de base de données doivent avoir Postgresql 12 installé, sinon, voir :Comment installer PostgreSQL et pgAdmin dans CentOS 8.
Étape 1 :Configuration du serveur de base de données principal/maître PostgreSQL
1. Sur le serveur maître, passez au compte système postgres et configurez la ou les adresses IP sur lesquelles le serveur maître écoutera les connexions des clients.
Dans ce cas, nous utiliserons * c'est-à-dire tout.
# su - postgres $ psql -c "ALTER SYSTEM SET listen_addresses TO '*';"
L'ENSEMBLE DE MODIFICATION DU SYSTÈME La commande SQL est une fonctionnalité puissante pour modifier les paramètres de configuration d'un serveur, directement avec une requête SQL. Les configurations sont enregistrées dans le postgresql.conf.auto fichier situé à la racine du dossier de données (par exemple /var/lib/pgsql/12/data/ ) et lire les additions à celles stockées dans postgresql.conf . Mais les configurations du premier ont priorité sur celles du dernier et des autres fichiers associés.

Configurer les adresses IP sur PostgreSQL Master
2. Créez ensuite un rôle de réplication qui sera utilisé pour les connexions du serveur de secours au serveur maître, en utilisant le createuser programme. Dans la commande suivante, le -P flag demande un mot de passe pour le nouveau rôle et -e fait écho aux commandes que createuser génère et envoie au serveur de base de données.
# su – postgres $ createuser --replication -P -e replicator $ exit
Créer un utilisateur de réplication sur Pgmaster
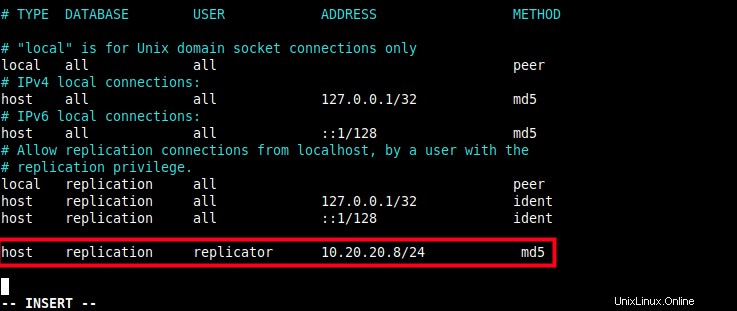
3. Saisissez ensuite l'entrée suivante à la fin de /var/lib/pgsql/12/data/pg_hba.conf fichier de configuration d'authentification client avec le champ de base de données défini sur réplication, comme indiqué dans la capture d'écran.
host replication replicator 10.20.20.8/24 md5
Configurer l'authentification de réplication
4. Redémarrez maintenant Postgres12 service à l'aide de la commande systemctl suivante pour appliquer les modifications.
# systemctl restart postgresql-12.service
5. Ensuite, si vous avez le firewalld service en cours d'exécution, vous devez ajouter le service Postgresql dans la configuration du pare-feu pour autoriser les requêtes du serveur de secours vers le maître.
# firewall-cmd --add-service=postgresql --permanent # firewall-cmd --reload
Étape 2 :Effectuer une sauvegarde de base pour démarrer le serveur de secours
6. Ensuite, vous devez effectuer une sauvegarde de base du serveur maître à partir du serveur de secours ; cela aide à démarrer le serveur de secours. Vous devez arrêter le service postgresql 12 sur le serveur de secours, passer au compte utilisateur postgres, sauvegarder le répertoire de données (/var/lib/pgsql/12/data/ ), puis supprimez tout ce qu'il contient comme indiqué, avant de prendre la sauvegarde de base.
# systemctl stop postgresql-12.service # su - postgres $ cp -R /var/lib/pgsql/12/data /var/lib/pgsql/12/data_orig $ rm -rf /var/lib/pgsql/12/data/*
7. Ensuite, utilisez le pg_basebackup outil pour prendre la sauvegarde de base avec le bon propriétaire (l'utilisateur du système de base de données, c'est-à-dire Postgres , au sein de Postgres compte utilisateur) et avec les bonnes autorisations.
Dans la commande suivante, l'option :
-h– spécifie l'hôte qui est le serveur maître.-D– spécifie le répertoire de données.-U– spécifie l'utilisateur de la connexion.-P– permet le rapport d'avancement.-v– active le mode verbeux.-R– permet la création d'une configuration de récupération :crée un signal de veille fichier et ajouter les paramètres de connexion à postgresql.auto.conf sous le répertoire de données.-X– utilisé pour inclure les fichiers journaux à écriture anticipée requis (fichiers WAL) dans la sauvegarde. Une valeur de flux signifie diffuser le WAL pendant que la sauvegarde est créée.-C– permet la création d'un slot de réplication nommé par l'option -S avant de démarrer la sauvegarde.-S– spécifie le nom de l'emplacement de réplication.
$ pg_basebackup -h 10.20.20.5 -D /var/lib/pgsql/12/data -U replicator -P -v -R -X stream -C -S pgstandby1 $ exit
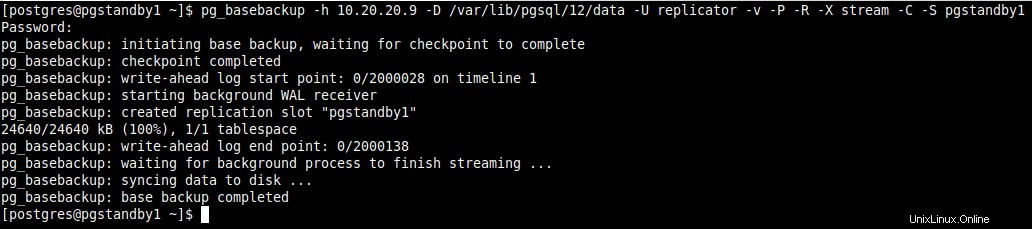
Sauvegarde de base du serveur maître
8. Lorsque le processus de sauvegarde est terminé, le nouveau répertoire de données sur le serveur de secours devrait ressembler à celui de la capture d'écran. Un signal.de.veille est créé et les paramètres de connexion sont ajoutés à postgresql.auto.conf . Vous pouvez lister son contenu à l'aide de la commande ls.
# ls -l /var/lib/pgsql/12/data/
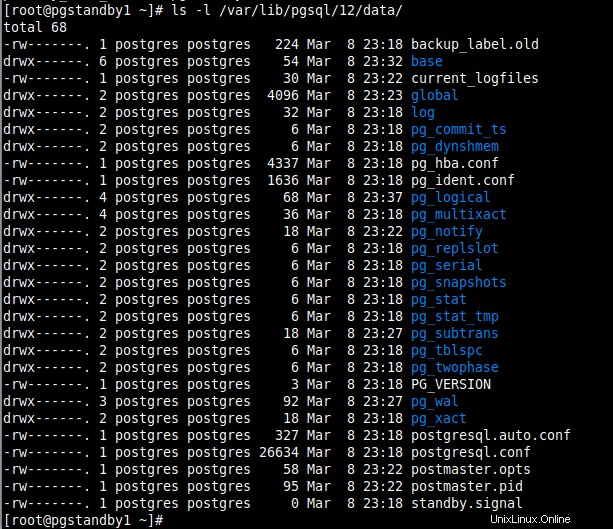
Vérifier le répertoire des données de sauvegarde
Un esclave de réplication fonctionnera en "Hot Standby ” si le mode hot_standby le paramètre est défini sur on (la valeur par défaut) dans postgresql.conf et il y a un signal de veille fichier présent dans le répertoire des données.
9. De retour sur le serveur maître, vous devriez pouvoir voir le slot de réplication appelé pgstandby1 lorsque vous ouvrez les pg_replication_slots voir comme suit.
# su - postgres $ psql -c "SELECT * FROM pg_replication_slots;" $ exit

Créer un emplacement de réplication
10. Pour afficher les paramètres de connexion ajoutés dans le postgresql.auto.conf fichier, utilisez la commande cat.
# cat /var/lib/pgsql/12/data/postgresql.auto.conf

Afficher les paramètres de connexion
11. Commencez maintenant les opérations normales de base de données sur le serveur de secours en démarrant le service PostgreSQL comme suit.
# systemctl start postgresql-12
Étape 3 :Tester la réplication en continu PostgreSQL
12. Une fois qu'une connexion est établie avec succès entre le maître et le standby, vous verrez un WAL récepteur dans le serveur de secours avec un statut de streaming, vous pouvez vérifier cela en utilisant le pg_stat_wal_receiver vue.
$ psql -c "\x" -c "SELECT * FROM pg_stat_wal_receiver;"
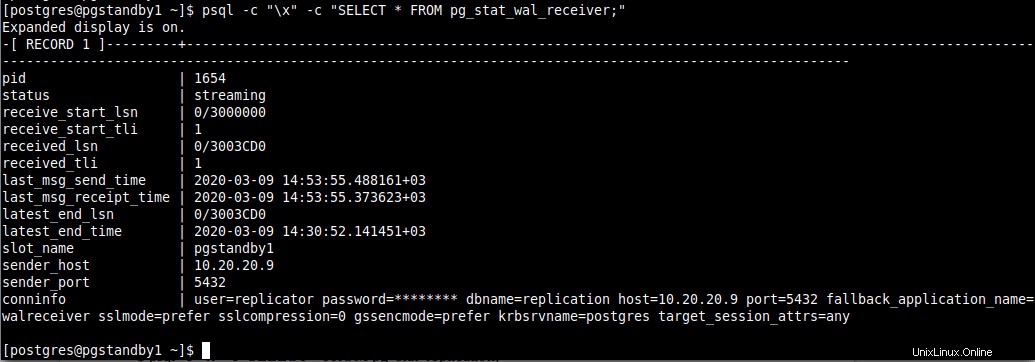
Vérifier le processus du récepteur WAL
et un WAL correspondant processus expéditeur dans le serveur maître/primaire avec un état de streaming et un sync_state d'async, vous pouvez vérifier cette vue pg_stat_replication pg_stat_replication.
$ psql -c "\x" -c "SELECT * FROM pg_stat_replication;"
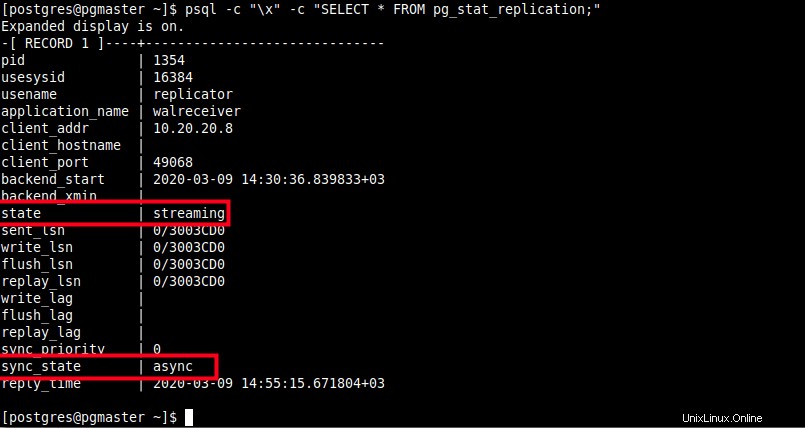
Vérifiez le processus de l'expéditeur WAL dans le maître
D'après la capture d'écran ci-dessus, la réplication en continu est asynchrone. Dans la section suivante, nous montrerons comment activer éventuellement la réplication synchrone.
13. Testez maintenant si la réplication fonctionne correctement en créant une base de données de test sur le serveur maître et vérifiez si elle existe sur le serveur de secours.
[master]postgres=# CREATE DATABASE tecmint;
[standby]postgres=# \l
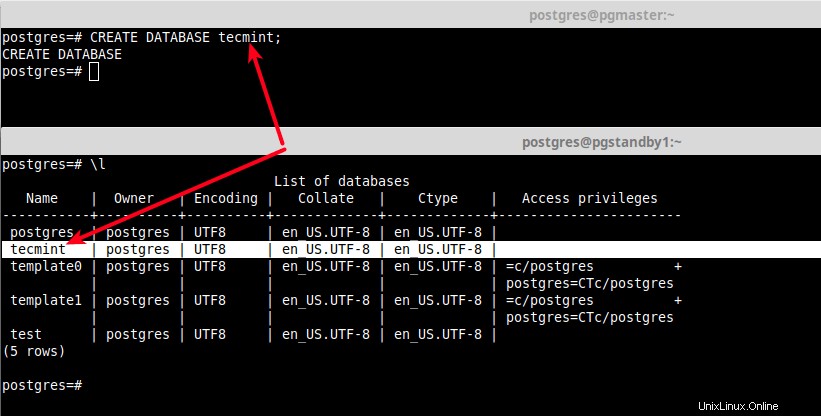
Tester la réplication en continu
Facultatif :Activer la réplication synchrone
14. La réplication synchrone offre la possibilité de valider une transaction (ou d'écrire des données) simultanément dans la base de données principale et dans la base de données de secours/réplica. Il confirme uniquement qu'une transaction est réussie lorsque toutes les modifications apportées par la transaction ont été transférées vers un ou plusieurs serveurs de secours synchrones.
Pour activer la réplication synchrone, le synchronous_commit doit également être défini sur on (qui est la valeur par défaut, donc aucune modification n'est nécessaire) et vous devez également définir les synchronous_standby_names paramètre à une valeur non vide. Pour ce guide, nous le définirons sur tous.
$ psql -c "ALTER SYSTEM SET synchronous_standby_names TO '*';"

Définir les noms de veille de synchronisation dans le maître
15. Rechargez ensuite le service PostgreSQL 12 pour appliquer les nouvelles modifications.
# systemctl reload postgresql-12.service
16. Maintenant, lorsque vous interrogez le WAL processus expéditeur sur le serveur principal une fois de plus, il devrait afficher un état de diffusion et un sync_state de synchronisation .
$ psql -c "\x" -c "SELECT * FROM pg_stat_replication;"
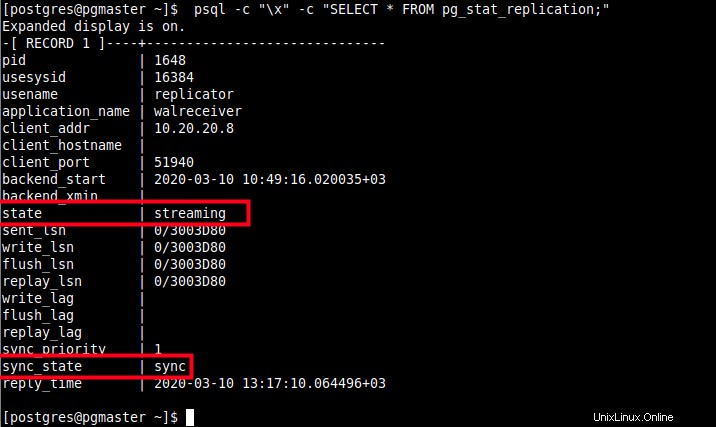
Vérifiez le processus de l'expéditeur WAL dans le maître
Nous sommes arrivés à la fin de ce guide. Nous avons montré comment configurer PostgreSQL 12 réplication de flux de base de données maître-veille dans CentOS 8 . Nous avons également expliqué comment activer la réplication synchrone dans un cluster de bases de données PostgreSQL.
Il existe de nombreuses utilisations de la réplication et vous pouvez toujours choisir une solution qui répond à votre environnement informatique et/ou aux exigences spécifiques à l'application. Pour plus de détails, consultez Log-Shipping Standby Servers dans la documentation PostgreSQL 12.
Partager c'est aimer…Partager sur FacebookPartager sur TwitterPartager sur LinkedinPartager sur Reddit