Qu'est-ce qu'Apache Kafka ?
Kafka est un système de messagerie qui collecte et traite de grandes quantités de données en temps réel, ce qui en fait un composant d'intégration essentiel pour les applications exécutées dans un cluster Kubernetes. L'efficacité des applications déployées dans un cluster peut être encore augmentée avec une plate-forme de streaming d'événements telle que Apache Kafka .
Ce tutoriel détaillé vous montre comment configurer un serveur Kafka sur un cluster Kubernetes.

Comment fonctionne Apache Kafka ?
Apache Kafka est basé sur un modèle de publication-abonnement :
- Producteurs produire des messages et les publier dans des sujets .
- Kafka catégorise les messages en sujets et les stocke afin qu'ils soient immuables.
- Les consommateurs s'abonnent à un sujet spécifique et assimiler les messages fournis par les producteurs.
Les producteurs et les consommateurs dans ce contexte représentent des applications qui produisent des messages événementiels et des applications qui consomment ces messages. Les messages sont stockés sur les courtiers Kafka, triés par sujets définis par l'utilisateur .
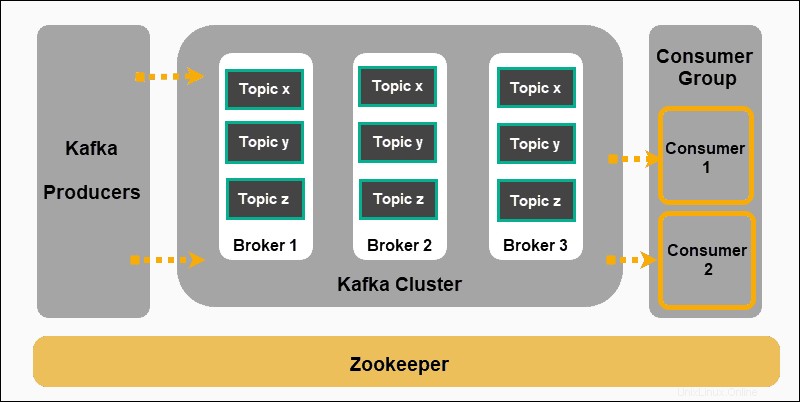
Zookeeper est un composant indispensable d'une configuration Kafka. Il coordonne les producteurs, les courtiers, les consommateurs et les membres des clusters Kafka.
Déployer Zookeeper
Kafka ne peut pas fonctionner sans Zookeeper. Le service Kafka continue de redémarrer jusqu'à ce qu'un déploiement Zookeeper fonctionnel soit détecté.
Déployez Zookeeper au préalable, en créant un fichier YAML zookeeper.yml . Ce fichier démarre un service et un déploiement qui planifient les pods Zookeeper sur un cluster Kubernetes.
Utilisez votre éditeur de texte préféré pour ajouter les champs suivants à zookeeper.yml :
apiVersion: v1
kind: Service
metadata:
name: zk-s
labels:
app: zk-1
spec:
ports:
- name: client
port: 2181
protocol: TCP
- name: follower
port: 2888
protocol: TCP
- name: leader
port: 3888
protocol: TCP
selector:
app: zk-1
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: zk-deployment-1
spec:
template:
metadata:
labels:
app: zk-1
spec:
containers:
- name: zk1
image: bitnami/zookeeper
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_ID
value: "1"
- name: ZOOKEEPER_SERVER_1
value: zk1
Exécutez la commande suivante sur votre cluster Kubernetes pour créer le fichier de définition :
kubectl create -f zookeeper.ymlCréer un service Kafka
Nous devons maintenant créer un fichier de définition de service Kafka. Ce fichier gère les déploiements de Kafka Broker en équilibrant la charge des nouveaux pods Kafka. Un kafka-service.yml de base le fichier contient les éléments suivants :
apiVersion: v1
kind: Service
metadata:
labels:
app: kafkaApp
name: kafka
spec:
ports:
-
port: 9092
targetPort: 9092
protocol: TCP
-
port: 2181
targetPort: 2181
selector:
app: kafkaApp
type: LoadBalancer
Une fois le fichier enregistré, créez le service en saisissant la commande suivante :
kubectl create -f kafka-service.ymlDéfinir le contrôleur de réplication Kafka
Créez un .yml supplémentaire fichier pour servir de contrôleur de réplication pour Kafka. Un fichier de contrôleur de réplication, dans notre exemple kafka-repcon.yml, contient les champs suivants :
---
apiVersion: v1
kind: ReplicationController
metadata:
labels:
app: kafkaApp
name: kafka-repcon
spec:
replicas: 1
selector:
app: kafkaApp
template:
metadata:
labels:
app: kafkaApp
spec:
containers:
-
command:
- zookeeper-server-start.sh
- /config/zookeeper.properties
image: "wurstmeister/kafka"
name: zk1
ports:
-
containerPort: 2181
Enregistrez le fichier de définition du contrôleur de réplication et créez-le à l'aide de la commande suivante :
kubectl create -f kafka-repcon.ymlDémarrer le serveur Kafka
Les propriétés de configuration d'un serveur Kafka sont définies dans le config/server.properties dossier. Comme nous avons déjà configuré le serveur Zookeeper, démarrez le serveur Kafka avec :
kafka-server-start.sh config/server.propertiesComment créer un sujet Kafka
Kafka a un utilitaire de ligne de commande appelé kafka-topics.sh . Utilisez cet utilitaire pour créer des rubriques sur le serveur. Ouvrez une nouvelle fenêtre de terminal et tapez :
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-NameNous avons créé un sujet nommé Nom du sujet avec une seule partition et une instance dupliquée.
Comment démarrer un producteur de Kafka
Le config/server.properties Le fichier contient l'ID du port du courtier. Le courtier de l'exemple écoute sur le port 9092. Il est possible de spécifier le port d'écoute directement à l'aide de la ligne de commande :
kafka-console-producer.sh --topic kafka-on-kubernetes --broker-list localhost:9092 --topic Topic-Name Utilisez maintenant le terminal pour ajouter plusieurs lignes de messages.
Comment démarrer un consommateur Kafka
Comme pour les propriétés Producer, les paramètres Consumer par défaut sont spécifiés dans config/consumer.properties dossier. Ouvrez une nouvelle fenêtre de terminal et tapez la commande pour consommer les messages :
kafka-console-consumer.sh --topic Topic-Name --from-beginning --zookeeper localhost:2181
Le --from-beginning La commande répertorie les messages par ordre chronologique. Vous pouvez désormais saisir des messages depuis le terminal du producteur et les voir apparaître sur le terminal du consommateur.
Comment faire évoluer un cluster Kafka
Utilisez le terminal de commande et administrez directement le cluster Kafka à l'aide de kubectl . Entrez la commande suivante et mettez à l'échelle votre cluster Kafka rapidement en augmentant le nombre de pods de un (1) à six (6) :
kubectl scale rc kafka-rc --replicas=6