Présentation
Ce didacticiel est le premier d'une série d'articles axés sur Kubernetes et le concept de déploiement de conteneurs. Kubernetes est un outil utilisé pour gérer des clusters d'applications conteneurisées. En informatique, ce processus est souvent appelé orchestration .
L'analogie avec un orchestre de musique est, à bien des égards, appropriée. Tout comme le ferait un chef d'orchestre, Kubernetes coordonne de nombreux microservices qui forment ensemble une application utile. Kubernetes surveille automatiquement et en permanence le cluster et apporte des ajustements à ses composants.
La compréhension de l'architecture Kubernetes est cruciale pour le déploiement et la maintenance d'applications conteneurisées.
Qu'est-ce que Kubernetes ?
Kubernetes ou k8s en bref, est un système d'automatisation du déploiement d'applications. Les applications modernes sont dispersées dans les clouds, les machines virtuelles et les serveurs. L'administration manuelle des applications n'est plus une option viable.
K8s transforme les machines virtuelles et physiques en une surface d'API unifiée. Un développeur peut ensuite utiliser l'API Kubernetes pour déployer, mettre à l'échelle et gérer des applications conteneurisées.
Son architecture fournit également un cadre flexible pour les systèmes distribués. K8s orchestre automatiquement la mise à l'échelle et les basculements pour vos applications et fournit des modèles de déploiement.
Il aide à gérer les conteneurs qui exécutent les applications et garantit qu'il n'y a pas de temps d'arrêt dans un environnement de production. Par exemple, si un conteneur tombe en panne, un autre conteneur prend automatiquement sa place sans que l'utilisateur final ne s'en aperçoive.
Kubernetes n'est pas seulement un système d'orchestration. Il s'agit d'un ensemble de processus de contrôle indépendants et interconnectés. Son rôle est de travailler en permanence sur l'état actuel et de faire avancer les processus dans la direction souhaitée.
Consultez notre article Qu'est-ce que Kubernetes si vous souhaitez en savoir plus sur l'orchestration des conteneurs.
Architecture et composants Kubernetes
Kubernetes a une architecture décentralisée qui ne gère pas les tâches de manière séquentielle. Il fonctionne sur la base d'un modèle déclaratif et implémente le concept d'état souhaité . » Ces étapes illustrent le processus de base de Kubernetes :
- Un administrateur crée et place l'état souhaité d'une application dans un fichier manifeste.
- Le fichier est fourni au serveur d'API Kubernetes à l'aide d'une CLI ou d'une interface utilisateur. L'outil de ligne de commande par défaut de Kubernetes s'appelle kubectl . Si vous avez besoin d'une liste complète des commandes kubectl, consultez notre aide-mémoire Kubectl.
- Kubernetes stocke le fichier (l'état souhaité d'une application) dans une base de données appelée Key-Value Store (etcd) .
- Kubernetes implémente ensuite l'état souhaité sur toutes les applications pertinentes au sein du cluster.
- Kubernetes surveille en permanence les éléments du cluster pour s'assurer que l'état actuel de l'application ne diffère pas de l'état souhaité.
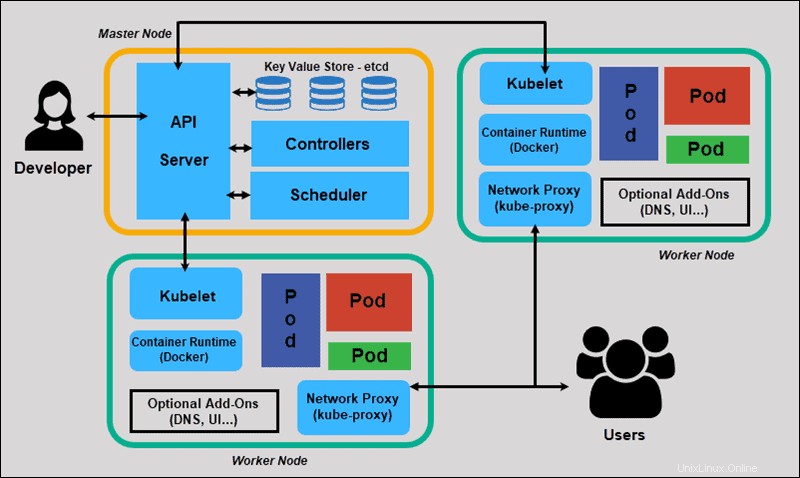
Nous allons maintenant explorer les composants individuels d'un cluster Kubernetes standard pour comprendre le processus plus en détail.
Qu'est-ce qu'un nœud maître dans l'architecture Kubernetes ?
Le maître Kubernetes (nœud maître) reçoit les entrées d'une CLI (interface de ligne de commande) ou d'une interface utilisateur (interface utilisateur) via une API. Ce sont les commandes que vous fournissez à Kubernetes.
Vous définissez les pods, les jeux de réplicas et les services que vous souhaitez que Kubernetes maintienne. Par exemple, quelle image de conteneur utiliser, quels ports exposer et combien de répliques de pod exécuter.
Vous fournissez également les paramètres de l'état souhaité pour la ou les applications exécutées dans ce cluster.
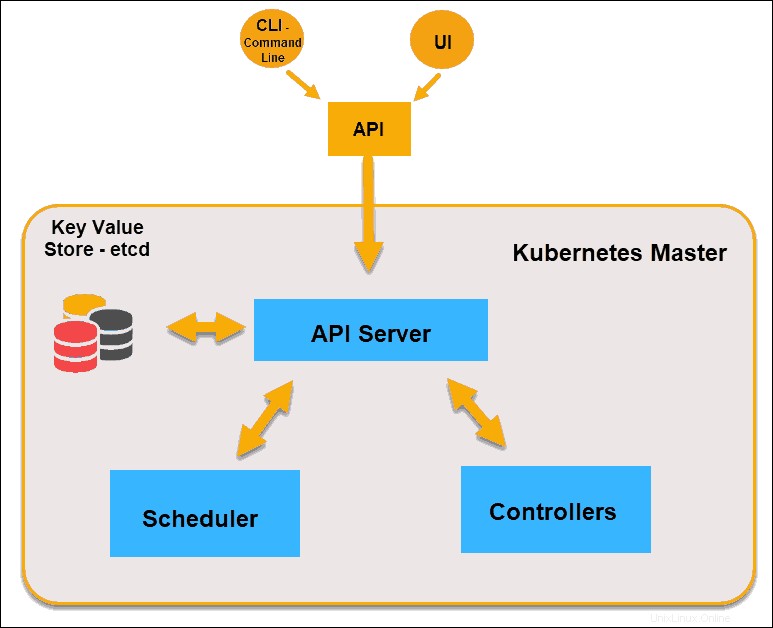
Nœud maître Kubernetes
Serveur API
Le serveur d'API est le frontal du plan de contrôle et le seul composant du plan de contrôle avec lequel nous interagissons directement. Les composants système internes, ainsi que les composants utilisateur externes, communiquent tous via la même API.
Magasin clé-valeur (etcd)
Le magasin clé-valeur, également appelé etcd , est une base de données utilisée par Kubernetes pour sauvegarder toutes les données du cluster. Il stocke l'intégralité de la configuration et de l'état du cluster. Le nœud maître interroge etcd pour récupérer les paramètres de l'état des nœuds, des pods et des conteneurs.
Contrôleur
Le rôle du contrôleur est d'obtenir l'état souhaité à partir du serveur API. Il vérifie l'état actuel des nœuds qu'il est chargé de contrôler, détermine s'il existe des différences et les résout, le cas échéant.
Planificateur
Un planificateur surveille les nouvelles requêtes provenant du serveur API et les affecte aux nœuds sains. Il classe la qualité des nœuds et déploie les pods sur le nœud le mieux adapté. S'il n'y a pas de nœuds appropriés, les pods sont mis en attente jusqu'à ce qu'un tel nœud apparaisse.
Qu'est-ce qu'un nœud de travail dans l'architecture Kubernetes ?
Les nœuds de travail écoutent le serveur API pour les nouvelles affectations de travail ; ils exécutent les affectations de travail, puis signalent les résultats au nœud maître Kubernetes.
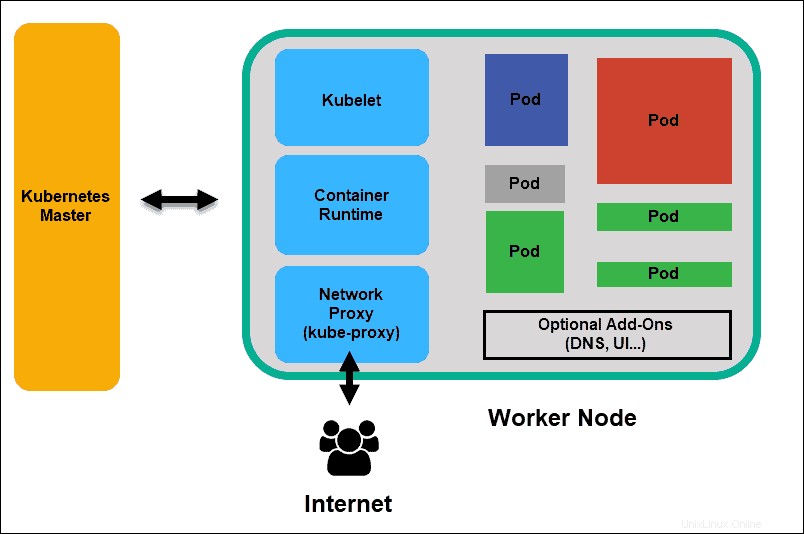
Nœud de travail Kubernetes
Kubelet
Le kubelet s'exécute sur chaque nœud du cluster. C'est l'agent principal de Kubernetes. En installant kubelet, le processeur, la RAM et le stockage du nœud font partie du cluster plus large. Il surveille les tâches envoyées par le serveur API, exécute la tâche et rend compte au maître. Il surveille également les pods et signale au panneau de contrôle si un pod n'est pas entièrement fonctionnel. Sur la base de ces informations, le maître peut alors décider comment allouer les tâches et les ressources pour atteindre l'état souhaité.
Exécution du conteneur
L'environnement d'exécution du conteneur extrait des images d'un registre d'images de conteneurs et démarre et arrête les conteneurs. Un logiciel ou un plug-in tiers, tel que Docker, remplit généralement cette fonction.
Kube-proxy
Le proxy kube s'assure que chaque nœud obtient son adresse IP, implémente des iptables locaux et des règles pour gérer le routage et l'équilibrage de charge du trafic.
Cosse
Un pod est le plus petit élément de planification dans Kubernetes. Sans cela, un conteneur ne peut pas faire partie d'un cluster. Si vous devez faire évoluer votre application, vous ne pouvez le faire qu'en ajoutant ou en supprimant des pods.
Le pod sert de "wrapper" pour un seul conteneur avec le code d'application. En fonction de la disponibilité des ressources, le maître planifie le pod sur un nœud spécifique et se coordonne avec l'exécution du conteneur pour lancer le conteneur.
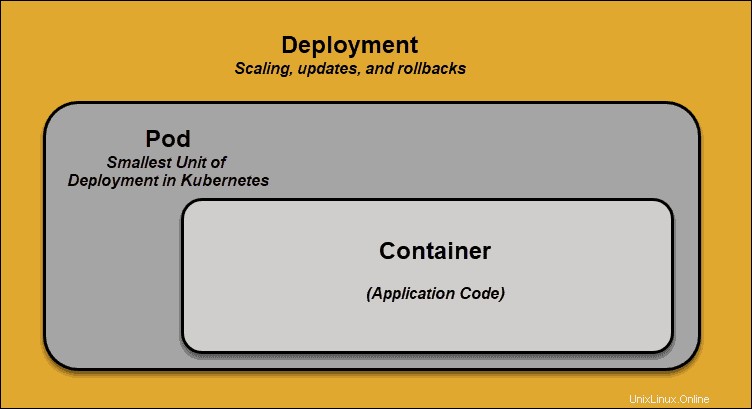
Dans les cas où les pods échouent de manière inattendue dans l'exécution de leurs tâches, Kubernetes n'essaie pas de les réparer. Au lieu de cela, il crée et démarre un nouveau pod à sa place. Ce nouveau pod est un réplica, à l'exception du DNS et de l'adresse IP. Cette fonctionnalité a eu un impact profond sur la façon dont les développeurs conçoivent les applications.
En raison de la nature flexible de l'architecture Kubernetes, les applications n'ont plus besoin d'être liées à une instance particulière d'un pod. Au lieu de cela, les applications doivent être conçues de manière à ce qu'un pod entièrement nouveau, créé n'importe où dans le cluster, puisse prendre sa place de manière transparente. Pour faciliter ce processus, Kubernetes utilise des services .
Services Kubernetes
Les gousses ne sont pas constantes. L'une des meilleures fonctionnalités offertes par Kubernetes est que les pods qui ne fonctionnent pas sont automatiquement remplacés par de nouveaux.
Cependant, ces nouveaux pods ont un ensemble d'adresses IP différent. Cela peut entraîner des problèmes de traitement et une perte d'adresses IP car les adresses IP ne correspondent plus. Si elle n'était pas surveillée, cette propriété rendrait les pods très peu fiables.
Des services sont introduits pour fournir un réseau fiable en apportant des adresses IP et des noms DNS stables au monde instable des pods.
En contrôlant le trafic entrant et sortant du pod, un service Kubernetes fournit un point de terminaison réseau stable - une adresse IP, un DNS et un port fixes. Grâce à un service, n'importe quel pod peut être ajouté ou supprimé sans craindre que les informations réseau de base ne changent de quelque manière que ce soit.
Comment fonctionnent les services Kubernetes ?
Les pods sont associés à des services via des paires clé-valeur appelées libellés et sélecteurs . Un service découvre automatiquement un nouveau pod avec des étiquettes qui correspondent au sélecteur.
Ce processus ajoute de manière transparente de nouveaux pods au service et, en même temps, supprime les pods terminés du cluster.
Par exemple, si l'état souhaité comprend trois répliques d'un pod et un nœud exécutant un réplica échoue , l'état actuel est réduit à deux pods. Kubernetes observe que l'état souhaité est de trois pods. Il planifie ensuite une nouvelle réplique pour prendre la place du pod défaillant et l'affecte à un autre nœud du cluster.
Il en va de même lors de la mise à jour ou de la mise à l'échelle de l'application en ajoutant ou en supprimant des pods. Une fois que nous avons mis à jour l'état souhaité, Kubernetes remarque l'écart et ajoute ou supprime des pods pour correspondre au fichier manifeste. Le panneau de configuration Kubernetes enregistre, implémente et exécute des boucles de réconciliation en arrière-plan qui vérifient en permanence si l'environnement correspond aux exigences définies par l'utilisateur.
Qu'est-ce que le déploiement de conteneur ?
Pour bien comprendre comment et ce que Kubernetes orchestre, nous devons explorer le concept de déploiement de conteneurs .
Déploiement traditionnel
Initialement, les développeurs déployaient des applications sur des serveurs physiques individuels. Ce type de déploiement a posé plusieurs défis. Le partage des ressources physiques signifiait qu'une application pouvait occuper la majeure partie de la puissance de traitement, limitant les performances des autres applications sur la même machine.
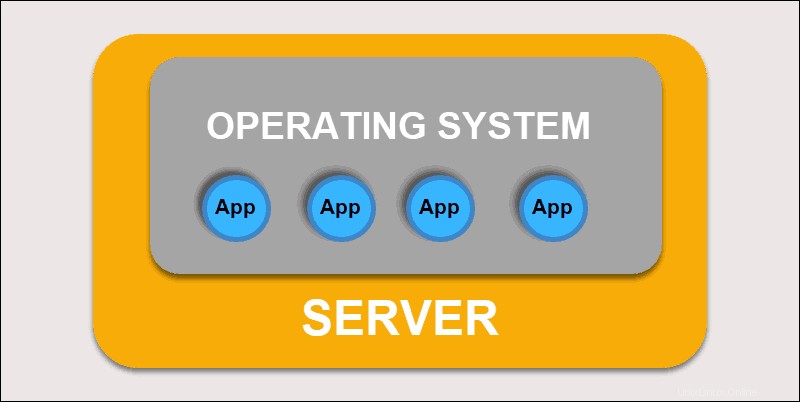
Déploiement traditionnel
L'extension de la capacité matérielle prend beaucoup de temps, ce qui augmente les coûts. Pour résoudre les limitations matérielles, les entreprises ont commencé à virtualiser les machines physiques.
Déploiement virtualisé
Le déploiement virtualisé vous permet de créer des environnements virtuels isolés, des machines virtuelles (VM) , sur un seul serveur physique. Cette solution isole les applications au sein d'une machine virtuelle, limite l'utilisation des ressources et augmente la sécurité. Une application ne peut plus accéder librement aux informations traitées par une autre application.
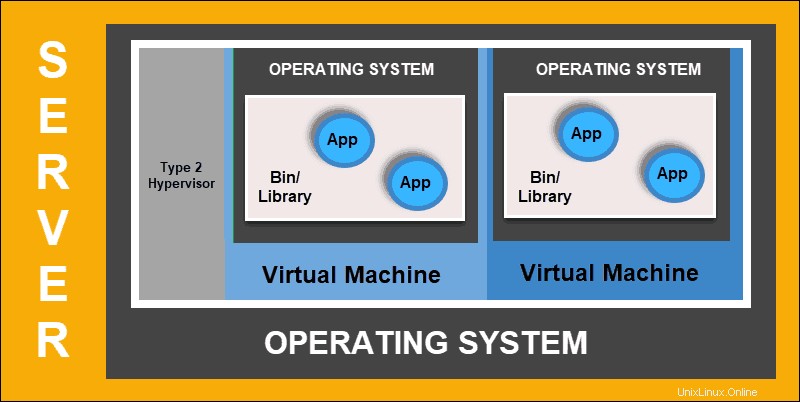
Déploiement virtualisé
Les déploiements virtualisés vous permettent d'évoluer rapidement et de répartir les ressources d'un seul serveur physique, de mettre à jour à volonté et de contrôler les coûts matériels. Chaque machine virtuelle a son système d'exploitation et peut exécuter tous les systèmes nécessaires sur le matériel virtualisé.
Déploiement de conteneurs
Le déploiement de conteneurs est la prochaine étape dans la volonté de créer un modèle plus flexible et efficace. Tout comme les machines virtuelles, les conteneurs ont une mémoire individuelle, des fichiers système et un espace de traitement. Cependant, l'isolement strict n'est plus un facteur limitant.
Plusieurs applications peuvent désormais partager le même système d'exploitation sous-jacent. Cette fonctionnalité rend les conteneurs beaucoup plus efficaces que les machines virtuelles complètes. Ils sont portables sur les clouds, différents appareils et presque toutes les distributions de système d'exploitation.
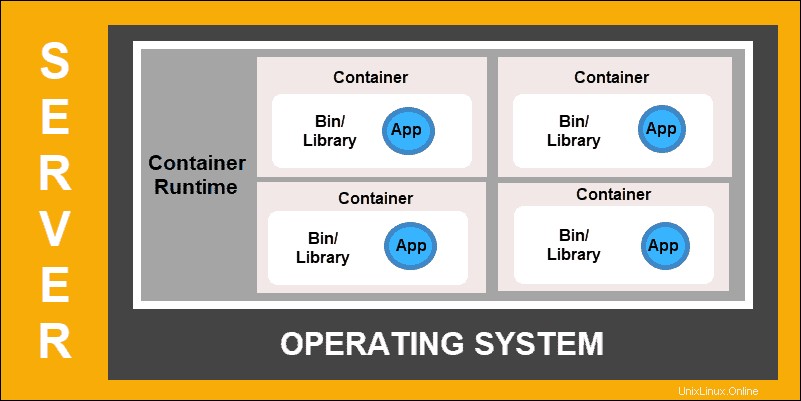
Déploiement de conteneurs
La structure du conteneur permet également aux applications de s'exécuter en tant que parties plus petites et indépendantes. Ces pièces peuvent ensuite être déployées et gérées dynamiquement sur plusieurs machines. La structure élaborée et la segmentation des tâches sont trop complexes pour être gérées manuellement.
Une solution d'automatisation, telle que Kubernetes, est nécessaire pour gérer efficacement toutes les pièces mobiles impliquées dans ce processus.