
Dans ce didacticiel, nous allons vous montrer comment installer Apache Hadoop sur Debian 11. Pour ceux d'entre vous qui ne le savaient pas, Apache Hadoop est une plate-forme logicielle open source basée sur Java qui gère le traitement et le stockage des données pour les applications Big Data. Il est conçu pour passer d'un seul serveur à des milliers de machines, chacune offrant un calcul et un stockage locaux.
Cet article suppose que vous avez au moins des connaissances de base sur Linux, que vous savez utiliser le shell et, plus important encore, que vous hébergez votre site sur votre propre VPS. L'installation est assez simple et suppose que vous s'exécutent dans le compte root, sinon vous devrez peut-être ajouter 'sudo ‘ aux commandes pour obtenir les privilèges root. Je vais vous montrer l'installation pas à pas d'Apache Hadoop sur une Debian 11 (Bullseye).
Prérequis
- Un serveur exécutant l'un des systèmes d'exploitation suivants :Debian 11 (Bullseye).
- Il est recommandé d'utiliser une nouvelle installation du système d'exploitation pour éviter tout problème potentiel.
- Accès SSH au serveur (ou ouvrez simplement Terminal si vous êtes sur un ordinateur).
- Un
non-root sudo userou l'accès à l'root user. Nous vous recommandons d'agir en tant qu'non-root sudo user, cependant, car vous pouvez endommager votre système si vous ne faites pas attention lorsque vous agissez en tant que root.
Installer Apache Hadoop sur Debian 11 Bullseye
Étape 1. Avant d'installer un logiciel, il est important de s'assurer que votre système est à jour en exécutant le suivant apt commandes dans le terminal :
mises à jour de sudo aptmises à jour de sudo apt
Étape 2. Installation de Java.
Apache Hadoop est une application basée sur Java. Vous devrez donc installer Java sur votre système :
sudo apt install default-jdk default-jre
Vérifiez l'installation de Java :
version Java
Étape 3. Création d'un utilisateur Hadoop.
Exécutez la commande suivante pour créer un nouvel utilisateur avec le nom Hadoop :
adduser hadoop
Ensuite, passez à l'utilisateur Hadoop une fois l'utilisateur créé :
su - hadoop
Il est maintenant temps de générer une clé ssh car Hadoop nécessite un accès ssh pour gérer son nœud, machine distante ou locale donc pour notre nœud unique de la configuration de Hadoop nous configurons de sorte que nous ayons accès à l'hôte local :
ssh-keygen -t rsa
Après cela, donnez la permission au fichier authorized_keys :
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
Ensuite, vérifiez la connexion SSH sans mot de passe avec la commande suivante :
ssh votre-adresse-IP-serveur
Étape 4. Installer Apache Hadoop sur Debian 11.
Tout d'abord, passez à l'utilisateur Hadoop et téléchargez la dernière version de Hadoop à partir de la page officielle en utilisant le wget suivant commande :
su - hadoopwget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
Ensuite, extrayez le fichier téléchargé avec la commande suivante :
tar -xvzf hadoop-3.3.1.tar.gz
Une fois qu'il est décompressé, changez le répertoire actuel pour le dossier Hadoop :
su rootcd /home/hadoopmv hadoop-3.3.1 /usr/local/hadoop
Ensuite, créez un répertoire pour stocker les journaux avec la commande suivante :
mkdir /usr/local/hadoop/logs
Changez la propriété du répertoire Hadoop en Hadoop :
chown -R hadoop:hadoop /usr/local/hadoopsu hadoop
Après cela, nous configurons les variables d'environnement Hadoop :
nano ~/.bashrc
Ajoutez la configuration suivante :
export HADOOP_HOME =/ usr / local / hadoopexport HADOOP_INSTALL =$ HADOOP_HOMEexport HADOOP_MAPRED_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_HOME =$ HADOOP_HOMEexport HADOOP_HDFS_HOME =$ HADOOP_HOMEexport YARN_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR =$ HADOOP_HOME / lib / nativeexport PATH =$ PATH:$ HADOOP_HOME / sbin:$HADOOP_HOME/binexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Enregistrez et fermez le fichier. Ensuite, activez les variables d'environnement :
source ~/.bashrc
Étape 5. Configurez Apache Hadoop.
- Configurer les variables d'environnement Java :
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Ajoutez la configuration suivante :
exporter JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 exporter HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Ensuite, nous devons télécharger le fichier d'activation Javax :
cd /usr/local/hadoop/libsudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jarVérifiez la version d'Apache Hadoop :
version hadoopSortie :
Hadoop 3.3.1
- Configurez le fichier core-site.xml :
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Ajoutez le fichier suivant :
fs.default.name hdfs://0.0.0.0:9000 L'URI du système de fichiers par défaut
- Configurez le fichier hdfs-site.xml :
Avant de configurer, créez un répertoire pour stocker les métadonnées du nœud :
mkdir -p /home/hadoop/hdfs/{namenode,datanode}chown -R hadoop:hadoop /home/hadoop/hdfs Ensuite, modifiez le hdfs-site.xml fichier et définissez l'emplacement du répertoire :
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Ajoutez la ligne suivante :
dfs.replication 1 dfs.name.dir fichier :///home/hadoop/hdfs/namenode dfs.data.dir file:///home/hadoop/hdfs/datanode
- Configurer le fichier mapred-site.xml :
Maintenant, nous modifions le mapred-site.xml fichier :
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Ajoutez la configuration suivante :
mapreduce.framework.name fil
- Configurer le fichier yarn-site.xml :
Vous devrez modifier le yarn-site.xml fichier et définir les paramètres liés à YARN :
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Ajoutez la configuration suivante :
yarn.nodemanager.aux-services mapreduce_shuffle
- Formater le nœud de nom HDFS.
Exécutez la commande suivante pour formater le Hadoop Namenode :
hdfs namenode -format
- Démarrez le cluster Hadoop.
Démarrons maintenant le NameNode et le DataNode avec la commande suivante :
start-dfs.sh
Démarrez ensuite les gestionnaires de ressources et de nœuds YARN :
start-yarn.sh
Vous pouvez maintenant les vérifier avec la commande suivante :
jps
Sortie :
hadoop@idroot.us :~$ jps58000 NameNode54697 DataNode55365 ResourceManager55083 SecondaryNameNode58556 Jps55365 NodeManager
Étape 6. Accéder à l'interface Web Hadoop.
Une fois l'installation réussie, ouvrez votre navigateur Web et accédez à Apache Hadoop à l'aide de l'URL http://your-server-ip-address:9870 . Vous allez être redirigé vers l'interface web Hadoop :
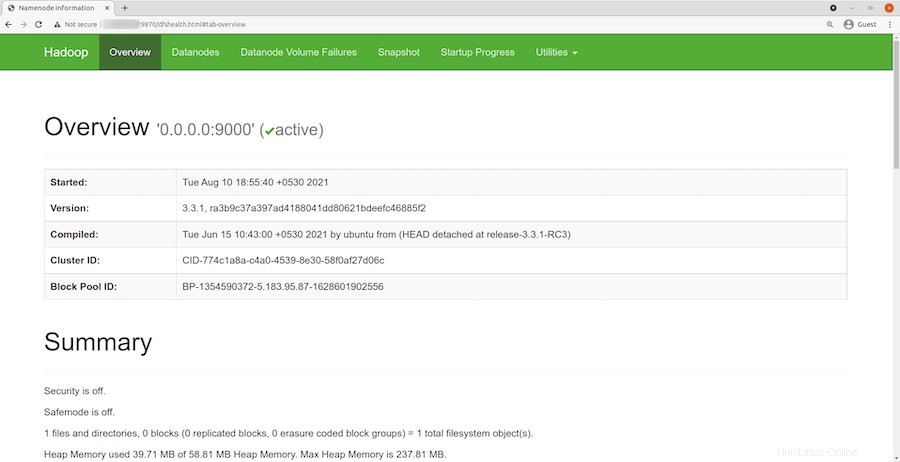
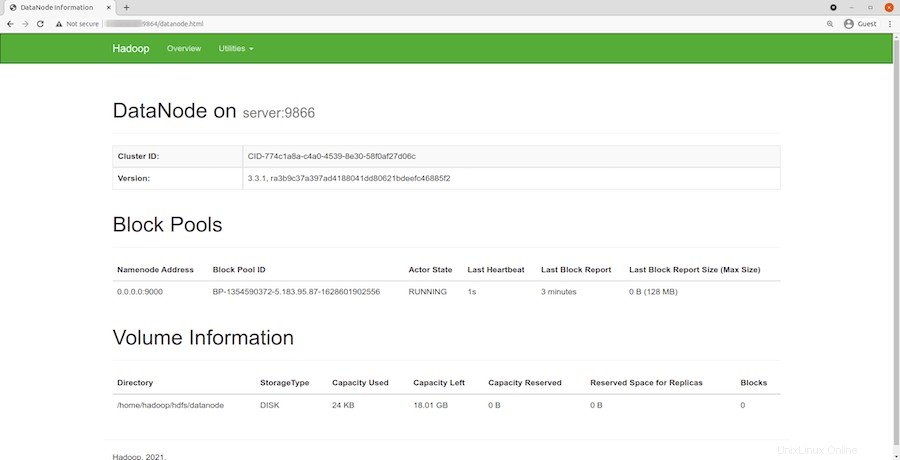
Naviguez sur votre URL ou IP localhost pour accéder aux DataNodes individuels :http://your-server-ip-address:9864
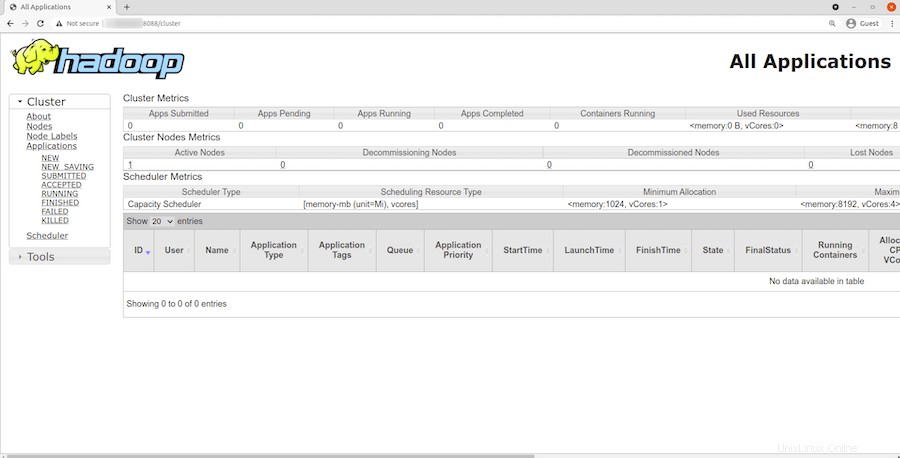
Pour accéder au gestionnaire de ressources YARN, utilisez l'URL http://your-server-ip-adddress:8088 . Vous devriez voir l'écran suivant :
Félicitations ! Vous avez installé Hadoop avec succès. Merci d'avoir utilisé ce didacticiel pour installer la dernière version d'Apache Hadoop sur Debian 11 Bullseye. Pour obtenir de l'aide supplémentaire ou des informations utiles, nous vous recommandons de consulter la version officielle d'Apache site Web.