Voici les étapes pour installer Apache Kafka sur le serveur Rocky Linux ou AlmaLinux 8, bien sûr, en utilisant le terminal de commande.
Apache Kafka est un logiciel open source qui permet le stockage et le traitement de flux de données via une plateforme de streaming distribuée. En termes simples, Apache Kafka est une plate-forme de diffusion d'événements qui agit comme un système de messagerie entre l'expéditeur et le destinataire avec une tolérance élevée aux pannes et des capacités d'évolutivité, car elle est basée sur une architecture distribuée optimisée pour la même chose.
Eh bien, ce système a été initialement développé par LinkedIn en tant que file d'attente de messages, cependant, étant un projet d'Apache Software Foundation, il est open source et une plate-forme de streaming puissante avec une variété de fonctions. Il offre des interfaces pour écrire des données sur des clusters Kafka, pour lire des données ou pour importer et exporter des données vers et depuis des systèmes tiers. En raison de sa faible latence et de son débit élevé, il peut traiter facilement les flux en temps réel.
Les interfaces permettent également aux utilisateurs de charger des flux de données depuis des systèmes tiers ou de les exporter vers ces systèmes. Cela rend Apache Kafka adapté à de grandes quantités de données et d'applications dans l'environnement Big Data.
Il peut être utilisé pour un large éventail d'applications telles que le suivi de l'activité du site Web en temps réel, la surveillance des applications distribuées, l'agrégation de fichiers journaux de différentes sources, la synchronisation des données dans des systèmes distribués, la formation de modèles en temps réel aide à l'apprentissage automatique, et plus…
Apache Kafka propose ces quatre interfaces principales (APIs – Application Programming Interfaces). En savoir plus sur chaque API sur la page de documentation officielle :
- API d'administration
- API Producteur
- API consommateur
- API de flux
- Connecter l'API
De quoi avez-vous besoin pour suivre ce tutoriel :
- Rocky ou AlmaLinux 8 ou tout autre serveur basé sur RHEL, si possible, nettoyez-en un.
- Un utilisateur avec un accès sudo.
Étapes pour installer Apache Kafka sur Rocky Linux 8
Le guide fourni s'applique à tous les systèmes Linux basés sur RHEL 8, y compris CentOS 8 et Oracle Linux 8 pour installer Kafka si nécessaire.
1. Système de mise à jour
Eh bien, avant d'aller plus loin, exécutez la commande de mise à jour du système pour vous assurer que tous les packages installés sont à jour. Pour cela, exécutez la commande ci-dessous, cela actualisera également le cache du référentiel.
sudo dnf update
2. Installer Java
Apache Kafka a besoin de Java pour fonctionner, nous devons donc d'abord l'installer sur notre environnement local et il doit être égal ou supérieur à Java 8. Eh bien, nous n'avons pas besoin d'ajouter un troisième référentiel car le package pour obtenir JAVA est déjà là sur le référentiel de base du système, utilisons donc la commande donnée.
Pour Java 11
sudo dnf install java-11-openjdk
Eh bien, pour la dernière version telle que la 16, utilisez les commandes ci-dessous :
sudo dnf install epel-release
sudo dnf install java-latest-openjdk
3. Téléchargez la dernière version d'Apache Kafka sur Rocky Linux 8 ou Almalinux
Apache Kafka est disponible sous forme de fichier tarball sur le site officiel. Par conséquent, rendez-vous sur le site officiel et téléchargez la dernière version. Vous pouvez également copier n'importe quel lien miroir et utiliser le wget commande à télécharger en ligne de commande, comme nous l'avons fait ici :
sudo dnf install wget nano
wget https://dlcdn.apache.org/kafka/3.0.0/kafka_2.13-3.0.0.tgz
Extraire le fichier téléchargé
tar -xf kafka_*tgz
Pour voir le fichier :
ls
Déplacez-le vers /usr/local/ juste pour nous assurer que nous ne supprimerons pas le dossier Kafka accidentellement.
sudo mv kafka_2.13-3.0.0/ /usr/local/kafka
4. Créer un service système pour Zookeeper et Kafka
Bien que juste pour le test, vous pouvez exécuter directement le script de service Zookeeper et Kafka, manuellement, cependant, pour le serveur de production, nous devons l'exécuter en arrière-plan. Par conséquent, créez des unités systemd pour les deux scripts.
Créer un fichier système Zookeeper
Selon le site Web officiel à l'avenir, Kafka n'aura pas besoin de Zookeeper, cependant, lors de la rédaction de cet article, nous en avons besoin. Alors, créez d'abord un fichier de service pour Zookeeper.
sudo nano /etc/systemd/system/zookeeper.service
Copiez-Collez les lignes ci-dessous :
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/bin/bash /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/bin/bash /usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Enregistrer et fermez le fichier en appuyant sur Ctr+O , appuyez sur Entrée clé, puis quittez-la en utilisant Ctrl + X .
Maintenant, créez le fichier Kafka systemd
sudo nano /etc/systemd/system/kafka.service
Collez les lignes suivantes. Remarque – Modifier le Java_Home , au cas où vous utiliseriez une autre version. Pour le trouver, vous pouvez utiliser la commande - sudo find /usr/ -name *jdk
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/jre-11-openjdk" ExecStart=/usr/bin/bash /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/bin/bash /usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Enregistrez le fichier avec Ctrl+O, appuyez sur Entrée clé, puis utilisez Ctrl+X pour quitter le même.
Recharger le démon
Pour refléter les modifications apportées ci-dessus dans le système et utiliser les fichiers de service, rechargez le démon système une fois.
sudo systemctl daemon-reload
5. Démarrer Zookeeper et Kafka Server sur Rocky Linux
Maintenant, commençons et activons les deux services de serveur pour nous assurer qu'ils seront également actifs même après le redémarrage du système.
sudo systemctl start zookeeper sudo systemctl start kafka
sudo systemctl enable zookeeper sudo systemctl enable kafka
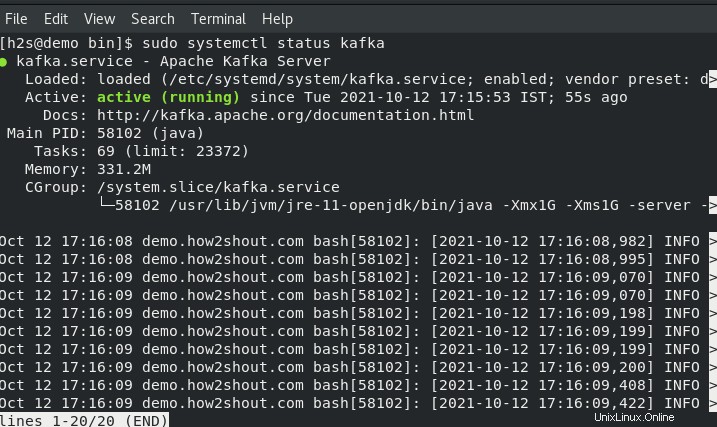
Vérifier l'état des services :
sudo systemctl status zookeeper
sudo systemctl status kafka
6. Créer des sujets de test sur Kafka – Rocky ou AlmaLinux
Kafka nous permet de lire, d'écrire, de stocker et de traiter des événements sur les différentes machines, cependant, pour stocker ces événements, nous avons besoin d'un endroit ou d'un dossier appelé "Sujets “. Ainsi, sur votre terminal serveur, créez au moins un sujet à l'aide de la commande suivante. En utilisant la même chose plus tard, vous pourrez créer autant de sujets que vous le souhaitez.
Disons que notre premier nom de sujet est - testevent . Donc pour créer le même run :
Allez dans votre répertoire Kafka.
cd /usr/local/kafka/
Et utilisez le script Topics :
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testevent

Après avoir créé autant de sujets que vous le souhaitez, pour tous les lister, nous pouvons utiliser la commande suivante :
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
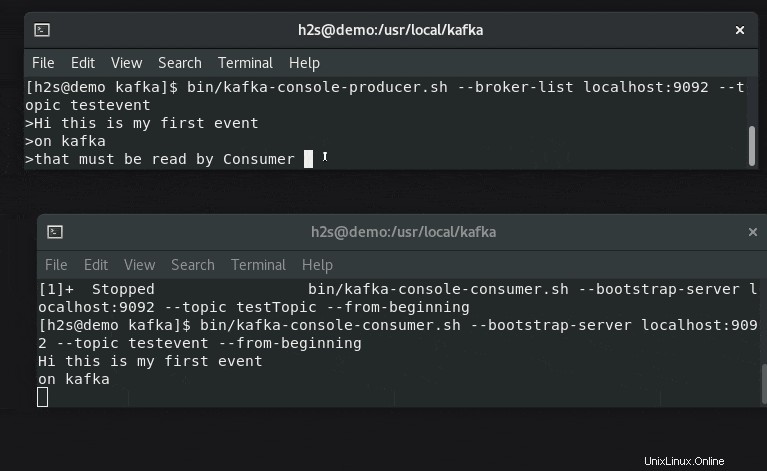
7. Écrivez un événement à l'aide de Kafka Producer et lisez-le avec le consommateur
Kafka propose deux API :Producteur et Consommateur , pour les deux, il propose un client en ligne de commande. Le producteur est responsable de la création des événements et le consommateur les utilise pour afficher ou lire les données générées par le producteur.
Ouvrez deux onglets ou sessions de terminal pour comprendre la configuration du générateur d'événements et du lecteur en temps réel.
#Sur un premier terminal :
Pour tester, créons des événements à l'aide du script Producer :
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testevent
Tapez du texte que vous souhaitez diffuser et afficher côté consommateur.
#Sur l'autre terminal
Courez, la commande ci-dessous avec le nom du sujet pour vérifier les messages ou les données d'événement générées en temps réel :
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testevent --from-beginning