La création de tracés statistiques en Python peut être pénible, surtout si vous les générez manuellement. Mais avec l'aide de la bibliothèque de visualisation de données Seaborn Python, vous pouvez simplifier votre travail et créer de beaux tracés rapidement et avec moins de lignes de code.
Avec Seaborn, créer de superbes tracés statistiques pour vos données est un jeu d'enfant. Ce guide vous montrera comment utiliser cette puissante bibliothèque à travers des exemples concrets.
Prérequis
Ce tutoriel sera une démonstration pratique. Si vous souhaitez suivre, assurez-vous d'avoir les éléments suivants :
- Un ordinateur Windows ou Linux sur lequel Python et Anaconda sont installés. Ce tutoriel utilisera Anaconda 2021.11 avec Python 3.9 sur un PC Windows 10.
Qu'est-ce que la bibliothèque Seaborn Python ?
La bibliothèque Seaborn Python est une bibliothèque de visualisation de données Python basée sur la bibliothèque Matplotlib. Seaborn offre un riche ensemble d'outils de haut niveau pour créer des graphiques et des tracés statistiques. La capacité de Seaborn à s'intégrer aux objets Pandas Dataframe vous permet de visualiser rapidement les données.
Un DataFrame représente des données tabulaires, comme ce que vous trouveriez dans un tableau, une feuille de calcul ou un fichier CSV de valeurs séparées par des virgules.
Seaborn fonctionne avec Pandas DataFrames et convertit les données sous le capot en code que Matplotlib peut comprendre.
Bien qu'il existe de nombreux tracés de haute qualité disponibles, vous découvrirez dans ce didacticiel les trois familles de tracés Seaborn intégrées les plus courantes pour vous aider à démarrer.
- Tracés relationnels.
- Tracés de distribution.
- Tracés catégoriels.
Seaborn comprend beaucoup plus d'intrigues, et ce didacticiel ne peut pas tout couvrir. La documentation de l'API Seaborn et le didacticiel sont d'excellents points de départ pour découvrir tous les différents types de tracés Seaborn.
Configuration d'un nouvel environnement JupyterLab et Seaborn Python
Avant de commencer votre voyage Seaborn, vous devez d'abord configurer un environnement Jupyter Lab. De plus, par souci de cohérence avec les exemples, vous travaillerez sur un ensemble de données spécifique avec ce didacticiel.
JupyterLab est une application Web qui vous permet de combiner du code, du texte enrichi, des tracés et d'autres médias dans un seul document. Vous pouvez également partager des blocs-notes en ligne avec d'autres personnes ou les utiliser comme documents exécutables.
Pour commencer à configurer votre environnement, procédez comme suit.
1. Ouvrez Anaconda Navigato r sur votre ordinateur.
un. Sur un ordinateur Windows :Cliquez sur Démarrer —> Anaconda3 —> Navigateur Anaconda .
b. Sur un ordinateur Linux :Exécutez le anaconda-navigator commande sur le terminal.
2. Sur le navigateur Anaconda, recherchez le JupyterLab l'application et cliquez sur Lancer . Cela ouvrira une instance de JupyterLab dans un navigateur Web.

3. Après avoir lancé JypyterLab, ouvrez la barre latérale du navigateur de fichiers et créez un nouveau dossier appelé ATA_Seaborn sous votre profil ou votre répertoire personnel. Ce nouveau dossier sera votre répertoire de projet.
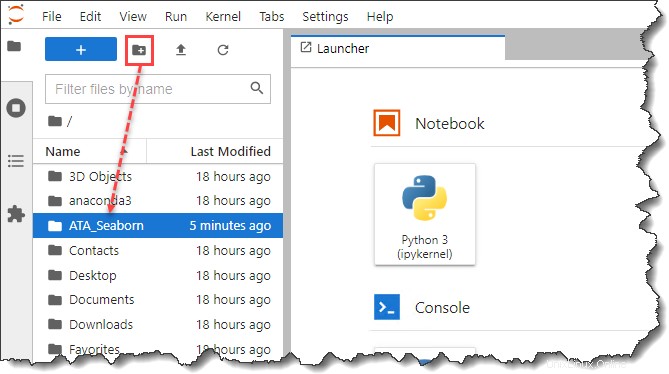
4. Ensuite, ouvrez un nouvel onglet de navigateur et téléchargez le Pokemon base de données. Assurez-vous de sauvegarder le ata_pokemon.csv dans le répertoire du projet que vous avez créé, qui, dans cet exemple, est ATA_Seaborn .
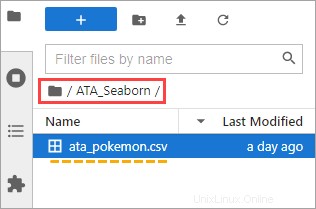
5. De retour sur JupyterLab, double-cliquez sur ATA_Seaborn dossier. Vous devriez maintenant voir le ata_pokemon.csv sous ce dossier.
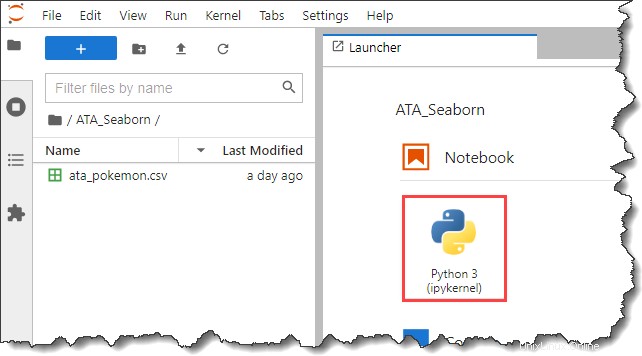
6. Maintenant, cliquez sur Python 3 bouton sous le Carnet de notes section sur le Lanceur onglet pour créer un nouveau bloc-notes.
7. Maintenant, cliquez sur le nouveau bloc-notes Untitled.ipynb et appuyez sur F2 pour renommer le fichier. Changez le nom du fichier en ata_pokemon.ipynb .

8. Ensuite, ajoutez un titre à votre bloc-notes. Cette étape est facultative mais recommandée pour rendre votre projet plus identifiable.
Dans la barre d'outils de vos blocs-notes, cliquez sur le menu déroulant qui indique Code et cliquez sur Marquer.
9. Entrez le texte "# Pokemon Data Visualization" dans la cellule Markdown et appuyez sur les touches Maj + Entrée.
La sélection du type de cellule passe automatiquement à Code, et le carnet aura le titre Pokemon Data Visualization au sommet.
10. Enfin, enregistrez votre travail en appuyant sur les touches Ctrl + S.
Assurez-vous de sauvegarder fréquemment votre travail. Vous devez enregistrer votre travail souvent pour éviter de perdre quoi que ce soit en cas de problème avec la connexion Internet. Chaque fois que vous apportez une modification, appuyez sur
CTRL+Spour enregistrer votre progression. Vous pouvez également cliquer sur le bouton Enregistrer dans la barre d'outils.
Importer les bibliothèques Pandas et Seaborn Python
Le code Python commence généralement par importer les bibliothèques nécessaires. Et dans ce projet, vous travaillerez avec les bibliothèques Pandas et Seaborn Python.
Pour importer Pandas et Seaborn, copiez le code ci-dessous et collez-le dans la cellule de commande de votre ordinateur portable.
N'oubliez pas ceci :pour exécuter le code ou les commandes dans la cellule de commande, appuyez sur les touches Maj + Entrée.
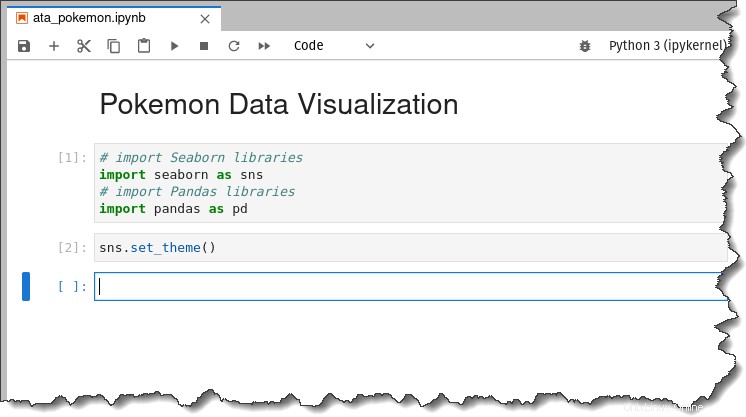
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdEnsuite, exécutez la commande ci-dessous pour appliquer l'esthétique du thème par défaut de Seaborn aux tracés que vous allez générer.
sns.set_theme()
Seaborn propose cinq thèmes intégrés. Ils sont darkgrid (par défaut), whitegrid , dark , white , et ticks .
Importer l'exemple de jeu de données
Maintenant que vous avez configuré votre environnement JupyterLab, importons les données de l'ensemble de données dans votre environnement Jupyter.
1. Exécutez le pd.read_csv() commande dans la cellule pour importer les données. Le nom de fichier du jeu de données doit être entre parenthèses pour indiquer le fichier à importer entre guillemets.
La commande ci-dessous importera le ata_pokemon.csv et stocker le jeu de données dans le pokemon variable.
pokemon = pd.read_csv("ata_pokemon.csv")
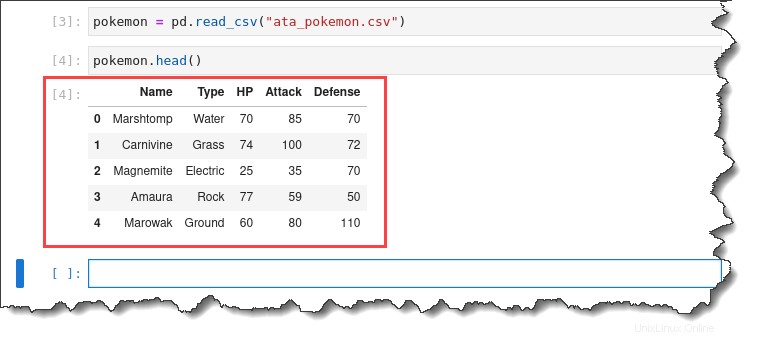
2. Exécutez le pokemon.head() commande pour prévisualiser les cinq premières lignes du jeu de données importé.
pokemon.head()Vous obtiendrez la sortie suivante.
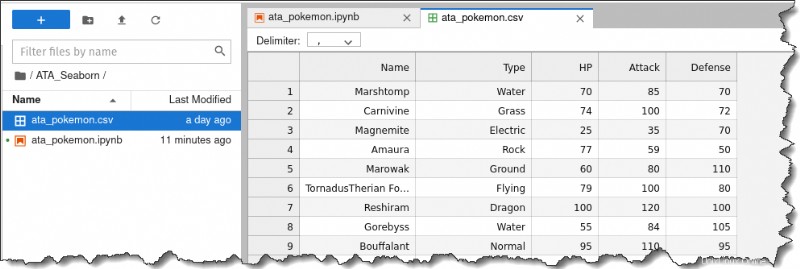
3. Double-cliquez sur ata_pokemon.csv fichier sur la gauche pour inspecter chaque ligne individuelle. Vous obtiendrez la sortie suivante.
Comme vous pouvez le voir, cet ensemble de données est assez pratique à utiliser car il répertorie chaque observation par ligne et toutes les informations numériques se trouvent dans des colonnes séparées.
Maintenant, posons quelques questions sur l'ensemble de données pour faciliter l'analyse.
- Quelle est la relation entre Attaque et HP ?
- Quelle est la distribution d'Attack ?
- Quelle est la relation entre l'attaque et le type ?
- Quelle est la répartition de l'attaque pour chaque type ?
- Quelle est l'attaque moyenne ou moyenne pour chaque type ?
- Et quel est le nombre de Pokémon pour chaque Type ?
Notez que bon nombre de ces questions se concentrent sur les relations entre les données numériques et catégorielles. Les données catégorielles signifient des données non numériques, qui, dans cet exemple d'ensemble de données, sont le type de Pokémon.
Contrairement à Matplotlib, qui est optimisé pour créer des tracés avec des données strictement numériques, vous pouvez utiliser Seaborn pour analyser des données contenant à la fois des données catégorielles et numériques.
Création de diagrammes de relations
Vous avez donc importé un jeu de données. Et après? Vous allez maintenant utiliser vos données importées et générer des tracés statistiques à partir de celles-ci. Commençons par créer un tracé relationnel ou relationnel pour découvrir la relation entre HP et Attaquer données.
Le traçage des relations est pratique pour identifier les relations possibles entre les variables de votre ensemble de données. Seaborn dispose de deux diagrammes pour tracer les relations :les diagrammes de dispersion et les diagrammes linéaires.
Tracé de lignes
La création d'un tracé linéaire nécessite que vous appeliez le Seaborn Python lineplot() fonction. Cette fonction prend trois paramètres — data= , x=' , et y=' ‘.
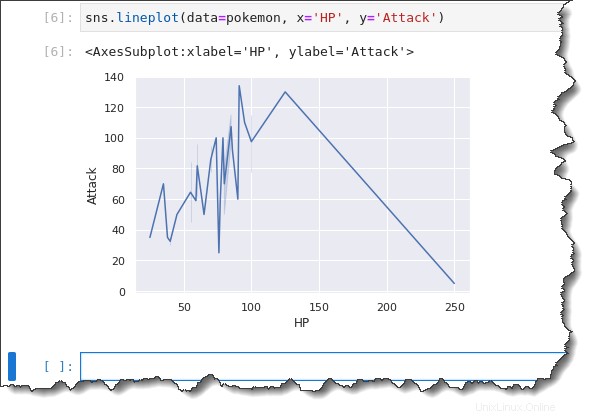
Copiez la commande ci-dessous et exécutez-la dans votre cellule de commande Jupyter. Cette commande utilise le pokemon objet comme source de données que vous avez précédemment importée, le HP les données de la colonne pour l'axe des abscisses et le Attack données pour l'axe des ordonnées.
sns.lineplot(data=pokemon, x='HP', y='Attack')Comme vous pouvez le voir ci-dessous, le tracé linéaire ne fait pas un excellent travail pour vous montrer les informations que vous pouvez analyser rapidement. Un tracé linéaire est plus efficace pour afficher un axe X qui suit une variable continue telle que le temps.
Dans cet exemple, vous tracez une variable discrète HP. Donc, ce qui se passe, c'est que le tracé linéaire va partout. Et il est plus difficile de déduire une tendance.
Nuage de points
Une partie de l'analyse exploratoire des données consiste à essayer différentes choses pour voir ce qui fonctionne bien. Et ce faisant, vous apprendrez que certains tracés peuvent vous fournir de meilleures informations que d'autres.
Qu'est-ce qui fait un meilleur diagramme de relation que les diagrammes linéaires, alors ? — Nuages de points.
Pour créer un nuage de points, vous appelez la fonction nuage de points, sns.scatterplot , et transmettez trois paramètres : data=pokemon , x=HP , et y=Attack .
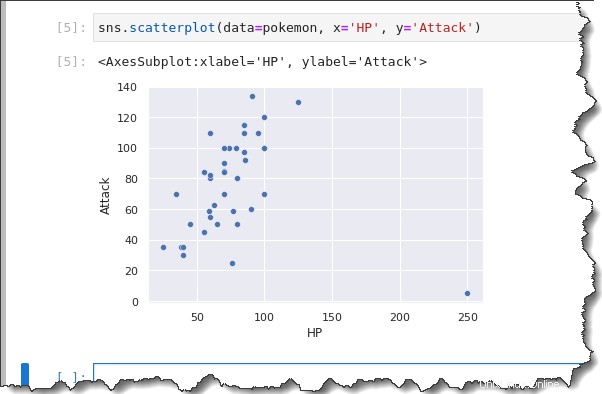
Exécutez la commande suivante pour créer un nuage de points pour l'ensemble de données pokemon.
sns.scatterplot(data=pokemon, x='HP', y='Attack')Comme vous pouvez le voir sur le résultat ci-dessous, le nuage de points vous montre qu'il peut y avoir une corrélation positive générale entre HP (axe x) et Attaque (axe y), avec une valeur aberrante.
Généralement, à mesure que HP augmente, l'attaque augmente également. Les Pokémon avec des points de vie plus importants ont tendance à être plus forts.
Nuage de points avec légendes
Alors que le nuage de points présentait déjà une visualisation des données plus sensible, vous pouvez encore améliorer le graphique en décomposant la distribution des types avec une légende.
Exécutez le sns.scatterplot() fonctionner à nouveau dans l'exemple suivant. Mais cette fois, ajoutez le hue='Type' mot-clé, qui créera une légende montrant les différents types de Pokémon. De retour sur l'onglet de votre bloc-notes Jupyter, exécutez la commande ci-dessous.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Remarquez sur le résultat ci-dessous, le nuage de points a maintenant des couleurs différentes. L'analyse des aspects catégoriels de vos données est désormais bien meilleure grâce aux distinctions visuelles fournies par la légende.
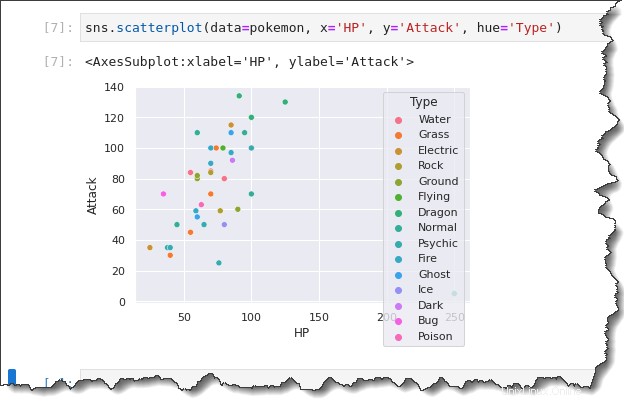
Ce qui est encore mieux, c'est que vous pouvez encore décomposer l'intrigue en utilisant le sns.relplot() fonction avec le col=Type et col_wrap arguments de mot-clé.
Exécutez la commande ci-dessous dans Jupyter pour créer une intrigue pour chaque type de Pokémon dans un format de grilles multi-intrigues.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)En regardant le résultat ci-dessous, vous pouvez en déduire que HP et Attack sont généralement corrélés positivement. Les Pokémon avec plus de HP ont tendance à être plus forts.
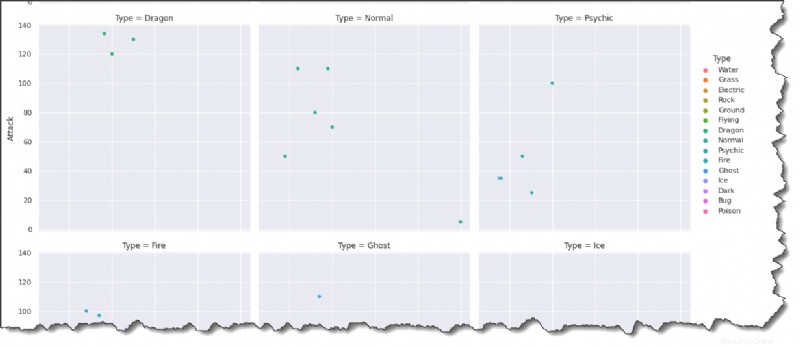
Seriez-vous d'accord pour dire que l'ajout de couleurs et de légendes rend le traçage plus intéressant ?
Création de tracés de distribution
Dans la section précédente, vous avez créé un nuage de points. Cette fois, utilisons un diagramme de distribution pour obtenir des informations sur la distribution de l'attaque et des PV pour chaque type de Pokémon.
Tracé d'histogramme
Vous pouvez utiliser l'histogramme pour visualiser la distribution d'une variable. Dans votre exemple de jeu de données, la variable est l'attaque du Pokémon.
Pour créer un tracé d'histogramme, exécutez le sns.histplot() fonction ci-dessous. Cette fonction prend deux paramètres :data=pokemon et x='Attack' . Copiez la commande ci-dessous et exécutez-la dans Jupyter.
sns.histplot(data=pokemon, x='Attack')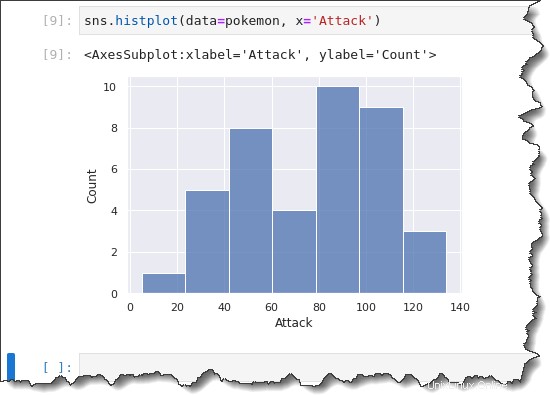
Lors de la création d'un histogramme, Seaborn sélectionne automatiquement une taille de bac optimale pour vous. Vous souhaiterez peut-être modifier la taille de la classe pour observer la distribution des données dans des regroupements de formes différentes.
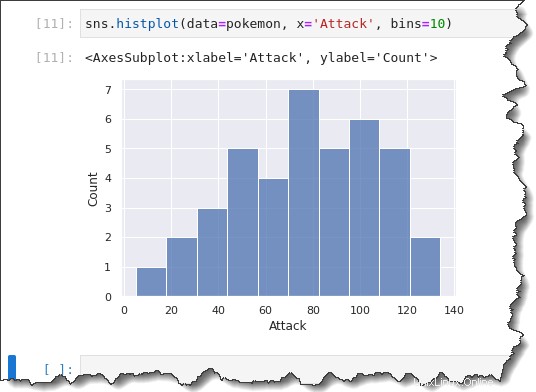
Pour spécifier une taille de bac fixe ou personnalisée, ajoutez le bins=x argument de la commande où x est la taille du bac personnalisé. Exécutez la commande ci-dessous pour créer un histogramme avec une taille de bac de 10.
sns.histplot(data=pokemon, x='Attack', bins=10)Dans l'histogramme précédent que vous avez généré, l'attaque Pokemon semble avoir une distribution bimodale (deux grosses bosses.)
Mais lorsque vous regardez la taille de votre bac de 10, les regroupements sont décomposés de manière plus segmentée. Vous pouvez voir qu'il y a plus d'une distribution unimodale, avec un biais vers la droite.
Tracé de l'estimation de la densité de noyau (KDE)
Une autre façon de visualiser la distribution consiste à tracer l'estimation de la densité du noyau. KDE est essentiellement comme un histogramme mais avec des courbes au lieu de colonnes.
L'avantage d'utiliser un graphique KDE est que vous pouvez faire des inférences plus rapides sur la façon dont les données sont distribuées en raison de la courbe de probabilité, montrant des caractéristiques telles que la tendance centrale, la modalité et l'asymétrie.
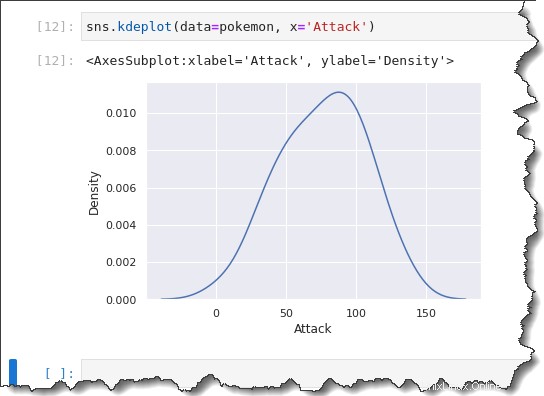
Pour créer un tracé KDE, appelez le sns.kdeplot() fonction et passer dans le même data=pokemon , x='Attack' comme arguments. Exécutez le code ci-dessous dans Jupyter pour voir le tracé de KDE en action.
sns.kdeplot(data=pokemon, x='Attack')Comme vous pouvez le voir ci-dessous, le tracé de KDE est similaire à l'histogramme avec une taille de bac de 10.
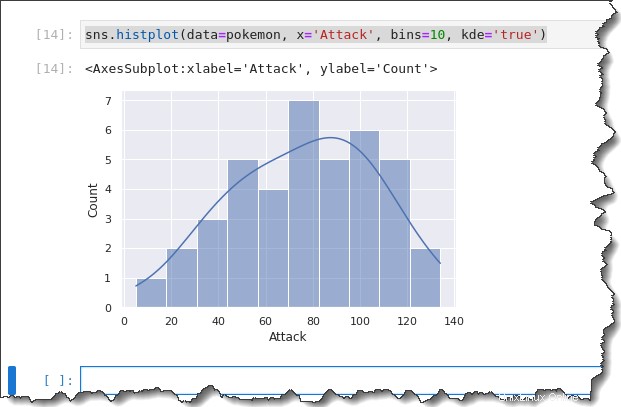
Puisque l'histogramme et KDE sont similaires, pourquoi ne pas les utiliser ensemble ? Seaborn vous permet de superposer le KDE sur un histogramme en ajoutant le mot-clé kde='true' argument de la commande précédente, comme vous pouvez le voir ci-dessous.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Vous obtiendrez la sortie suivante. Selon l'histogramme ci-dessous, la plupart des Pokémon ont un point d'attaque réparti entre 50 et 120. N'est-ce pas une bonne répartition !
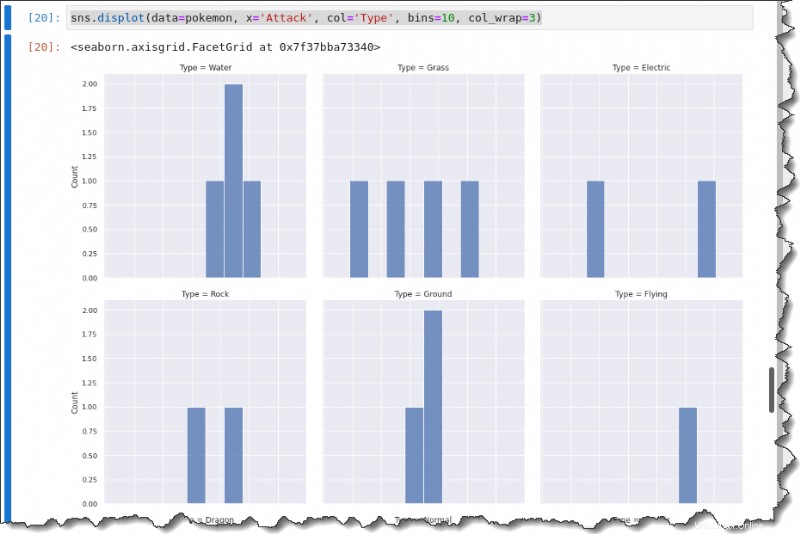
Pour décomposer chaque distribution d'attaque par type, appelez le displot() fonction avec le col mot-clé ci-dessous pour créer un graphique multi-grille montrant chaque type.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Vous obtiendrez la sortie suivante.
Génération de tracés catégoriels
Faire des histogrammes séparés en fonction de la catégorie de type est agréable. Mais les histogrammes peuvent ne pas vous donner une image claire. Utilisons donc certains des tracés catégoriques de Seaborn pour vous aider à approfondir l'analyse des données d'attaques en fonction des types de Pokémon.
Tracé en bandes
Dans les nuages de points et les histogrammes précédents, vous avez essayé de visualiser les données d'Attaque selon une variable catégorielle (Type ). Cette fois, vous allez créer un strip plot, une série de nuages de points regroupés par catégorie.
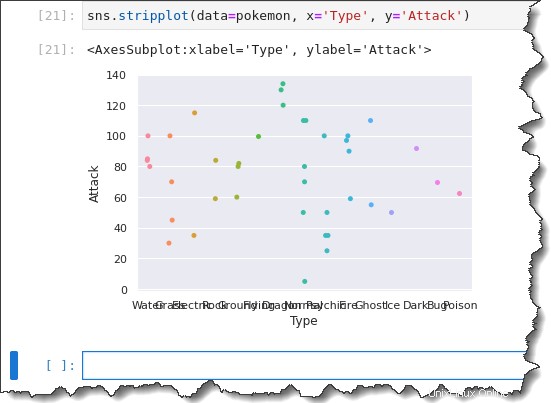
Pour créer votre tracé de bande catégoriel, appelez le sns.stripplot() fonction et passez trois arguments :data=pokemon , x='Type' , et y='Attack' . Exécutez le code ci-dessous dans Jupyter pour générer le tracé de bande catégorique.
sns.stripplot(data=pokemon, x='Type', y='Attack')Vous avez maintenant un diagramme en bande avec toutes les observations regroupées par Type. Mais remarquez comment les étiquettes de l'axe des x sont toutes collées ensemble ? Pas très utile, n'est-ce pas ?
Pour corriger les libellés de l'axe X, vous devrez utiliser une autre fonction appelée catplot(). .
Sur votre cellule de commande de bloc-notes Jupyter, exécutez le sns.catplot() fonction et passer cinq argumentskind='strip' , data=pokemon , x='Type' , y='Attack' , etaspect=2 , comme indiqué ci-dessous.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Cette fois, le pot résultant affiche les étiquettes de l'axe des x en pleine largeur, ce qui rend votre analyse plus pratique.
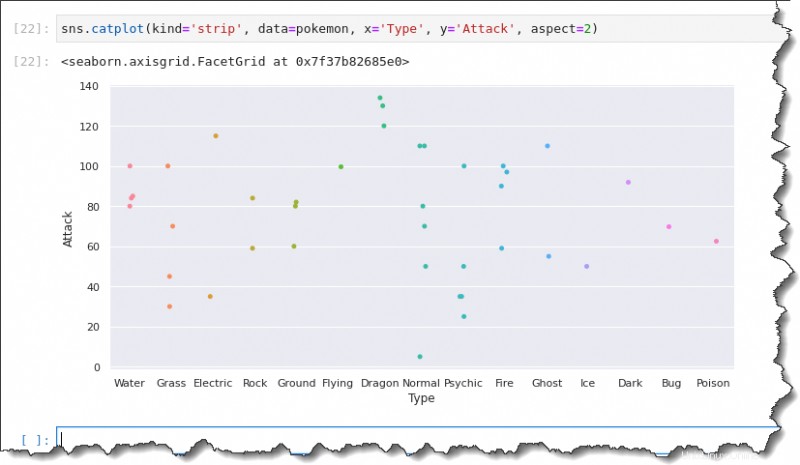
Tracé en boîte
Le catplot() La fonction a une autre sous-famille de graphiques qui vous aidera à visualiser la distribution des données avec une variable catégorielle. L'un d'eux est la boîte à moustaches.
Pour créer une boîte à moustaches, exécutez le sns.catplot() fonction avec les arguments suivants :data=pokemon , kind='box' , x='Type' , y='Attack' , et aspect=2 .
Le aspect L'argument contrôle l'espacement entre les étiquettes de l'axe des x. Une valeur plus élevée signifie un écart plus large.
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Cette sortie vous donne un résumé de la répartition des données. Utilisation du catplot() fonction, vous pouvez obtenir une répartition des données pour chaque type de Pokémon sur une parcelle.
Notez que les marqueurs de diamant noir représentent des valeurs aberrantes. Au lieu d'une boîte à moustaches, une ligne au milieu signifie qu'il n'y a qu'une seule observation pour ce type de Pokémon.
Vous disposez d'un résumé à cinq chiffres pour chacun de ces tracés en boîte et à moustaches. La ligne au milieu de la case représente la valeur médiane ou leur tendance centrale des points d'attaque.
Vous avez également les premier et troisième quartiles et les moustaches, représentant les valeurs maximales et minimales.
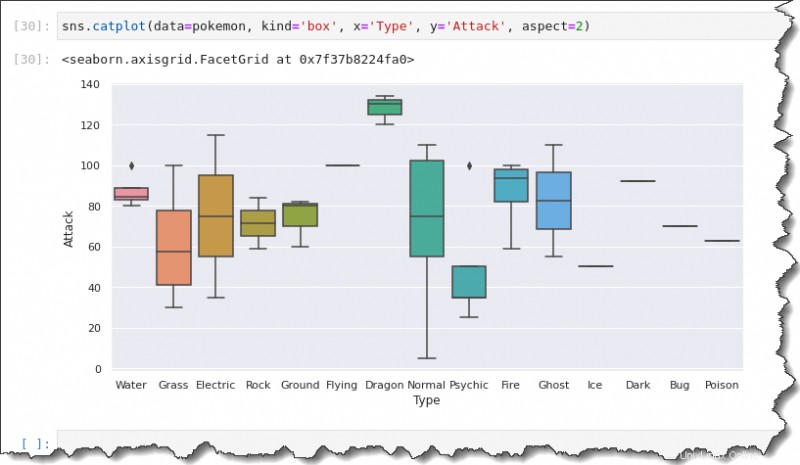
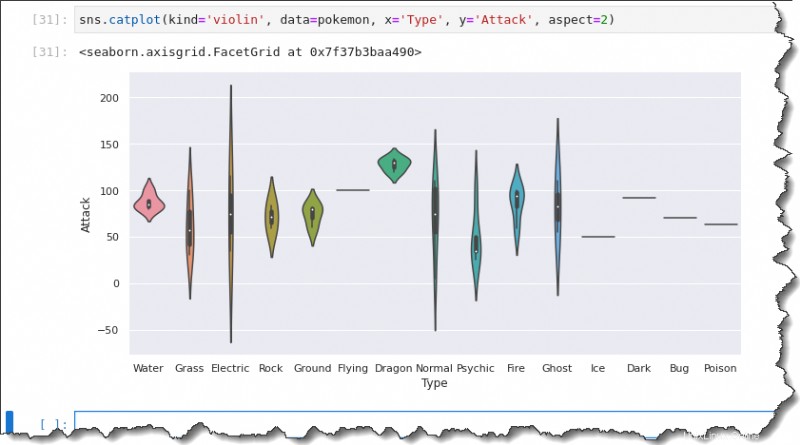
Tracé de violon
Une autre façon de visualiser la distribution consiste à utiliser le tracé de violon. L'intrigue de violon est comme une boîte à moustaches et un mélange KDE. Les diagrammes en violon sont analogues aux diagrammes en boîte.
Pour créer un tracé de violon, remplacez le kind valeur à violin , tandis que le reste est le même que lorsque vous avez exécuté la commande de tracé de boîte. Exécutez le code ci-dessous pour créer un tracé de violon.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)Par conséquent, vous pouvez voir que le tracé du violon inclut la médiane, le premier et le troisième quartiles. Le graphique en violon fournit un résumé similaire de la propagation des données à la boîte à moustaches.
Revenons à la question :Quelle est la répartition des attaques pour chaque type de Pokémon ?
La boîte à moustaches montre que le minimum de points d'attaque se situe entre 0 et 10, tandis que le maximum va jusqu'à 110.
Les points d'attaque médians pour les Pokémon de type normal semblent être d'environ 75. Les premier et troisième quartiles semblent être d'environ 55 et 105.
Traçage des barres
Le diagramme à barres fait partie de la famille d'estimations catégorielles de Seaborn qui affiche les valeurs moyennes ou moyennes de chaque catégorie de données.
Pour créer un graphique à barres, exécutez le sns.catplot() fonction dans Jupyter et spécifiez six arguments :kind='bar' , data=pokemon , x='Type' , y='Attack' , et aspect=2 , comme indiqué ci-dessous.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Les lignes noires sur chaque barre sont des barres d'erreur représentant l'incertitude, comme des valeurs aberrantes dans les observations. Comme vous pouvez le voir ci-dessous, les valeurs moyennes sont :
- Environ 90 pour les Pokémon de type Eau.
- Environ 60 pour l'herbe .
- Électrique est approximativement à 75.
- Rock peut-être 70.
- Le sol dans les 75.
- Et ainsi de suite.
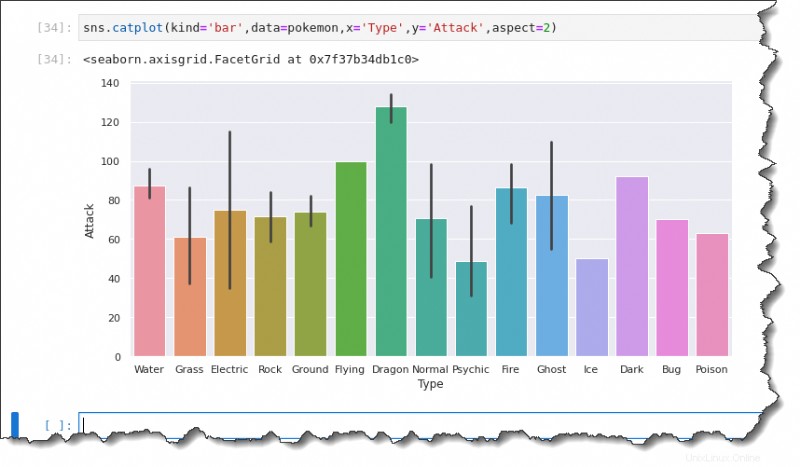
Compter le traçage
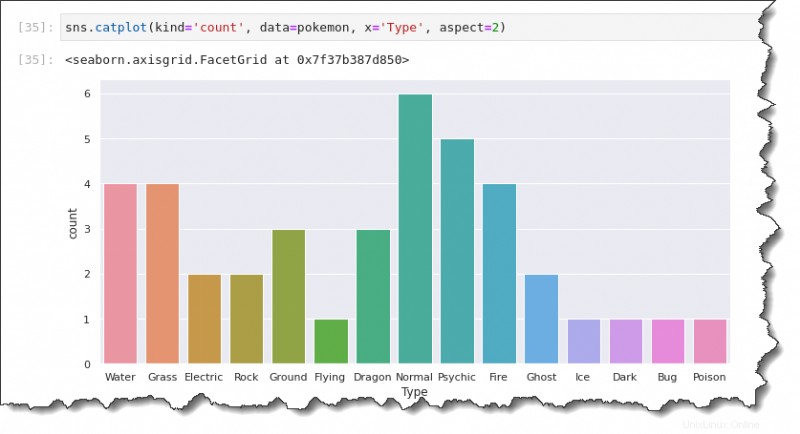
Et si vous voulez tracer le nombre de Pokémon au lieu des données moyennes/moyennes ? Le tracé de comptage vous permettra de le faire avec la bibliothèque Seaborn Python.
Pour générer un comptage, remplacez le kind valeur avec count , comme indiqué dans le code ci-dessous. Contrairement au diagramme à barres, le diagramme de nombre n'a besoin que d'un axe de données. Selon l'orientation du tracé que vous souhaitez créer, spécifiez uniquement l'axe des x ou l'axe des y.
La commande ci-dessous crée le tracé de comptage montrant la variable de type sur l'axe des x.
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Vous aurez un tracé de comptage qui ressemble à celui ci-dessous. Comme vous pouvez le constater, les types de Pokémon les plus courants sont :
- Normale (6).
- Psychique (5).
- Eau (4).
- Herbe (4).
- Et ainsi de suite.
Conclusion
Dans ce didacticiel, vous avez appris à créer des tracés statistiques par programmation avec la bibliothèque Seaborn Python. Selon vous, quelle méthode de traçage sera la plus appropriée pour votre ensemble de données ?
Maintenant que vous avez travaillé sur des exemples et pratiqué la création de parcelles avec Seaborn, pourquoi ne pas commencer à travailler sur de nouvelles parcelles par vous-même. Peut-être pouvez-vous commencer avec l'ensemble de données Iris ou rassembler vos exemples de données ?
Et pendant que vous y êtes, essayez également certains des autres modèles et palettes de couleurs intégrés de Seaborn ! Merci d'avoir lu et amusez-vous !