Scrapy est un framework open source développé en Python qui vous permet de créer des araignées Web ou des robots d'exploration pour extraire rapidement et facilement des informations à partir de sites Web.
Ce guide montre comment créer et exécuter une araignée Web avec Scrapy sur votre serveur pour extraire des informations de pages Web grâce à l'utilisation de différentes techniques.
Tout d'abord, connectez-vous à votre serveur via une connexion SSH. Si vous ne l'avez pas encore fait, il est recommandé de suivre notre guide pour vous connecter en toute sécurité avec SSH. Dans le cas d'un serveur local, passez à l'étape suivante et ouvrez le terminal de votre serveur.
Création de l'environnement virtuel
Avant de lancer l'installation proprement dite, procédez à la mise à jour des packages système :
$ sudo apt-get updateContinuez en installant quelques dépendances nécessaires au fonctionnement :
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devUne fois l'installation terminée, vous pouvez commencer à configurer virtualenv, un package Python qui vous permet d'installer des packages Python de manière isolée, sans compromettre les autres logiciels. Bien qu'étant facultative, cette étape est fortement recommandée par les développeurs de Scrapy :
$ sudo pip install virtualenvEnsuite, préparez un répertoire pour installer l'environnement Scrapy :
$ sudo mkdir /var/scrapy
$ cd /var/scrapyEt initialiser un environnement virtuel :
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.Pour activer l'environnement virtuel, exécutez simplement la commande suivante :
$ sudo source /var/scrapy/bin/activateVous pouvez quitter à tout moment via la commande "désactiver".
Installation de Scrapy
Maintenant, installez Scrapy et créez un nouveau projet :
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd exampleDans le répertoire du projet nouvellement créé, le fichier aura la structure suivante :
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyUtiliser le shell à des fins de test
Scrapy vous permet de télécharger le contenu HTML des pages Web et d'en extrapoler les informations grâce à l'utilisation de différentes techniques, telles que les sélecteurs css. Pour faciliter ce processus, Scrapy fournit un "shell" afin de tester l'extraction d'informations en temps réel.
Dans ce tutoriel, vous allez voir comment capturer le premier post sur la page principale du célèbre Reddit social :
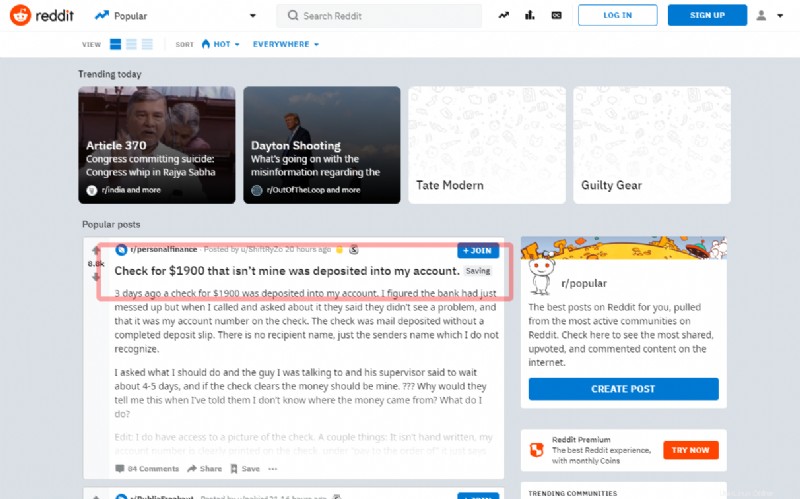
Avant de passer à l'écriture du source, essayez d'extraire le titre à travers le shell :
$ sudo scrapy shell "reddit.com"En quelques secondes, Scrapy aura téléchargé la page principale. Alors, entrez les commandes en utilisant l'objet 'response'. Comme dans l'exemple suivant, utilisez le sélecteur "article h3 ::text":, pour obtenir le titre du premier article
>>> response.css('article h3::text')[0].get()Si le sélecteur fonctionne correctement, le titre sera affiché. Ensuite, quittez le shell :
>>> exit()Pour créer une nouvelle araignée, créez un nouveau fichier Python dans le répertoire du projet exemple /araignées/reddit.py :
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )Tous les spiders héritent de la classe Spider du module Scrapy et lancent les requêtes en utilisant la méthode start_requests :
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Lorsque Scrapy a terminé de charger la page, il appellera la fonction de rappel (self.parseHome).
Ayant l'objet de réponse, le contenu qui vous intéresse peut être pris :
headline = response.css('article h3::text')[0].get()Et, à des fins de démonstration, enregistrez-le dans un fichier "popular.list".
Démarrez le spider nouvellement créé à l'aide de la commande :
$ sudo scrapy crawl redditUne fois terminé, le dernier titre extrait se retrouvera dans le fichier popular.list :
$ cat popular.listPlanifier Scrapyd
Pour programmer l'exécution de vos spiders, utilisez le service proposé par Scrapy "Scrapy Cloud" (voir https://scrapinghub.com/scrapy-cloud) ou installez le démon open source directement sur votre serveur .
Assurez-vous que vous êtes dans l'environnement virtuel créé précédemment et installez le package scrapyd via pip :
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydUne fois l'installation terminée, préparez un service en créant le fichier /etc/systemd/system/scrapyd.service avec le contenu suivant :
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapydEnregistrer le fichier nouvellement créé et démarrer le service via :
$ sudo systemctl start scrapydMaintenant, le démon est configuré et prêt à accepter de nouveaux spiders.
Pour déployer votre exemple d'araignée, vous devez utiliser un outil, appelé "scrapyd-client", fourni par Scrapy. Procédez à son installation via pip :
$ sudo pip install scrapyd-clientContinuez en éditant le fichier scrapy.cfg et en définissant les données de déploiement :
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleDéployez maintenant en exécutant simplement la commande :
$ sudo scrapyd-deployPour programmer l'exécution de l'araignée, appelez simplement l'API scrapyd :
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit