Si vous avez lu mon premier article sur l'utilisation de Keepalived pour gérer le basculement simple dans les clusters, vous vous souviendrez que VRRP utilise le concept de priorité pour déterminer quel serveur sera le maître actif. Le serveur avec la priorité la plus élevée "gagne" et agira en tant que maître, conservant le VIP et traitant les demandes. Keepalived fournit plusieurs méthodes utiles pour ajuster la priorité en fonction de l'état de votre système. Dans cet article, vous allez explorer plusieurs de ces mécanismes, ainsi que Keepalived la capacité d'exécuter des scripts lorsque l'état d'un serveur change.
Je ne montrerai que la configuration sur le serveur 1 pour ces exemples. À ce stade, vous êtes probablement à l'aise avec la configuration nécessaire sur le serveur 2 si vous avez lu toute la série. Si ce n'est pas le cas, prenez un moment pour revoir les premier et deuxième articles de cette série avant de continuer.
- Utilisation de Keepalived pour gérer le basculement simple dans les clusters
- Configuration d'un cluster Linux avec Keepalived :configuration de base
Symboles de réseau dans les diagrammes disponibles via VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived fait un excellent travail pour déclencher un basculement lorsque les publicités ne sont pas reçues, par exemple lorsque le maître actif meurt complètement ou est inaccessible pour une autre raison. Cependant, vous constaterez souvent que des mécanismes de déclenchement plus fins sont nécessaires. Par exemple, votre application peut exécuter ses propres vérifications de l'état pour déterminer la capacité de l'application à répondre aux demandes des clients. Vous ne voudriez pas qu'un serveur d'applications défectueux reste le maître actif simplement parce qu'il était actif et envoyait VRRP publicités.
Remarque :J'ai constaté que la version de Keepalived disponibles via les référentiels de packages standard contenaient des bogues qui empêchaient certains des exemples ci-dessous de fonctionner correctement. Si vous rencontrez des problèmes, vous pouvez installer Keepalived depuis la source, comme décrit dans l'article précédent.
Suivi des processus
L'un des Keepalived les plus courants Les configurations impliquent le suivi d'un processus sur le serveur pour déterminer la santé de l'hôte. Par exemple, vous pouvez configurer une paire de serveurs Web hautement disponibles et déclencher un basculement si Apache cesse de s'exécuter sur l'un d'entre eux.
Keepalived rend cela facile grâce à son track_process consignes de configuration. Dans l'exemple ci-dessous, j'ai configuré Keepalived pour regarder le httpd traiter avec un poids de 10. Tant que httpd est en cours d'exécution, la priorité annoncée sera 254 (244 + 10 =254). Si httpd s'arrête, la priorité passe à 244 et déclenche un basculement (en supposant qu'une configuration similaire existe sur le serveur2).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} Avec cette configuration en place (et Apache installé et exécuté sur les deux serveurs), vous pouvez tester un scénario de basculement en arrêtant Apache et en observant le passage du VIP du serveur1 au serveur2 :
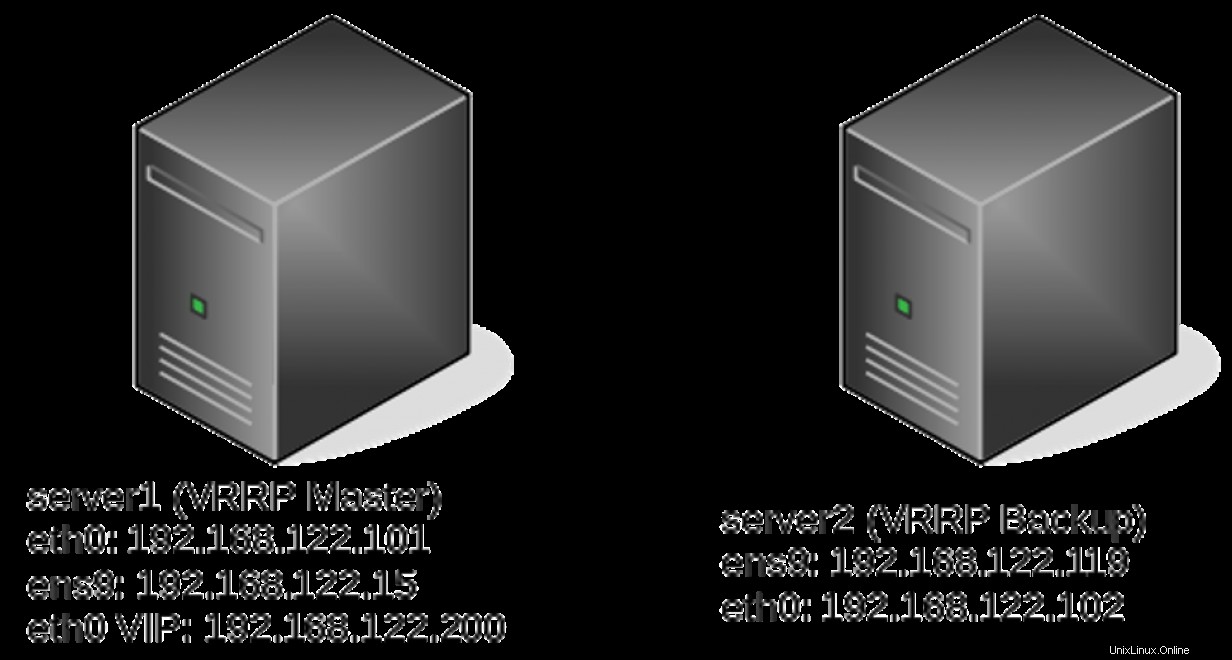
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Fichiers de suivi
Keepalived a également la capacité de prendre des décisions prioritaires en fonction du contenu d'un fichier, ce qui peut être utile si vous exécutez une application qui peut écrire des valeurs dans ce fichier. Par exemple, vous pouvez avoir un processus d'arrière-plan dans votre application qui effectue périodiquement une vérification de l'état et écrit une valeur dans un fichier en fonction de l'état général de l'application.
Le Keepalived La page de manuel explique que le suivi des fichiers est basé sur le poids configuré pour le fichier :
"la valeur sera lue comme un nombre dans le texte du fichier. Si le poids configuré pour le track_file est 0, une valeur différente de zéro dans le fichier sera traitée comme un état d'échec, et une valeur nulle sera traitée comme un état OK, sinon la valeur sera multipliée par le poids configuré dans le instruction track_file. Si le résultat est inférieur à -253, toute instance VRRP ou groupe de synchronisation surveillant le script passera à l'état d'erreur (le poids peut être de 254 pour permettre la lecture d'une valeur négative à partir du fichier)."
Je vais garder les choses simples et utiliser un poids de 1 pour le fichier de piste dans cet exemple. Cette configuration prendra la valeur numérique dans le fichier à /var/run/my_app/vrrp_track_file et multipliez-le par 1.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Vous pouvez maintenant créer le fichier avec une valeur de départ et redémarrer Keepalived . La priorité peut être vue dans tcpdump sortie, comme indiqué dans le deuxième article de cette série.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Vous pouvez voir que la priorité annoncée est 249, qui est la valeur dans le fichier (5) multipliée par le poids (1) et ajoutée à la priorité de base (244). De même, ajuster la priorité à 6 augmentera la priorité :
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Interface de suivi
Pour les serveurs avec plusieurs interfaces, il peut être utile d'ajuster la priorité du Keepalived instance en fonction de l'état d'une interface. Par exemple, un équilibreur de charge avec un VIP frontal et une connexion dorsale à un réseau interne peut vouloir déclencher un Keepalived basculement si la connexion au réseau principal tombe en panne. Cela peut être accompli avec la configuration track_interface :
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} La configuration ci-dessus affecte un poids de 5 au statut de l'interface ens9. Cela amènera server1 à assumer une priorité de 249 (244 + 5 =249) tant que ens9 est activé. Si ens9 tombe en panne, la priorité tombera à 244 (et déclenchera un basculement, en supposant que le serveur2 est configuré de la même manière). Vous pouvez tester cela sur un serveur multi-interfaces en désactivant une interface et en regardant le VIP se déplacer entre les hôtes :
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Scénario de piste
Vous avez vu que Keepalived offre de nombreuses méthodes de vérification intégrées utiles pour déterminer la santé et le VRRP ultérieur priorité d'un hôte. Cependant, des environnements parfois plus complexes nécessitent l'utilisation d'outils personnalisés, tels que des scripts de vérification de l'état, pour répondre à leurs besoins. Heureusement, Keepalived a également la capacité d'exécuter un script arbitraire pour déterminer la santé d'un hôte. Vous pouvez ajuster le poids du script, mais je vais garder les choses simples pour cet exemple :un script qui renvoie 0 indiquera le succès, tandis qu'un script qui renvoie n'importe quoi d'autre indiquera que le Keepalived l'instance doit entrer dans l'état d'erreur.
Le script est un simple ping vers le 8.8.8.8 préféré de tout le monde Serveur DNS de Google, comme indiqué ci-dessous. Dans votre environnement, vous utiliserez probablement un script plus complexe pour effectuer les vérifications d'état dont vous avez besoin.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Vous remarquerez que j'ai utilisé un délai d'attente de 1 seconde pour ping (-W 1). Lors de l'écriture de Keepalived vérifier les scripts, c'est une bonne idée de les garder légers et rapides. Vous ne voulez pas qu'un serveur en panne reste le maître pendant longtemps parce que votre script est lent.
Le Keepalived la configuration d'un script de vérification est illustrée ci-dessous :
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Cela ressemble beaucoup à la configuration avec laquelle vous avez travaillé, mais le vrrp_script block a quelques directives uniques :
interval:fréquence d'exécution du script (1 seconde).timeout:Combien de temps attendre le retour du script (5 secondes).rise:combien de fois le script doit être renvoyé avec succès pour que l'hôte soit considéré comme "sain". Dans cet exemple, le script doit réussir 3 fois. Cela permet d'éviter une condition de "battement" où un seul échec (ou succès) provoque leKeepalivedétat pour basculer rapidement d'avant en arrière.fall:combien de fois le script doit échouer (ou expirer) pour que l'hôte soit considéré comme "malsain". Cela fonctionne comme l'inverse de la directive rise.
Vous pouvez tester cette configuration en forçant le script à échouer. Dans l'exemple ci-dessous, j'ai ajouté un iptables règle qui empêche la communication avec 8.8.8.8 . Cela a provoqué l'échec du bilan de santé et la disparition du VIP après quelques secondes. Je peux alors supprimer la règle et voir le VIP réapparaître.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Un conseil rapide sur les scripts dans Keepalived :Ils peuvent être exécutés en tant qu'utilisateur différent de root. Bien que je n'aie pas démontré cela dans ces exemples, jetez un œil à la page de manuel et assurez-vous que vous utilisez l'utilisateur le moins privilégié possible pour éviter toute implication négative sur la sécurité de votre script de vérification.
Notifier les scripts
J'ai discuté des moyens de déclencher Keepalived réponses basées sur des conditions externes. Cependant, vous souhaitez probablement également déclencher des actions lorsque Keepalived transitions d'un état à un autre. Par exemple, vous pouvez arrêter un service lorsque Keepalived entre dans l'état de sauvegarde, ou vous pouvez envoyer un e-mail à un administrateur. Keepalived vous permet de le faire avec des scripts de notification.
Keepalived fournit plusieurs directives de notification pour appeler uniquement des scripts sur des états particuliers (notify_master , notify_backup , etc.), mais je vais me concentrer sur le simple notify directive car c'est la plus souple. Lorsqu'un script dans la notify est appelée, elle reçoit quatre arguments supplémentaires (après tous les arguments passés au script lui-même).
Classés dans l'ordre, il s'agit de :
- Groupe ou instance :indique si la notification est déclenchée par un
VRRPgroupe (non abordé dans cette série) ou unVRRPparticulier exemple. - Nom du groupe ou de l'instance
- Indiquer que le groupe ou l'instance est en transition vers
- La priorité
Jeter un oeil à un exemple rend cela plus clair. Le script et Keepalived la configuration ressemble à ceci :
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
La configuration ci-dessus appellera le /usr/local/bin/keepalived_notify.sh script à chaque fois qu'un Keepalived transition d'état se produit. Puisque le même script de vérification est en place, vous pouvez facilement inspecter l'état initial puis déclencher une transition :
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Vous pouvez voir que les arguments de la ligne de commande correspondent à ceux que j'ai décrits au début de cette section. Évidemment, il s'agit d'un exemple simple, mais les scripts de notification peuvent effectuer de nombreuses actions complexes, telles que l'ajustement des règles de routage ou le déclenchement d'autres scripts. Ils constituent un moyen utile d'effectuer des actions externes basées sur Keepalived changements d'état.
Conclusion
Cet article a clôturé un Keepalived fondamental série avec quelques concepts avancés. Vous avez appris à déclencher Keepalived changements de priorité et d'état en fonction d'événements externes, tels que l'état du processus, les changements d'interface et même les résultats de scripts externes. Vous avez également appris à déclencher des scripts de notification en réponse à Keepalived changements d'état. Vous pouvez combiner deux ou plusieurs de ces approches pour créer une paire de serveurs Linux hautement disponibles qui répondent à plusieurs stimuli externes et garantissent que le trafic atteint toujours une adresse IP saine qui peut répondre aux demandes des clients.
[ Vous souhaitez en savoir plus sur l'administration système ? Suivez un cours en ligne gratuit :Présentation technique de Red Hat Enterprise Linux. ]