J'ai été intrigué par votre question et je me suis un peu laissé emporter. Cette solution générera un joli fichier PDF avec un index cliquable et un code surligné en couleur. Il trouvera tous les fichiers dans le répertoire et les sous-répertoires actuels et créera une section dans le fichier PDF pour chacun d'eux (voir les notes ci-dessous pour savoir comment rendre votre commande de recherche plus spécifique).
Il nécessite que vous ayez installé les éléments suivants (les instructions d'installation concernent les systèmes basés sur Debian, mais elles devraient être disponibles dans les dépôts de votre distribution) :
-
pdflatex,coloretlistingssudo apt-get install texlive-latex-extra latex-xcolor texlive-latex-recommendedCela devrait également installer un système LaTeX de base si vous n'en avez pas installé.
Une fois ceux-ci installés, utilisez ce script pour créer un document LaTeX avec votre code source. L'astuce consiste à utiliser le listings (partie de texlive-latex-recommended ) et color (installé par latex-xcolor ) Paquets LaTeX. Le \usepackage[..]{hyperref} est ce qui rend les listes de la table des matières des liens cliquables.
#!/usr/bin/env bash
tex_file=$(mktemp) ## Random temp file name
cat<<EOF >$tex_file ## Print the tex file header
\documentclass{article}
\usepackage{listings}
\usepackage[usenames,dvipsnames]{color} %% Allow color names
\lstdefinestyle{customasm}{
belowcaptionskip=1\baselineskip,
xleftmargin=\parindent,
language=C++, %% Change this to whatever you write in
breaklines=true, %% Wrap long lines
basicstyle=\footnotesize\ttfamily,
commentstyle=\itshape\color{Gray},
stringstyle=\color{Black},
keywordstyle=\bfseries\color{OliveGreen},
identifierstyle=\color{blue},
xleftmargin=-8em,
}
\usepackage[colorlinks=true,linkcolor=blue]{hyperref}
\begin{document}
\tableofcontents
EOF
find . -type f ! -regex ".*/\..*" ! -name ".*" ! -name "*~" ! -name 'src2pdf'|
sed 's/^\..//' | ## Change ./foo/bar.src to foo/bar.src
while read i; do ## Loop through each file
name=${i//_/\\_} ## escape underscores
echo "\newpage" >> $tex_file ## start each section on a new page
echo "\section{$i}" >> $tex_file ## Create a section for each filename
## This command will include the file in the PDF
echo "\lstinputlisting[style=customasm]{$i}" >>$tex_file
done &&
echo "\end{document}" >> $tex_file &&
pdflatex $tex_file -output-directory . &&
pdflatex $tex_file -output-directory . ## This needs to be run twice
## for the TOC to be generated
Exécutez le script dans le répertoire contenant les fichiers sources
bash src2pdf
Cela créera un fichier appelé all.pdf dans le répertoire courant. J'ai essayé cela avec quelques fichiers source aléatoires que j'ai trouvés sur mon système (en particulier, deux fichiers de la source de vlc-2.0.0 ) et voici une capture d'écran des deux premières pages du PDF résultant :
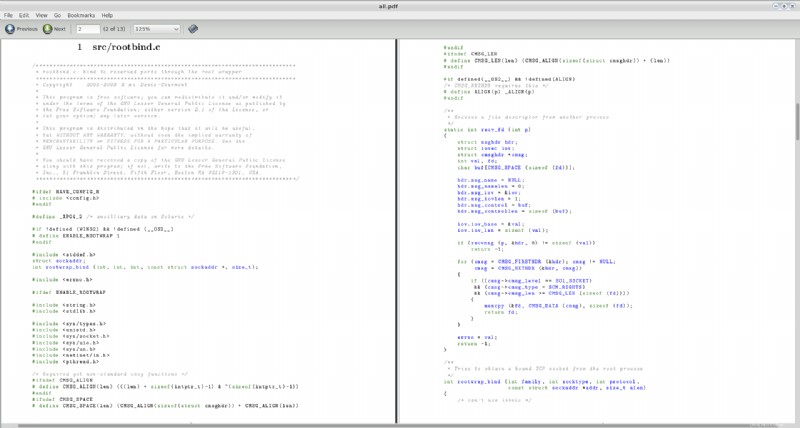
Quelques commentaires :
- Le script ne fonctionnera pas si les noms de fichiers de votre code source contiennent des espaces. Puisque nous parlons de code source, je suppose que ce n'est pas le cas.
- J'ai ajouté
! -name "*~"pour éviter les fichiers de sauvegarde. -
Je vous recommande d'utiliser un
findplus spécifique pour trouver vos fichiers, sinon tout fichier aléatoire sera inclus dans le PDF. Si vos fichiers ont tous des extensions spécifiques (.cet.hpar exemple), vous devez remplacer lefinddans le script avec quelque chose comme çafind . -name "*\.c" -o -name "\.h" | sed 's/^\..//' | - Jouez avec le
listingsoptions, vous pouvez modifier cela pour qu'il soit exactement comme vous le souhaitez.
(depuis StackOverflow)
for i in *.src; do echo "$i"; echo "---"; cat "$i"; echo ; done > result.txt
Il en résultera un result.txt contenant :
- Nom de fichier
- séparateur (---)
- Contenu du fichier .src
- Répétez à partir du haut jusqu'à ce que tous les fichiers *.src soient terminés
Si votre code source a une extension différente, modifiez-le simplement au besoin. Vous pouvez également modifier le bit d'écho pour ajouter les informations nécessaires (peut-être echo "filename $1" ou changer le séparateur, ou ajouter un séparateur de fin de fichier).
le lien a d'autres méthodes, alors utilisez la méthode que vous préférez. Je trouve que celui-ci est le plus flexible, bien qu'il s'accompagne d'une légère courbe d'apprentissage.
Le code fonctionnera parfaitement depuis un terminal bash (juste testé sur une VirtualBox Ubuntu)
Si vous ne vous souciez pas du nom de fichier et que vous vous souciez uniquement du contenu des fichiers fusionnés :
cat *.src > result.txt
fonctionnera parfaitement bien.
Une autre méthode suggérée était :
grep "" *.src > result.txt
Ce qui préfixera chaque ligne avec le nom de fichier, ce qui peut être bon pour certaines personnes, personnellement je trouve que c'est trop d'informations, c'est pourquoi ma première suggestion est la boucle for ci-dessus.
Merci aux membres du forum StackOverflow.
EDIT :Je viens de réaliser que vous recherchez spécifiquement HTML ou PDF comme résultat final. Certaines solutions que j'ai vues consistent à imprimer le fichier texte en PostScript, puis à convertir le postscript en PDF. Certains codes que j'ai vus :
groff -Tps result.txt > res.ps
alors
ps2pdf res.ps res.pdf
(Nécessite d'avoir ghostscript)
J'espère que cela vous aidera.
Je sais que j'arrive trop tard, mais quelqu'un à la recherche d'une solution pourrait trouver cela utile.
Sur la base de la réponse de @terdon, j'ai créé un script BASH qui fait le travail :https://github.com/eljuanchosf/source-code-to-pdf