Je me suis écrit un one-liner perl, qui fait exactement cela, et il imprime également le caractère original. (Il attend le fichier de STDIN)
perl -C7 -ne 'for(split(//)){print sprintf("U+%04X", ord)." ".$_."\n"}'
Cependant, il devrait y avoir un meilleur moyen que cela.
J'avais besoin du point de code pour certains smileys courants et j'ai trouvé ceci :
echo -n "" | # -n ignore trailing newline \
iconv -f utf8 -t utf32be | # UTF-32 big-endian happens to be the code point \
xxd -p | # -p just give me the plain hex \
sed -r 's/^0+/0x/' | # remove leading 0's, replace with 0x \
xargs printf 'U+%04X\n' # pretty print the code point
qui imprime
U+1F60A
qui est le point de code pour "VISAGE SOURIANT AVEC DES YEUX SOURIANTS".
Inspirée de la réponse de Neftas, voici une solution légèrement plus simple qui fonctionne avec des chaînes plutôt qu'un seul caractère :
iconv -f utf8 -t utf32le | hexdump -v -e '8/4 "0x%04x " "\n"' | sed -re"s/0x / /g"
# ^
# The number `8` above determines the number of columns in the output. Modify as needed.
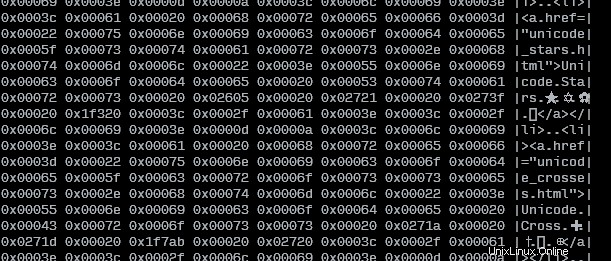
J'ai également créé un script Bash qui lit à partir de stdin ou d'un fichier et qui affiche le texte d'origine avec les valeurs unicode :
COLWIDTH=8
SHOWTEXT=true
tmpfile=$(mktemp)
cp "${1:-/dev/stdin}" "$tmpfile"
left=$(set -o pipefail; iconv -f utf8 -t utf32le "$tmpfile" | hexdump -v -e $COLWIDTH'/4 "0x%05x " "\n"' | sed -re"s/0x / /g")
if [ $? -gt 0 ]; then
echo "ERROR: Could not convert input" >&2
elif $SHOWTEXT; then
right=$(tr [:space:] . < "$tmpfile" | sed -re "s/.{$COLWIDTH}/|&|\n/g" | sed -re "s/^.{1,$((COLWIDTH+1))}\$/|&|/g")
pr -mts" " <(echo "$left") <(echo "$right")
else
echo "$left"
fi
rm "$tmpfile"