Il existe un mappage de mémoire privé anonyme désigné spécial (traditionnellement situé juste au-delà des données/bss, mais Linux moderne ajustera en fait l'emplacement avec ASLR). En principe, ce n'est pas mieux que n'importe quel autre mappage que vous pourriez créer avec mmap , mais Linux a quelques optimisations qui permettent d'étendre la fin de ce mappage (en utilisant le brk syscall) vers le haut avec un coût de verrouillage réduit par rapport à ce que mmap ou mremap encourrait. Cela le rend attractif pour malloc implémentations à utiliser lors de l'implémentation du tas principal.
Vous pouvez utiliser brk et sbrk vous-même pour éviter les "overhead malloc" dont tout le monde se plaint toujours. Mais vous ne pouvez pas facilement utiliser cette méthode en conjonction avec malloc il n'est donc approprié que lorsque vous n'êtes pas obligé de free n'importe quoi. Parce que vous ne pouvez pas. En outre, vous devez éviter tout appel de bibliothèque pouvant utiliser malloc intérieurement. C'est à dire. strlen est probablement sûr, mais fopen ne l'est probablement pas.
Appelez le sbrk comme si vous appeliez malloc . Il renvoie un pointeur vers la rupture actuelle et incrémente la rupture de ce montant.
void *myallocate(int n){
return sbrk(n);
}
Bien que vous ne puissiez pas libérer des allocations individuelles (car il n'y a pas de malloc-overhead , rappelez-vous), vous pouvez libérer tout l'espace en appelant le brk avec la valeur retournée par le premier appel à sbrk , donc rembobinant le frein .
void *memorypool;
void initmemorypool(void){
memorypool = sbrk(0);
}
void resetmemorypool(void){
brk(memorypool);
}
Vous pouvez même empiler ces régions, en supprimant la région la plus récente en rembobinant la rupture jusqu'au début de la région.
Encore une chose...
sbrk est également utile dans le code golf car il contient 2 caractères de moins que malloc .
Exemple exécutable minimal
Que fait l'appel système brk( ) ?
Demande au noyau de vous permettre de lire et d'écrire dans un morceau de mémoire contigu appelé le tas.
Si vous ne demandez pas, cela pourrait vous mettre en défaut de segmentation.
Sans brk :
#define _GNU_SOURCE
#include <unistd.h>
int main(void) {
/* Get the first address beyond the end of the heap. */
void *b = sbrk(0);
int *p = (int *)b;
/* May segfault because it is outside of the heap. */
*p = 1;
return 0;
}
Avec brk :
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b = sbrk(0);
int *p = (int *)b;
/* Move it 2 ints forward */
brk(p + 2);
/* Use the ints. */
*p = 1;
*(p + 1) = 2;
assert(*p == 1);
assert(*(p + 1) == 2);
/* Deallocate back. */
brk(b);
return 0;
}
GitHub en amont.
Ce qui précède peut ne pas atteindre une nouvelle page et ne pas segfault même sans le brk , voici donc une version plus agressive qui alloue 16 Mo et est très susceptible de segfault sans le brk :
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b;
char *p, *end;
b = sbrk(0);
p = (char *)b;
end = p + 0x1000000;
brk(end);
while (p < end) {
*(p++) = 1;
}
brk(b);
return 0;
}
Testé sur Ubuntu 18.04.
Visualisation de l'espace d'adressage virtuel
Avant brk :
+------+ <-- Heap Start == Heap End
Après brk(p + 2) :
+------+ <-- Heap Start + 2 * sizof(int) == Heap End
| |
| You can now write your ints
| in this memory area.
| |
+------+ <-- Heap Start
Après brk(b) :
+------+ <-- Heap Start == Heap End
Pour mieux comprendre les espaces d'adressage, vous devez vous familiariser avec la pagination :comment fonctionne la pagination x86 ?.
Pourquoi avons-nous besoin des deux brk et sbrk ?
brk pourrait bien sûr être implémenté avec sbrk + calculs de décalage, les deux existent juste pour plus de commodité.
Dans le backend, le noyau Linux v5.0 a un seul appel système brk qui est utilisé pour implémenter les deux :https://github.com/torvalds/linux/blob/v5.0/arch/x86/entry/syscalls/syscall_64.tbl#L23
12 common brk __x64_sys_brk
Est brk POSIX ?
brk était POSIX, mais il a été supprimé dans POSIX 2001, d'où la nécessité de _GNU_SOURCE pour accéder au wrapper glibc.
La suppression est probablement due à l'introduction mmap , qui est un sur-ensemble qui permet d'allouer plusieurs plages et davantage d'options d'allocation.
Je pense qu'il n'y a pas de cas valable où vous devriez utiliser brk au lieu de malloc ou mmap de nos jours.
brk contre malloc
brk est une ancienne possibilité d'implémenter malloc .
mmap est le nouveau mécanisme strictement plus puissant que tous les systèmes POSIX utilisent actuellement pour implémenter malloc . Voici un mmap exécutable minimal exemple d'allocation de mémoire.
Puis-je mélanger brk et malloc ?
Si votre malloc est implémenté avec brk , je n'ai aucune idée de comment cela peut ne pas faire exploser les choses, puisque brk ne gère qu'une seule plage de mémoire.
Je n'ai cependant rien trouvé à ce sujet dans la documentation de la glibc, par exemple :
- https://www.gnu.org/software/libc/manual/html_mono/libc.html#Resizing-the-Data-Segment
Les choses fonctionneront probablement là-bas, je suppose, depuis mmap est probablement utilisé pour malloc .
Voir aussi :
- Qu'est-ce qui est dangereux/hérité à propos de brk/sbrk ?
- Pourquoi appeler sbrk(0) deux fois donne-t-il une valeur différente ?
Plus d'informations
En interne, le noyau décide si le processus peut avoir autant de mémoire et réserve des pages de mémoire pour cette utilisation.
Ceci explique comment la pile se compare au tas :Quelle est la fonction des instructions push/pop utilisées sur les registres en assemblage x86 ?
Dans le diagramme que vous avez posté, la "pause" - l'adresse manipulée par brk et sbrk —est la ligne pointillée en haut du tas.
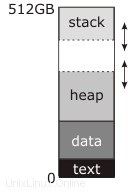
La documentation que vous avez lue décrit cela comme la fin du "segment de données" car dans les bibliothèques traditionnelles (pré-partagées, pré-mmap ) Unix le segment de données était continu avec le tas ; avant le démarrage du programme, le noyau chargeait les blocs "texte" et "données" dans la RAM en commençant à l'adresse zéro (en fait un peu au-dessus de l'adresse zéro, de sorte que le pointeur NULL ne pointait réellement sur rien) et définissait l'adresse de rupture sur la fin du segment de données. Le premier appel au malloc utiliserait alors sbrk pour déplacer la rupture et créer le tas entre les deux le haut du segment de données et la nouvelle adresse de rupture supérieure, comme indiqué dans le diagramme, et l'utilisation ultérieure de malloc l'utiliserait pour agrandir le tas si nécessaire.
Pendant ce temps, la pile commence au sommet de la mémoire et grandit vers le bas. La pile n'a pas besoin d'appels système explicites pour l'agrandir ; soit il démarre avec autant de RAM allouée qu'il peut en avoir (c'était l'approche traditionnelle) soit il y a une région d'adresses réservées sous la pile, à laquelle le noyau alloue automatiquement de la RAM lorsqu'il remarque une tentative d'écriture là-bas (c'est l'approche moderne). Dans tous les cas, il peut y avoir ou non une région "de garde" au bas de l'espace d'adressage qui peut être utilisée pour la pile. Si cette région existe (tous les systèmes modernes le font), elle est définitivement non cartographiée ; si soit la pile ou le tas essaie de s'y développer, vous obtenez une erreur de segmentation. Traditionnellement, cependant, le noyau n'essayait pas d'imposer une limite; la pile pourrait devenir le tas, ou le tas pourrait devenir la pile, et dans tous les cas, ils griffonneraient sur les données de l'autre et le programme planterait. Si vous étiez très chanceux, il planterait immédiatement.
Je ne sais pas d'où vient le nombre 512 Go dans ce diagramme. Cela implique un espace d'adressage virtuel de 64 bits, ce qui est incompatible avec la carte mémoire très simple que vous avez là-bas. Un véritable espace d'adressage 64 bits ressemble plus à ceci :

Legend: t: text, d: data, b: BSS
Ce n'est pas à distance à l'échelle, et cela ne devrait pas être interprété comme exactement comment un système d'exploitation donné fait des choses (après l'avoir dessiné, j'ai découvert que Linux place en fait l'exécutable beaucoup plus près de l'adresse zéro que je ne le pensais, et les bibliothèques partagées à des adresses étonnamment élevées). Les régions noires de ce diagramme ne sont pas cartographiées -- tout accès provoque une erreur de segmentation immédiate -- et elles sont gigantesques par rapport aux zones grises. Les régions gris clair sont le programme et ses bibliothèques partagées (il peut y avoir des dizaines de bibliothèques partagées); chacun a un indépendant segment de texte et de données (et segment "bss", qui contient également des données globales mais est initialisé à tous les bits à zéro plutôt que de prendre de l'espace dans l'exécutable ou la bibliothèque sur le disque). Le tas n'est plus nécessairement continu avec le segment de données de l'exécutable - je l'ai dessiné de cette façon, mais il semble que Linux, au moins, ne le fasse pas. La pile n'est plus rattachée au sommet de l'espace d'adressage virtuel, et la distance entre le tas et la pile est si énorme que vous n'avez pas à vous soucier de la traverser.
La cassure est toujours la limite supérieure du tas. Cependant, ce que je n'ai pas montré, c'est qu'il pourrait y avoir des dizaines d'allocations indépendantes de mémoire quelque part dans le noir, faites avec mmap au lieu de brk . (Le système d'exploitation essaiera de les éloigner du brk zone afin qu'ils n'entrent pas en collision.)