Il existe de nombreuses gammes d'outils bioinformatiques Linux largement utilisés dans ce domaine depuis longtemps. La bioinformatique a été caractérisée de plusieurs manières; cependant, il est souvent défini comme une combinaison de mathématiques, de calcul et de statistiques pour analyser des informations biologiques. L'objectif principal de l'outil bioinformatique est de développer un algorithme efficace afin que les similitudes de séquence puissent être mesurées en conséquence.
Meilleurs outils bioinformatiques pour Linux
Cet article a été écrit en se concentrant sur les outils bioinformatiques disponibles sur la plate-forme Linux. Tous les outils efficaces ont été discutés et revus en détail. De plus, vous trouverez les fonctionnalités essentielles, les propriétés et les liens de téléchargement de cet article. Par conséquent, passons en revue.
1. geWorkbench
geWorkbench peut être élaboré avec genome workbench est un outil bioinformatique basé sur Java qui fonctionne pour la génomique intégrée. Ses architectures de composants facilitent des plug-ins spécifiquement développés qui seraient configurés dans des applications bioinformatiques complexes. Actuellement, plus de soixante-dix plug-ins sont disponibles pour la prise en charge, la visualisation et l'analyse des données de séquence.
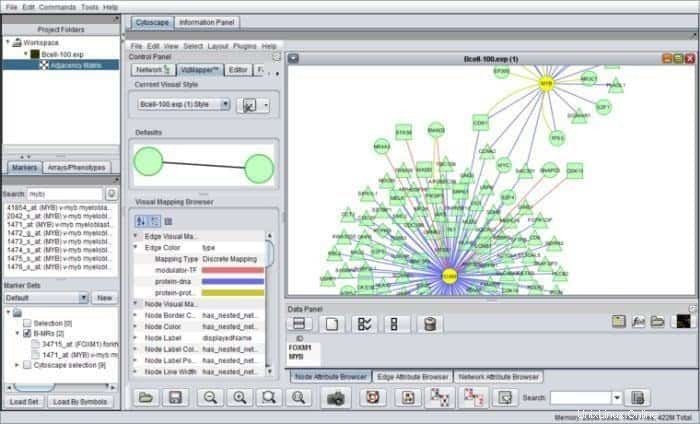
Fonctionnalités de geWorkbench
- Il est inclus avec de nombreux outils d'analyse informatique, à savoir le test t, les cartes auto-organisées, le regroupement hiérarchique, etc.
- Il est présenté avec des réseaux d'interaction moléculaire, la structure des protéines et des données sur les protéines.
- Il propose des voies d'intégration et d'annotation des gènes et collecte des données à partir de sources sélectionnées pour l'analyse de l'enrichissement de l'ontologie des gènes.
- Dans cet outil, les composants sont intégrés à la plate-forme de gestion des entrées et des sorties.
2. BioPerl
BioPerl est une collection d'outils Perl largement utilisés dans la plate-forme Linux en tant qu'outil bioinformatique pour la biologie moléculaire computationnelle. Il est continuellement utilisé dans les domaines de la bioinformatique dans un ensemble de normes de type CPAN. Cet outil bioinformatique Linux est bien documenté et disponible gratuitement dans les modules Perl. Parce qu'ils sont orientés objet, ces modules sont interdépendants pour accomplir la tâche.
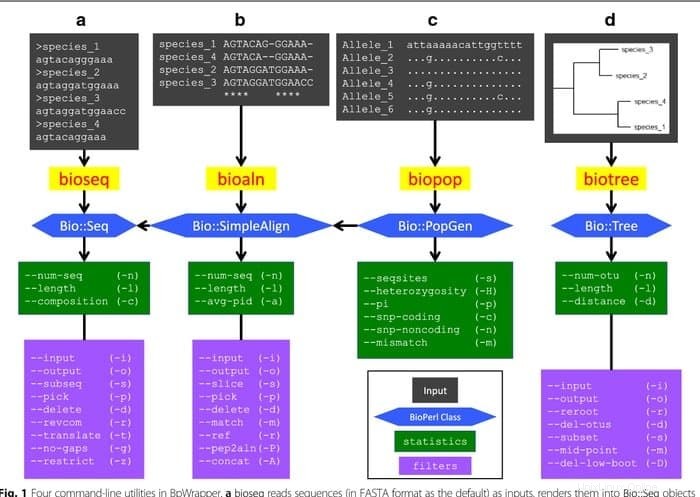
Caractéristiques de BioPerl
- À partir des bases de données locales et isolées, cet outil bioinformatique accède aux données de séquences nucléotidiques et peptidiques.
- Il manipule des séquences distinctes tout en transformant la forme de la base de données et de l'enregistrement du fichier.
- Il fonctionne comme un moteur de recherche bioinformatique où il recherche des séquences, des gènes et d'autres structures similaires sur l'ADN génomique.
- En générant et en manipulant des alignements de séquences, il développe des annotations de séquences lisibles par machine.
3. UGÈNE
UGENE est une source libre et un ensemble d'outils bioinformatiques intégrés pour Linux. Son interface utilisateur commune est intégrée aux applications bioinformatiques les plus utilisées et bien connues. De nombreux formats de données biologiques sont compatibles avec ses boîtes à outils ; ainsi, les données peuvent être récupérées à partir de sources distantes. Cet outil bioinformatique utilise des CPU et des GPU multicœurs pour fournir les performances maximales possibles afin d'optimiser ses activités de calcul.
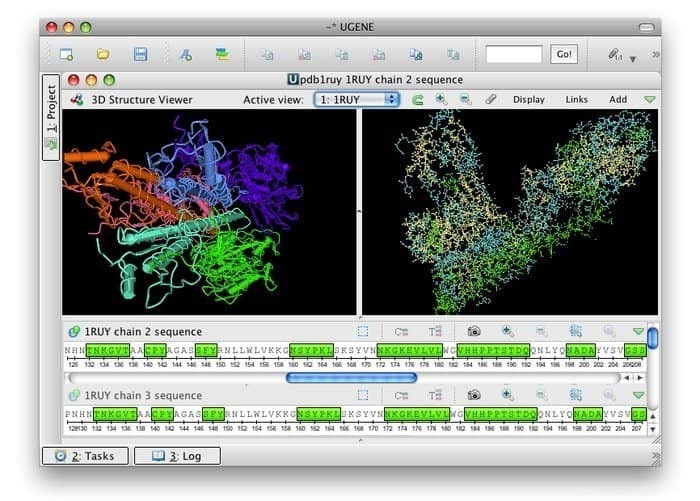
Caractéristiques d'UGENE
- Son interface utilisateur graphique offre plusieurs fonctionnalités, par exemple, la visualisation des chromatogrammes, l'éditeur d'alignement multiple et les génomes visuels et interactifs.
- Il ouvre la voie à une vue 3D aux formats PDB et MMDB, ainsi qu'à la prise en charge du mode stéréo anaglyphe.
- Il facilite l'affichage de l'arborescence phylogénétique, la visualisation du diagramme en points et le concepteur de requêtes peut rechercher des modèles d'annotation complexes.
- Cela peut ouvrir la voie à un flux de travail de calcul personnalisé pour le concepteur de flux de travail.
4. Biojava
Biojava est une source ouverte et exclusivement conçue pour le projet afin de fournir les outils java requis pour traiter les données biologiques. Il fonctionne pour de vastes gammes d'ensembles de données, par exemple, des routines analytiques et statistiques, des analyseurs pour les formats de fichiers courants. De plus, il facilite la manipulation de la séquence et de la structure 3D. Cet outil bioinformatique pour Linux vise à accélérer le développement rapide d'applications pour les ensembles de données biologiques.
Caractéristiques de Biojava
- Comprenant des fichiers de classe et des objets, il s'agit d'un package qui implémente du code Java pour une variété d'ensembles de données.
- Biojava peut être utilisé dans différents projets tels que Dazzel, Bioclips, Bioweka et Genious qui sont utilisés à diverses fins.
- Cela fonctionne pour les analyseurs de fichiers ainsi que pour les clients DAS et la prise en charge du serveur.
- Il est utilisé pour effectuer des analyses de séquence pour les interfaces graphiques et peut accéder aux bases de données BioSQL et Ensembl.
5. Biopython
L'outil bioinformatique Biophython développé par une équipe internationale de développeurs et écrit en programme python est utilisé pour le calcul biologique. Il offre un accès à une large gamme de formats de fichiers bioinformatiques, à savoir BLAST, Clustalw, FASTA, Genbank, et permet l'accès à des services en ligne tels que NCBI et Expasy.

Caractéristiques de Biopython
- Il est cumulé avec des modules python qui travaillent sur la création d'une séquence à caractère interactif et intégré.
- Cet outil bioinformatique peut effectuer différentes séquences, par exemple, la traduction, la transcription et les calculs de poids.
- Cet outil est exclusivement enrichi ; ainsi, la structure des protéines et le format de séquence sont gérés efficacement.
- Cet outil de bioinformatique Linux fonctionne pour les alignements ; ainsi, une norme peut être établie pour créer et traiter les matrices de substitution.
6. InterMine
InterMine est un outil bioinformatique open source pour Linux qui fonctionne comme un entrepôt de données pour intégrer et analyser des données biologiques. En tant que logiciel, les utilisateurs peuvent l'installer sur leur appareil et rendre les données disponibles sur la page Web. On pense qu'il s'agit de l'une des tables de données les plus dynamiques qui peuvent facilement explorer les données et faciliter le filtrage des données. Quelle est la colonne supplémentaire pour naviguer vers la page de rapport ?
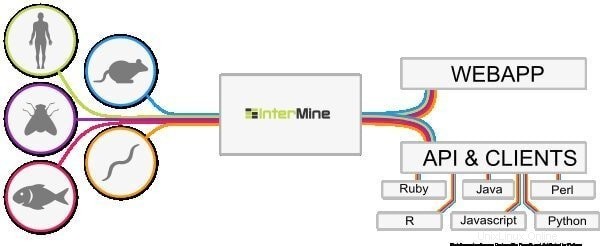
Caractéristiques d'InterMine
- Cela fonctionne avec un seul objet, par exemple, un gène, une protéine ou un site de liaison, et plusieurs listes telles qu'une liste de gènes ou une liste de protéines.
- Il peut être utilisé en plusieurs langues ; ainsi, différentes requêtes concernant les informations biométriques peuvent être recherchées dans plusieurs langues.
- Dans ce logiciel, quatre outils de recherche sont disponibles :la recherche de modèles, la recherche de mots-clés, le générateur de requêtes et la recherche de régions.
- Il prend en charge différents formats tels que Chado, GFF3, FASTA, GO et les fichiers d'association de gènes, UniProt XML, PSI XML, In Paranoid orthologs et Ensembl.
7. IVG
IGV, élaboré comme un visualiseur génomique interactif, est considéré comme l'un des outils de visualisation les plus efficaces qui peut facilement accéder à une base de données génomique étendue et interactive. Il peut offrir une grande variété de types de données avec annotation génomique ainsi que des données de séquence basées sur des tableaux et de nouvelle génération. Tout comme Google Maps, il peut naviguer dans un ensemble de données et faciliter le zoom et le panoramique de manière transparente sur le génome.
Caractéristiques d'IGV
- Il offre une intégration flexible de vastes gammes d'ensembles de données génomiques, y compris les lectures de séquences alignées, les mutations, les nombres de copies, etc.
- Il accélère l'exploration en temps réel de l'énorme ensemble de données de support en utilisant des formats de fichiers efficaces et multi-résolutions.
- Parmi des centaines et, dans une certaine mesure, jusqu'à des milliers d'échantillons, il permet la visualisation simultanée de différents types de données.
- Il permet de charger des ensembles de données à partir de sources locales et distantes, y compris des sources de données cloud, pour observer ses propres ensembles de données génomiques et ceux accessibles au public.
8. GROMAC
GROMACS est un simulateur moléculaire dynamique qui est inclus avec des outils d'analyse et de construction. C'est un package polyvalent et destiné à travailler sur la dynamique moléculaire; par exemple, il peut simuler l'équation newtonienne du mouvement de centaines à des milliers de particules. Il a été programmé pour fonctionner sur des molécules biochimiques à un stade précoce, à savoir les protéines et les lipides, liés par des interactions compliquées.
Caractéristiques de GROMACS
- Cet outil informatique Linux est convivial, contient des topologies et des fichiers de paramètres, et il est écrit en texte clair.
- Le langage de script n'a pas été utilisé ; ainsi, tous les programmes sont exploités avec une option de ligne de commande d'interface simple pour les fichiers d'entrée et de sortie.
- En cas de problème, de nombreux messages d'erreur et vérifications de cohérence sont effectués.
- Tous les programmes sont facilités par l'interface utilisateur graphique intégrée.
9. Établi de taverne
Le Taverna Workbench est un outil open source programmé pour concevoir et exécuter des flux de travail bioinformatiques créés par le projet myGrid. Une gamme de logiciels peut être intégrée à cet outil, y compris le service Web SOAP et REST. Il collabore avec des organisations distinctes telles que l'Institut européen de bioinformatique, la banque de données ADN du Japon, le Centre national d'information sur la biotechnologie, SoapLab, BioMOBY et EMBOSS.
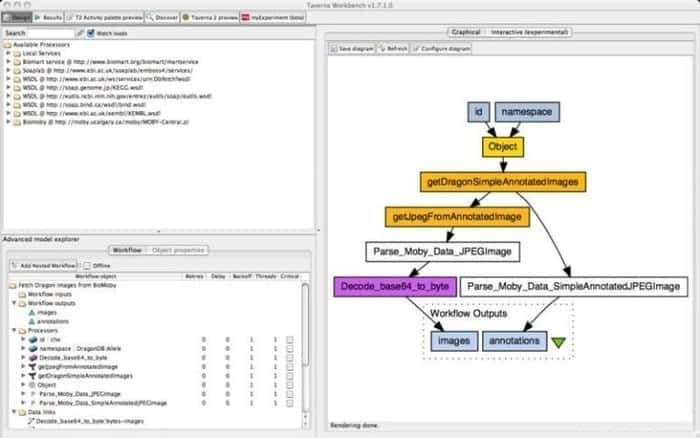
Caractéristiques de l'établi Taverna
- Il est entièrement conçu avec le flux de travail graphique pour trouver, développer et exécuter des flux de travail.
- Il a été conçu avec un flux de travail entièrement graphique ; de plus, des onglets discrets sont utilisés pour la conception.
- Des annotations sont données pour décrire les flux de travail, les services, les entrées et les sorties avec une fonction d'aide intégrée.
- Le flux de travail précédemment utilisé est stocké dans cet outil, même s'il peut enregistrer le flux de travail des entrées utilisées dans le fichier.
10. GAUFRAGE
EMBOSS qui implique European Molecular Biology Open Software Suite. Il s'agit d'un ensemble de logiciels qui a été développé pour les besoins de la communauté de la biologie moléculaire. Cet outil bioinformatique Linux peut être utilisé à différentes fins. Par exemple, il est fonctionnel dans divers formats de données automatiquement. De plus, il peut collecter des données de manière séquentielle à partir de la page Web.
Caractéristiques d'EMBOSS
- EMBOSS est inclus avec des centaines d'applications, à savoir l'alignement de séquences et la recherche rapide de bases de données avec des modèles de séquences.
- En outre, il dispose d'une fonction d'identification des motifs protéiques, y compris l'analyse des domaines et l'analyse des modèles de séquences nucléotidiques.
- Sa boîte à outils a été conçue de manière appropriée pour répondre à l'application et au flux de travail bioinformatiques.
- Il a été programmé avec des bibliothèques supplémentaires pour gérer également de nombreux autres problèmes pertinents.
11. Oméga clustal
Clustal Omega fonctionne sur les protéines, et RNA/DNA est un programme d'alignement de séquences multiples conçu à des fins générales. Il peut gérer efficacement des millions d'ensembles de données dans un délai raisonnable ; de plus, il produit des MSA de haute qualité. Dans cet outil bioinformatique Linux, il existe un processus dans lequel l'utilisateur doit laisser la séquence de fichiers en mode par défaut. Cela est aligné et regroupé pour générer un arbre de guidage, et cela permet finalement de former une séquence d'alignement progressif.
Caractéristiques de Clustal Omega
- Cela facilite l'alignement des alignements existants les uns avec les autres et, qui plus est, l'alignement d'une séquence sur un alignement pour l'utilisation d'un modèle de Markov caché.
- Il existe une fonctionnalité appelée alignement de profil externe qui fait référence à une nouvelle séquence d'homologues pour le modèle de Markov caché.
- Les HMM sont utilisés pour le Clustal Omega pour le moteur d'alignement tiré du package HHalign de Johannes Soeding.
- Clustal Omega permet trois types d'entrées de séquence :le profil, l'alignement de la séquence et le HMM.
12. BLAST
L'outil de recherche d'alignement local de base ou BLAST est utilisé pour trouver la similitude entre les séquences biologiques. Il peut trouver des correspondances pertinentes entre les séquences nucléotidiques et protéiques et en montrer l'importance statistique. Les séquences de requêtes sont structurées avec différents types de BLAST. De plus, cet outil est largement cultivé sur des gènes inconnus florissants chez divers animaux, et il permet de cartographier des ensembles de données basés sur des séquences grâce à une analyse qualitative.
Caractéristiques de BLAST
- Le nucléotide-nucléotide megaBLAST propose de rechercher et d'optimiser des types de séquences très similaires.
- De plus, le nucléotide-nucléotide BLASTN fonctionne un peu différemment lorsqu'il recherche des séquences à distance.
- De plus, BLASTP effectue la recherche de relations et de comparaisons protéine-protéine, et sa formule est utilisée pour différentes autres recherches.
- TBLASTN se concentre sur la requête de nucléotides par rapport à l'ensemble de données sur les protéines et peut traduire la base de données à la volée.
13. Lit
Le logiciel de bioinformatique Bedtool est un couteau suisse d'outils utilisés pour de vastes gammes d'analyses génomiques. L'arithmétique génomique utilise très largement cet outil, ce qui implique qu'elle peut trouver la théorie des ensembles avec lui. Par exemple, les bedtools permettent de compter, de compléter et de mélanger les intersections, de fusionner les intervalles génomiques de plusieurs fichiers et de générer un format de génome particulier tel que BAM, BED, GFF/GTF, VCF.
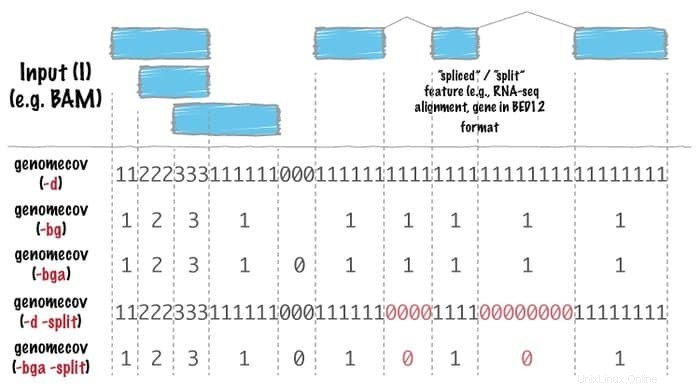
Caractéristiques des outils de lit
- Dans cet outil de bioinformatique Linux, chacun est conçu pour effectuer une tâche particulièrement simple, par exemple, croiser deux fichiers d'intervalle.
- L'analyse compliquée et sophistiquée est effectuée à l'aide d'une combinaison d'outils de lit.
- Cet outil est développé dans le laboratoire Quinlan de l'université d'Utah par un chercheur du groupe.
- Comme il existe de nombreuses options dans cet outil, il peut être utilisé à plusieurs fins dans le domaine de la bioinformatique.
14. Bioclipse
L'outil bioinformatique Bioclipse Linux défini avec Workbench pour les sciences de la vie est un logiciel open source basé sur Java. Il fonctionne sur la plate-forme visuelle qui comprend la plate-forme client riche Eclipse pour la chimio et la bioinformatique. Il est présenté avec une architecture de plugin. Cela implique en outre l'architecture de plug-in de pointe, les fonctionnalités et les interfaces visuelles d'Eclipse, telles que le système d'aide, les mises à jour logicielles également incluses.
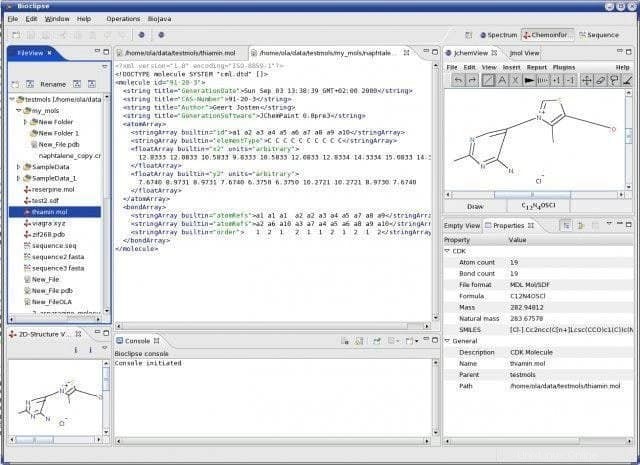
Caractéristiques de Bioclipse
- Les séquences biologiques, à savoir l'ARN, l'ADN et les protéines, sont gérées avec le bioclipse.
- Biojava aide également à fournir des fonctionnalités bioinformatiques de base ; des éditeurs graphiques pour les alignements de séquences également.
- Il est utilisé pour la pharmacologie et la découverte de médicaments, ainsi que le site de découverte du métabolisme.
- Enfin, il fonctionne sur la fonctionnalité Web sémantique, parcourt de vastes collections de composés et modifie les structures chimiques.
15. Bioconducteur
La bioinformatique largement utilisée dans la plate-forme Linux est un outil bioinformatique open-source et gratuit, utilisé de manière cohérente en biologie médicale pour l'analyse à haut débit. Il utilise principalement la programmation statistique R; néanmoins, il contient également un autre langage de programmation. Ce logiciel est conçu en se concentrant sur quelques objectifs ; par exemple, il vise à établir un développement collaboratif et à garantir l'utilisation massive de logiciels innovants.
Caractéristiques du bioconducteur
- Ce logiciel peut analyser une gamme de données, par exemple, des matrices d'oligonucléotides, l'analyse de séquences, un cytomètre en flux et peut générer une base de données graphique et statistique robuste.
- Avoir des vignettes et des documents dans chaque package binoculaire peut fournir une description textuelle et axée sur les tâches de la fonctionnalité de ce package.
- Il peut générer des données en temps réel concernant le microréseau associé et d'autres données génomiques, ainsi que des métadonnées biologiques.
- En outre, il peut analyser des gènes express tels que LIMMA, cDNA Arrays, Affy Arrays, RankProd, SAM, R/maanova, Digital Gene Expression, etc.
16. AMPHORE
AMPHORA, qui signifie Automated Phylogenomic infeRence Application, est un outil de flux de travail bioinformatique open source. Une autre version d'AMPHORA appelée AMPHORA2 possède des gènes marqueurs phylogénétiques bactériens et 104 archéens. Plus important encore, cela fonctionne pour créer des informations entre les ensembles de données phylogénétiques et génétiques rencontrées.
Caractéristiques d'AMPHORA
- Parce qu'il s'agit de gènes uniques, AMPHORA2 est le plus approprié pour déduire la composition taxonomique des bactéries.
- De plus, il peut également déduire la composition taxonomique des communautés d'archées à partir de la séquence métagénomique du fusil de chasse.
- Au départ, AMPHORA a été utilisé pour analyser les données métagénomiques de la mer des Sargasses.
- Cependant, de nos jours, AMPHORA2 est de plus en plus utilisé pour analyser les données métagénomiques pertinentes à cet égard.
17. Anduril
Anduril est un logiciel de bioinformatique basé sur des composants open source pour Linux qui fonctionne pour créer un cadre de flux de travail concernant l'analyse de données scientifiques. Cet outil est développé par le Laboratoire de biologie des systèmes de l'Université d'Helsinki. Cet outil bioinformatique pour Linux est conçu pour permettre une analyse de données efficace, flexible et systématique, en particulier dans le domaine de la recherche biomédicale.
Caractéristiques d'Abduril
- Cela fonctionne dans un flux de travail où différents systèmes de traitement sont interdépendants ; par exemple; une sortie d'un processus peut fonctionner comme une entrée d'autres.
- L'outil Anduril principal est écrit en Java, tandis que les autres composants sont écrits dans différentes applications.
- Dans ses différentes étapes, de nombreuses activités ont lieu, telles que ; il crée des données, génère des rapports et importe également des données.
- Sa configuration de flux de travail peut être effectuée avec un langage de script simple et puissant, à savoir Andurilscript.
18. Serveur LabKey
LabKey Server est un choix privilégié pour les scientifiques utilisés dans les laboratoires pour intégrer la recherche, analyser et partager des données biomédicales. Un référentiel de données sécurisé est utilisé dans cet outil qui facilite les requêtes, les rapports et la collaboration sur le Web au sein d'un large éventail de bases de données. Outre la plate-forme sous-jacente donnée, de nombreux autres instruments scientifiques peuvent être ajoutés dans cette application.
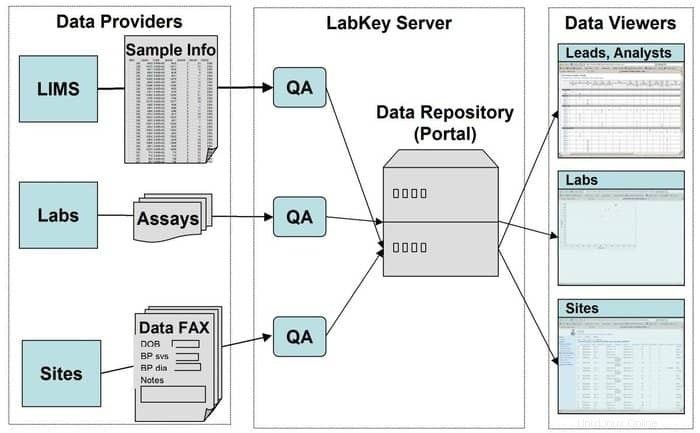
Fonctionnalités de LabKey Server
- LabKey Server est présenté avec tous les types de données biomédicales. Par exemple, cytométrie en flux, puce à ADN, spectrométrie de masse, microplaque, ELISpot, ELISA, etc.
- Dans cet outil, un pipeline de traitement de données personnalisable exécute toutes les activités pertinentes.
- Il est présenté avec des études d'observation qui facilitent la gestion d'études longitudinales à grande échelle sur les participants.
- La protéomique est utilisée pour traiter des données de spectrométrie de masse à haut débit à l'aide d'un outil spécifique, à savoir X ! Tandem.
19. Mothur
Mothur est un outil bioinformatique open source largement utilisé dans le domaine biomédical pour le traitement de données biologiques. Il s'agit d'un progiciel fréquemment utilisé pour analyser l'ADN de microbes non cultivés. Mothur est un outil bioinformatique Linux qui peut traiter les données générées à partir de méthodes de séquençage d'ADN, y compris le pyro-séquençage 454.
Caractéristiques de Mothur
- Il s'agit d'un logiciel unique capable de gérer les données de la communauté, d'analyser et de créer une séquence.
- Un support de documentation communautaire à grande échelle et une autre forme de support sont fournis avec cet outil.
- On pense que Mothur est l'outil bioinformatique le plus important analysant les séquences de gènes d'ARNr 16S.
- Une communauté dédiée et des didacticiels sont disponibles dans cet outil pour expliquer comment utiliser Sanger, PacBio, IonTorrent, 454 et Illumina (MiSeq/HiSeq).
20. VOTCA
VOTCA signifie Versatile Object-oriented Toolkit for Coarse-graining Applications, qui est considéré comme un outil bioinformatique efficace avec un package de modélisation à grain grossier qui analyse principalement les données de biologie moléculaire. Il vise à développer des techniques systématiques de granulation grossière ainsi qu'à simuler une charge microscopique pour transporter des semi-conducteurs désordonnés.
Caractéristiques de VOTCA
- VOTCA est principalement présenté avec trois parties principales :la boîte à outils de granularité grossière, la boîte à outils de transport de charge et la boîte à outils de transport d'excitation.
- Les trois fonctionnalités principales proviennent de la bibliothèque d'outils VOTCA qui implémente des procédures partagées.
- VOTCA utilise des méthodes de granularité grossière pour récolter les meilleurs résultats des activités pertinentes.
- Ce logiciel est présenté avec une boîte à outils de transport d'excitation où les packages orca DFT sont pris en charge dans une large mesure.
Réflexion finale
Pour résumer le tout, il convient de mentionner ici que toutes les applications bioinformatiques mentionnées ci-dessus sont largement utilisées dans ce domaine. Ces outils bioinformatiques Linux sont utilisés depuis longtemps dans les sciences médicales, la pharmacologie, l'invention de médicaments et les domaines concernés. Enfin, vous êtes prié de laisser vos deux sous concernant cet article. De plus, si vous trouvez que cet article en vaut la peine, n'oubliez pas de l'aimer, de le partager et de le commenter. Votre précieux commentaire sera apprécié.