Vous êtes-vous déjà demandé comment votre ordinateur communique avec d'autres ordinateurs sur votre réseau local ou avec d'autres systèmes sur Internet ?
Comprendre les subtilités de la façon dont les ordinateurs interagissent est une partie importante de la mise en réseau et présente autant d'intérêt pour un administrateur système que pour un développeur. Dans cet article, nous tenterons de discuter du concept de communication à partir du niveau fondamental de base qui doit être compris par tout le monde.
SUITE DE PROTOCOLE TCP/IP
Les communications entre les ordinateurs d'un réseau se font par le biais de combinaisons de protocoles. La suite de protocoles la plus largement utilisée et la plus largement disponible est la suite de protocoles TCP/IP. Une combinaison de protocole consiste en une architecture en couches où chaque couche décrit certaines fonctionnalités qui peuvent être exécutées par un protocole. Chaque couche a généralement plus d'une option de protocole pour s'acquitter de la responsabilité à laquelle la couche adhère. TCP/IP est normalement considéré comme un système à 4 couches. Les 4 couches sont les suivantes :
- Couche d'application
- Couche de transport
- Couche réseau
- Couche de liaison de données
1. Couche applicative
Il s'agit de la couche supérieure de la suite de protocoles TCP/IP. Cette couche comprend des applications ou des processus qui utilisent des protocoles de couche de transport pour transmettre les données aux ordinateurs de destination.
À chaque couche, il existe certaines options de protocole pour effectuer la tâche désignée à cette couche particulière. Ainsi, la couche application dispose également de divers protocoles que les applications utilisent pour communiquer avec la deuxième couche, la couche transport. Certains des protocoles de couche d'application populaires sont :
- HTTP (protocole de transfert hypertexte)
- FTP (protocole de transfert de fichiers)
- SMTP (protocole simple de transfert de courrier)
- SNMP (protocole de gestion de réseau simple) etc
2. Couche Transport
Cette couche fournit l'épine dorsale du flux de données entre deux hôtes. Cette couche reçoit des données de la couche d'application au-dessus d'elle. De nombreux protocoles fonctionnent au niveau de cette couche, mais les deux protocoles les plus couramment utilisés au niveau de la couche de transport sont TCP et UDP.
TCP est utilisé lorsqu'une connexion fiable est requise tandis que UDP est utilisé en cas de connexions non fiables.
TCP divise les données (provenant de la couche application) en morceaux de taille appropriée, puis passe ces morceaux sur le réseau. Il accuse réception des paquets reçus, attend les accusés de réception des paquets qu'il a envoyés et définit un délai d'expiration pour renvoyer les paquets si les accusés de réception ne sont pas reçus à temps. Le terme « connexion fiable » est utilisé lorsqu'il n'est pas souhaité de perdre des informations transférées sur le réseau via cette connexion. Ainsi, le protocole utilisé pour ce type de connexion doit fournir le mécanisme permettant d'obtenir cette caractéristique souhaitée. Par exemple, lors du téléchargement d'un fichier, il n'est pas souhaitable de perdre des informations (octets) car cela pourrait entraîner la corruption du contenu téléchargé.
UDP fournit un service comparativement plus simple mais peu fiable en envoyant des paquets d'un hôte à un autre. UDP ne prend aucune mesure supplémentaire pour s'assurer que les données envoyées sont reçues ou non par l'hôte cible. Le terme « connexion non fiable » est utilisé lorsque la perte de certaines informations n'entrave pas l'exécution de la tâche via cette connexion. Par exemple, lors de la diffusion d'une vidéo, la perte de quelques octets d'informations pour une raison quelconque est acceptable car cela ne nuit pas beaucoup à l'expérience de l'utilisateur.
3. Couche réseau
Cette couche est également appelée couche Internet. L'objectif principal de cette couche est d'organiser ou de gérer le mouvement des données sur le réseau. Par mouvement de données, nous entendons généralement le routage des données sur le réseau. Le principal protocole utilisé à cette couche est IP. Tandis que ICMP (utilisé par la commande "ping" populaire) et IGMP sont également utilisés à cette couche.
4. Couche de liaison de données
Cette couche est également appelée couche d'interface réseau. Cette couche se compose normalement de pilotes de périphériques dans le système d'exploitation et de la carte d'interface réseau connectée au système. Les pilotes de périphérique et la carte d'interface réseau s'occupent des détails de communication avec le support utilisé pour transférer les données sur le réseau. Dans la plupart des cas, ce média se présente sous la forme de câbles. Certains des protocoles célèbres utilisés à cette couche incluent ARP (protocole de résolution d'adresse), PPP (protocole point à point), etc.
EXEMPLE DE CONCEPT TCP/IP
Il convient de noter que l'interaction entre deux ordinateurs sur le réseau via la suite de protocoles TCP/IP se déroule sous la forme d'une architecture client-serveur.
Le client demande un service pendant que le serveur traite la demande du client.
Maintenant, puisque nous avons discuté des couches sous-jacentes qui aident à ce flux de données de l'hôte à la cible sur un réseau. Prenons un exemple très simple pour rendre le concept plus clair.
Tenez compte du flux de données lorsque vous ouvrez un site Web.
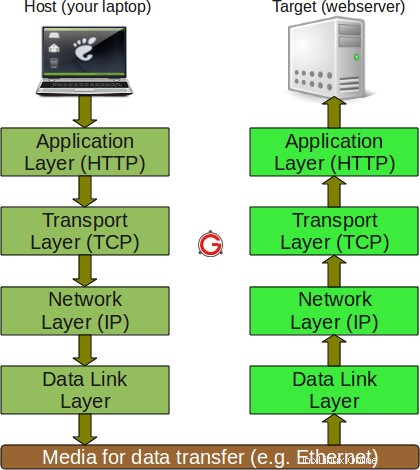
Comme le montre la figure ci-dessus, les informations circulent vers le bas à travers chaque couche sur la machine hôte. Au niveau de la première couche, étant donné que le protocole http est utilisé, une requête HTTP est formée et envoyée à la couche de transport.
Ici, le protocole TCP attribue plus d'informations (comme le numéro de séquence, le numéro de port source, le numéro de port de destination, etc.) aux données provenant de la couche supérieure afin que la communication reste fiable, c'est-à-dire qu'une trace des données envoyées et des données reçues puisse être maintenue. /P>
À la couche inférieure suivante, IP ajoute ses propres informations aux données provenant de la couche de transport. Ces informations aideraient les paquets à voyager sur le réseau. Enfin, la couche liaison de données s'assure que le transfert de données vers/depuis le support physique se fait correctement. Là encore, la communication effectuée au niveau de la couche liaison de données peut être fiable ou non.
Ces informations voyagent sur le support physique (comme Ethernet) et atteignent la machine cible.
Maintenant, sur la machine cible (qui dans notre cas est la machine sur laquelle le site Web est hébergé), la même série d'interactions se produit, mais dans l'ordre inverse.
Le paquet est d'abord reçu au niveau de la couche liaison de données. À cette couche, les informations (qui ont été remplies par le protocole de couche liaison de données de la machine hôte) sont lues et le reste des données est transmis à la couche supérieure.
De même, au niveau de la couche réseau, les informations définies par le protocole de couche réseau de la machine hôte sont lues et le reste des informations est transmis à la couche supérieure suivante. La même chose se produit au niveau de la couche de transport et finalement la requête HTTP envoyée par l'application hôte (votre navigateur) est reçue par l'application cible (serveur de site Web).
On pourrait se demander ce qui se passe lorsque des informations particulières à chaque couche sont lues par les protocoles correspondants sur la machine cible ou pourquoi sont-elles nécessaires ? Eh bien, comprenons cela par un exemple de protocole TCP présent au niveau de la couche de transport. Au niveau de la machine hôte, ce protocole ajoute des informations telles que le numéro de séquence à chaque paquet envoyé par cette couche.
Sur la machine cible, lorsque le paquet atteint cette couche, le TCP de cette couche prend note du numéro de séquence du paquet et envoie un accusé de réception (qui est reçu numéro de séquence + 1).
Maintenant, si l'hôte TCP ne reçoit pas l'accusé de réception dans un délai spécifié, il renvoie le même paquet. Donc, de cette façon, TCP s'assure qu'aucun paquet ne soit perdu. Nous voyons donc que le protocole à chaque couche lit les informations définies par son homologue pour atteindre la fonctionnalité de la couche qu'il représente.
PORTS, SERVEURS ET NORMES
Sur une machine particulière, un numéro de port couplé à l'adresse IP de la machine est appelé socket. Une combinaison d'IP et de port sur le client et le serveur est connue sous le nom de quatre tuples. Ce quadruplet identifie de manière unique une connexion. Dans cette section, nous verrons comment les numéros de port sont choisis.
Vous savez déjà que certains des services les plus courants tels que FTP, telnet, etc. fonctionnent sur des numéros de port bien connus. Alors que le serveur FTP s'exécute sur le port 21, le serveur Telent s'exécute sur le port 23. Ainsi, nous voyons que certains services standard fournis par toute implémentation de TCP/IP ont des ports standard sur lesquels ils s'exécutent. Ces numéros de port standard sont généralement choisis entre 1 et 1023. Les ports bien connus sont gérés par Internet Assigned Numbers Authority (IANA).
Alors que la plupart des serveurs standard (qui sont fournis par l'implémentation de la suite TCP/IP) s'exécutent sur des numéros de port standard, les clients n'ont pas besoin d'un port standard pour s'exécuter.
Les numéros de port client sont appelés ports éphémères. Par éphémère, nous entendons de courte durée. En effet, un client peut se connecter au serveur, faire son travail, puis se déconnecter. Nous avons donc utilisé le terme "courte durée de vie" et aucun port standard n'est donc requis pour eux.
De plus, comme les clients ont besoin de connaître les numéros de port des serveurs pour s'y connecter, la plupart des serveurs standard fonctionnent sur des numéros de port standard.
Les ports réservés aux clients vont généralement de 1024 à 5000. Les numéros de port supérieurs à 5000 sont réservés aux serveurs qui ne sont pas standard ou bien connus.
Si nous regardons le fichier ‘/etc/services’, vous trouverez la plupart des serveurs standard et le port sur lequel ils tournent.
$ cat /etc/services systat 11/tcp users daytime 13/udp netstat 15/tcp qotd 17/tcp quote msp 18/udp chargen 19/udp ttytst source ftp-data 20/tcp ftp 21/tcp ssh 22/tcp ssh 22/udp telnet 23/tcp ... ... ...
Comme vous le voyez dans le fichier /etc/services, FTP a le numéro de port 21, telent a le numéro de port 23, etc. Vous pouvez utiliser la commande 'grep' sur ce fichier pour trouver n'importe quel serveur et son port associé.
En ce qui concerne les normes, les quatre organisations/groupes suivants gèrent la suite de protocoles TCP/IP. L'IRTF et l'IETF relèvent de l'IAB.
- La société Internet (ISOC)
- Comité d'architecture Internet (IAB). L'IAB relève de l'ISOC.
- Groupe de travail sur l'ingénierie Internet (IETF)
- Groupe de travail sur la recherche sur Internet (IRTF)