La commande tr sous Linux traduit un jeu de caractères en un autre. Il peut remplacer un caractère ou un ensemble de caractères par un autre caractère ou ensemble de caractères. tr lit l'entrée de l'entrée standard et affiche la sortie sur la sortie standard. L'entrée peut également être donnée dans un fichier ou en utilisant la commande echo.
tr est l'abréviation de traduire .
Le format standard de la commande tr est :
$ tr [option] [char_set 1] [char_set 2]
En fonction de la ou des options spécifiées, la commande tr remplace le jeu de caractères dans "set 1" par "set 2".
Remplacement des caractères
Pour remplacer des caractères à l'aide de la commande tr, mentionnez simplement les caractères à remplacer dans le 1er jeu et les caractères à remettre à leur place après le remplacement dans le 2ème jeu.
$ tr 'a' '1'
Cette commande attendra l'entrée de STDIN. Après avoir obtenu l'entrée, la sortie à l'écran apparaîtra avec toutes les instances de "a" remplacées par "1".

1. Utiliser echo avec la commande tr
L'exemple ci-dessus lit l'entrée de STDIN. La commande Echo peut fournir une entrée avec la commande tr. Utilisez l'opérateur Pipe(|) pour exécuter les commandes ensemble.
$ echo "apples and bananas" | tr 'a' '1'

2. Prise d'entrée à partir d'un fichier
tr peut également prendre son entrée à partir d'un fichier. Ceci est utile lorsque la traduction doit être effectuée sur une volumineuse collection de texte. L'opérateur de redirection (<) est utilisé pour donner une entrée à partir d'un fichier.
$ tr 'a' '1' < input.txt

input.txt contient le même texte que l'exemple ci-dessus.
Pour enregistrer le texte dans un fichier, utilisez l'opérateur redirection(>) pour rediriger la sortie vers un fichier.
$ tr 'a' '1' < input.txt > output.txt
Changer la casse du texte avec la commande tr
L'une des utilisations les plus courantes de la commande tr consiste à traduire du texte de minuscules en majuscules ou vice-versa.
Comme tr fonctionne sur des ensembles de caractères, nous pouvons explicitement mentionner l'ensemble de caractères minuscules comme ensemble 1 et l'ensemble de caractères majuscules comme ensemble 2 pour effectuer le changement.
$ echo "apples and bananas" | tr a-z A-Z
Définir a-z représente l'ensemble des lettres minuscules et l'ensemble A-Z représente l'ensemble des lettres majuscules.
Une autre façon de faire la même chose est :
$ echo "apples and bananas" | tr [:lower:] [:upper:]
Ici, [:lower:] représente l'ensemble des alphabets minuscules et [:upper:] représente l'ensemble des alphabets majuscules.

Suppression de caractères avec tr
tr a la capacité de supprimer un ensemble de caractères du texte. Ceci est réalisé en utilisant tr avec -d commande.
$ echo "apples and bananas" | tr -d 'n'
Cette commande éliminera toutes les occurrences de ‘n’ dans le texte.

Pour supprimer les occurrences de plusieurs caractères, mentionnez tous les caractères entre guillemets simples.
$ echo "apples and bananas" | tr -d 'na'
Cette commande supprimera les occurrences de ‘n’ et 'a'

Étant donné que tr fonctionne au niveau du caractère, toutes les occurrences individuelles de ‘n’ et 'a' sont enlevés. Il est facile de se tromper et de penser que la commande ne supprimera que les occurrences de ‘na’ survenant dans cette séquence. Cependant, ce n'est pas le cas.
Rassemblez plusieurs occurrences en une seule
Compresser plusieurs occurrences en une seule peut être utile pour compresser le texte. Il est souvent utilisé pour supprimer les espaces multiples entre les lignes.
-s l'option est utilisée avec tr pour presser.
$ echo "apples and bananas" | tr -s 'p'

Les occurrences multiples de "p" dans pomme ont été réduites à une seule occurrence.
$ echo "apples and bananas" | tr -s 'na' '1'
La sortie de cette commande est équivalente à celle du premier remplacement des occurrences des caractères ‘n’ et ‘a ‘ avec ‘1’ , suivie d'une opération de compression. Pour comparer, regardez la deuxième commande dans la sortie. Le résultat de la deuxième commande est une simple substitution de caractères.
Pressons tous les 1 dans la sortie de la deuxième commande pour voir si nous obtenons la même sortie que la première.

Nous obtenons la même sortie que la première commande dans la sortie.
Pour supprimer les espaces blancs consécutifs dans le texte, utilisez :
$ echo "apples and bananas" | tr -s " "

Sinon [:space:] peut être utilisé à la place de " "
$ echo "apples and bananas" | tr -s [:space:]
Extraire des chiffres du texte
Pour réaliser des opérations où seul un ensemble particulier de caractères doit être conservé. Il est préférable d'utiliser -c option. -c est utilisé pour compléter l'ensemble.
Le complément d'un ensemble signifie tout ce qui n'est pas contenu dans cet ensemble.
$ echo " Home : 011 1234 4321" | tr -cd [:digit:],'\n'

Mentionner ‘\n’ (nouvelle ligne) est important car sinon la sortie n'a pas de retour à la ligne et se confond avec la ligne suivante dans le terminal. Une autre raison de ne pas ignorer les retours à la ligne lors de la suppression de caractères est que votre fichier peut avoir plusieurs chiffres sur plusieurs lignes. Si le caractère de nouvelle ligne est supprimé, tous les chiffres apparaîtront ensemble sans espace.

Extraire des mots du texte
Ce processus est l'exact opposé de celui effectué ci-dessus. Ici, nous allons ignorer les chiffres et nous concentrer uniquement sur les mots composés de lettres.
$ echo " Home : 011 1234 4321" | tr -d [:digit:]

Dans cet exemple, nous avons simplement supprimé tous les chiffres de notre texte.
Une façon plus contrôlée de faire la même chose serait d'utiliser le complément.
$ echo " Home : 011 1234 4321" | tr -cd [:alpha:],'\n'

[:alpha :] représente l'ensemble des alphabets. Considérez-le comme une collection des deux ensembles, inférieur et supérieur.
[:alpha:] = [:lower:] + [:upper:]
Compter le nombre d'occurrences de mots
Compter le nombre de fois qu'un mot apparaît dans un texte peut être utile pour construire des histogrammes. Il est également très utile pour créer des modèles probabilistes pour la détection des spams par e-mail.
Commençons par créer un fichier avec des mots récurrents.

Parfois, il peut être utile d'afficher chaque mot du texte dans une nouvelle ligne.
$ tr -cs "[:alpha:]" "\n" < input.txt
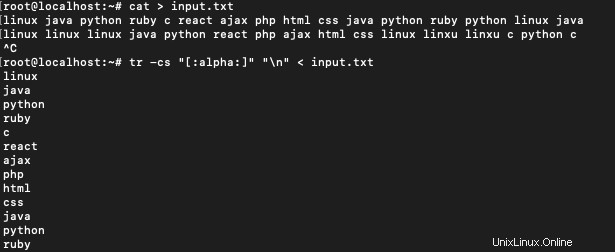
Pour obtenir le nombre d'occurrences de chaque mot, utilisez :
$ tr -cs "[:alpha:]" "\n" < input.txt | sort | uniq -c
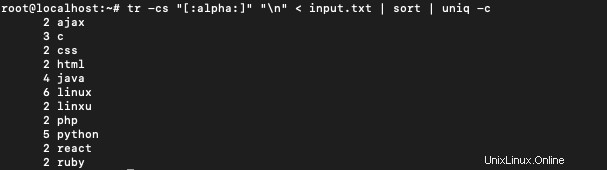
Trier est utilisé pour trier la liste lexicographiquement. uniq -c compte les occurrences individuelles de chaque mot et affiche le résultat sous la forme d'une liste de mots avec un décompte.
Conclusion
La commande tr est utile pour effectuer des traductions basées sur des caractères. Lorsqu'elle est combinée avec d'autres commandes comme sort ou uniq, la commande tr peut s'avérer très puissante. En savoir plus sur la commande tr sur sa page de manuel. Lors de l'application de transformations sur une ligne entière, la commande sed peut être utilisée.