Si vous recherchez une plate-forme d'analyse de données en temps réel, Jack Wallen pense qu'Apache Druid est difficile à battre. Découvrez comment faire fonctionner cet outil, puis comment charger des exemples de données.
Apache Druid est une base de données d'analyse en temps réel conçue pour éclairer des analyses rapides par tranches et dés sur des ensembles de données massifs. Vous pouvez facilement exécuter Apache Druid à partir d'une version de bureau de Linux - ou d'un serveur Linux avec une interface graphique - puis charger les données pour commencer à les analyser.
Apache Druid inclut des fonctionnalités telles que :
- Stockage orienté colonne
- Index de recherche natifs
- Diffusion et ingestion par lots
- Schémas flexibles
- Partitionnement optimisé en temps
- Prise en charge SQL
- Évolutivité horizontale
- Opération facile
Apache Druid est une excellente option pour les cas d'utilisation qui nécessitent une ingestion en temps réel, des requêtes rapides et une disponibilité élevée.
Je vais vous guider tout au long du processus d'exécution d'Apache Druid sur Pop!_OS Linux (bien qu'il puisse être exécuté sur n'importe quelle distribution Linux), puis vous montrer comment charger des exemples de données.
Ce dont vous aurez besoin
Les seules choses dont vous aurez besoin pour que cela fonctionne sont une instance de Linux en cours d'exécution avec un environnement de bureau et un utilisateur avec des privilèges sudo.
C'est ça. Faisons de la magie de la base de données.
Comment installer Java 8
Pour le moment, Apache Druid ne prend en charge que Java 8, nous devons donc nous assurer qu'il est installé et défini par défaut. Pour installer Java 8 sur une distribution de bureau basée sur Ubuntu, connectez-vous à la machine, ouvrez une fenêtre de terminal et lancez la commande :
sudo apt install openjdk-8-jdk -y
Une fois l'installation terminée, vous devez ensuite définir Java 8 par défaut. Faites cela avec la commande :
sudo update-alternatives --config java
Vous devriez voir une liste de toutes les versions de Java actuellement installées sur la machine. Assurez-vous de sélectionner le numéro qui correspond à Java 8.
Un mot sur les services Apache Druid
Ce que nous allons lancer est une micro-instance d'Apache Druid, qui nécessite 4 processeurs et 16 Go de RAM. Il existe 6 configurations de service différentes pour Apache Druid, qui sont :
- Nano-Quickstart :1 processeur, 4 Go de RAM
- Micro-Quickstart :4 processeurs, 16 Go de RAM
- Petit :8 processeurs, 64 Go de RAM
- Moyenne :16 processeurs, 128 Go de RAM
- Grand :32 processeurs, 256 Go de RAM
- Très grand :64 processeurs, 512 Go de RAM
En fonction de la taille de vos données et de vos besoins. Lorsque vous entrez dans une mine de données massive, il est recommandé de déployer Apache Druid en tant que cluster. Cependant, puisque nous venons tout juste de découvrir Apache Druid, la micro-instance conviendra parfaitement.
Couverture des développeurs à lire absolument
Comment télécharger et décompresser Apache Druid
Avec Java installé, il est temps de télécharger et de décompresser Apache Druid. De retour à la fenêtre du terminal, téléchargez la dernière version (assurez-vous de vérifier la page de téléchargement d'Apache Druid pour vérifier qu'il s'agit de la dernière version) avec la commande :
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Décompressez le fichier téléchargé avec :
tar xvfz apache-druid-0.22.1-bin.tar.gz
Passez dans le répertoire nouvellement créé avec :
cd apache-druid-0.22.1
Démarrez le service avec :
./bin/start-micro-quickstart
Le service Apache Druid devrait se lancer sans problème. Notez que vous ne récupérerez pas votre terminal pendant que le service fonctionne jusqu'à ce que vous l'annuliez avec CTRL + C.
Comment accéder à la console Apache Druid
Sur la même machine qui exécute Apache Druid, ouvrez un navigateur Web et pointez-le vers http://localhost:8888 . Malheureusement, Apache Druid est configuré de telle sorte que vous ne pouvez pas y accéder depuis une machine distante, c'est pourquoi nous l'installons sur une machine de bureau.
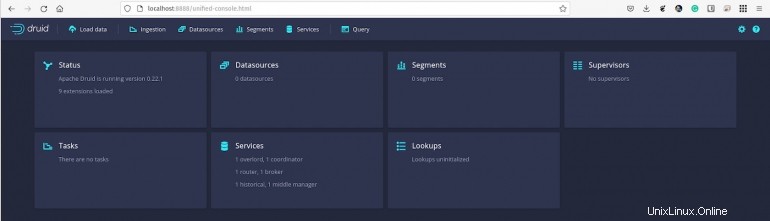
La console Apache Druid vous accueillera (Figure A ).
Figure A
Comment charger des données
Nous allons charger un échantillon prédéfini de données, trouvé dans le quickstart/tutorial/directory. L'exemple s'appelle wikiticker-2015-09-12-sampled.json.gz.
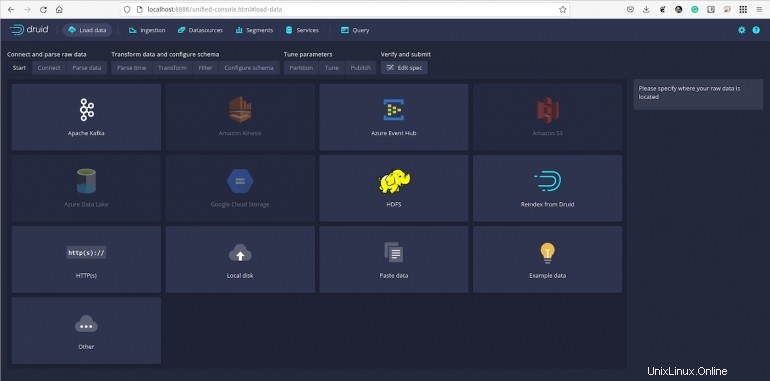
Figure B
Cliquez sur Connecter les données (sur le côté droit de la fenêtre) puis, dans la barre latérale résultante (Figure C ), tapez quickstart/tutorial comme répertoire de base et wikiticker-2015-09-12-sampled.json.gz dans la section Filtre de fichiers.
Figure C
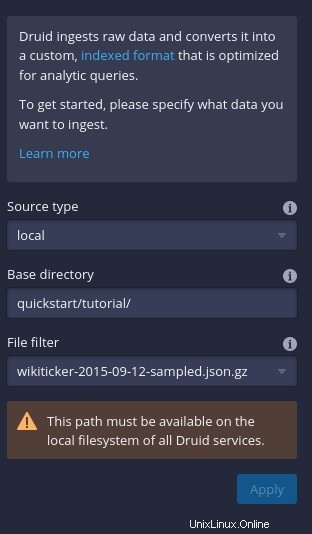
Cliquez sur Appliquer et vous devriez voir une assez grande quantité de données apparaître dans la fenêtre principale (Figure D ).
Schéma D
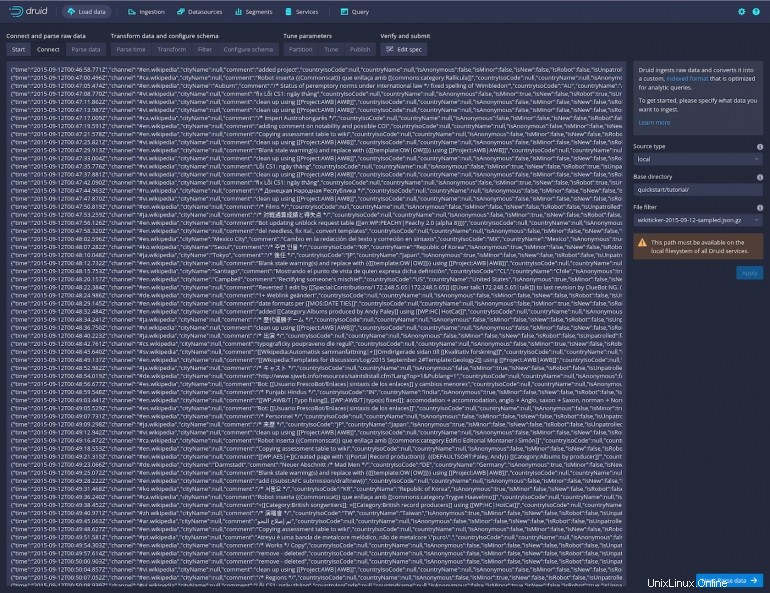
Cliquez sur Suivant :Analyser les données en bas à droite et vous serez présenté avec une liste des données dans un format plus lisible (Figure E ).
Figure E
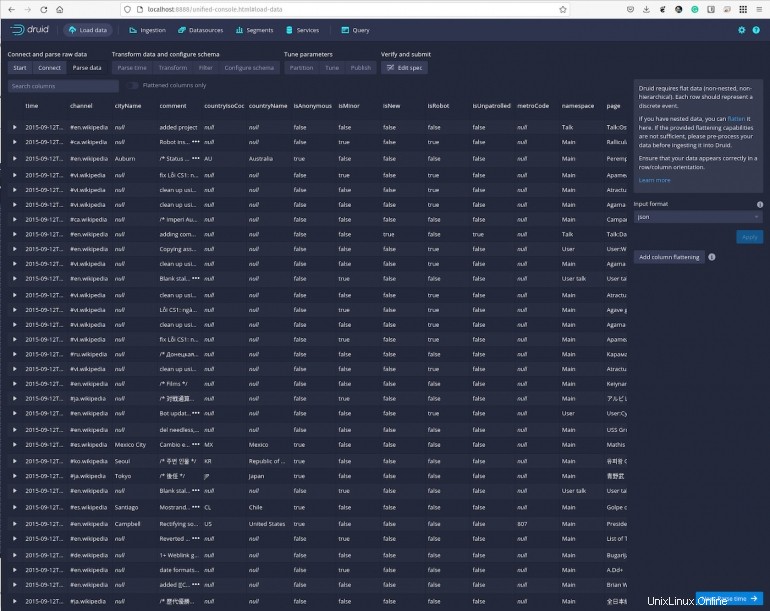
Cliquez sur Suivant :Parse Time et vous pouvez afficher les données par rapport à des horodatages particuliers (Figure F ).
Figure F
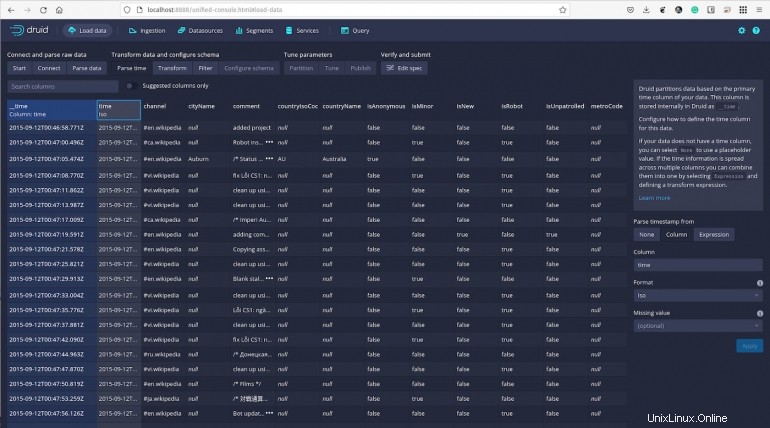
Cliquez sur Suivant :Transformer et vous pouvez ensuite effectuer des transformations par ligne des valeurs de colonne pour créer de nouvelles colonnes ou modifier celles qui existent déjà.
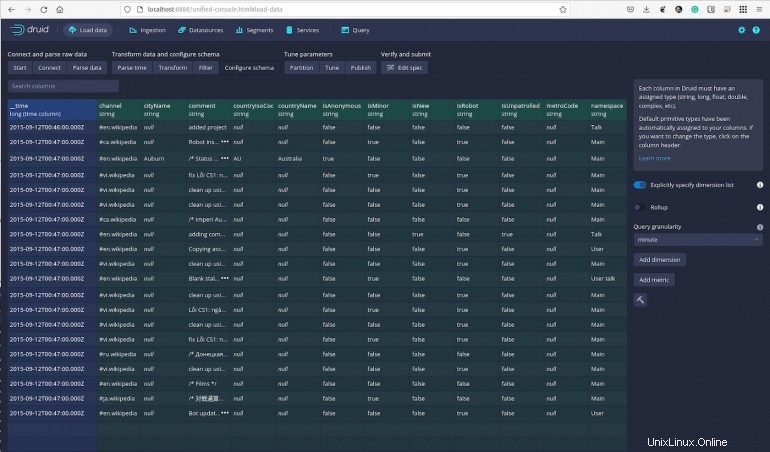
Continuez à cliquer sur les données et, à tout moment, vous pouvez exécuter des requêtes et filtrer les données selon vos besoins. Dans la section Configurer le schéma (Figure G ), vous pouvez même spécifier la granularité de vos requêtes et ajouter des dimensions et des statistiques.
Figure G
Et c'est à peu près les bases d'Apache Druid. Bien que nous n'ayons fait qu'effleurer la surface de ce que cette puissante plate-forme d'analyse de données peut faire, vous devriez pouvoir vous faire une idée assez précise de son fonctionnement en jouant avec les exemples de données.
Lorsque vous avez fini de travailler, assurez-vous de revenir à la fenêtre du terminal et d'arrêter le service Apache Druid avec CTRL + C.