Curl est un excellent outil pour télécharger des fichiers dans le terminal Linux.
La syntaxe habituelle pour télécharger un fichier portant le même nom que le fichier d'origine est assez simple :
curl -O URL_of_the_fileCela fonctionne la plupart du temps. Cependant, vous remarquerez que parfois, lorsque vous téléchargez un fichier depuis GitHub ou SourceForge, il ne récupère pas le bon fichier.
Par exemple, j'essayais de télécharger le script archinstall au format tar gz. Les fichiers se trouvent sur la page de publication.
Si j'ouvre ce lien de code source dans un navigateur, j'obtiens le code source au format .tar.gz.
Cependant, si j'utilise le terminal pour télécharger le même fichier à l'aide de la commande curl, j'obtiens un petit fichier qui n'est pas au bon format d'archive.
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Lorsque j'exécute la commande file pour connaître le type de fichier exact, cela me dit qu'il s'agit d'un document HTML.
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators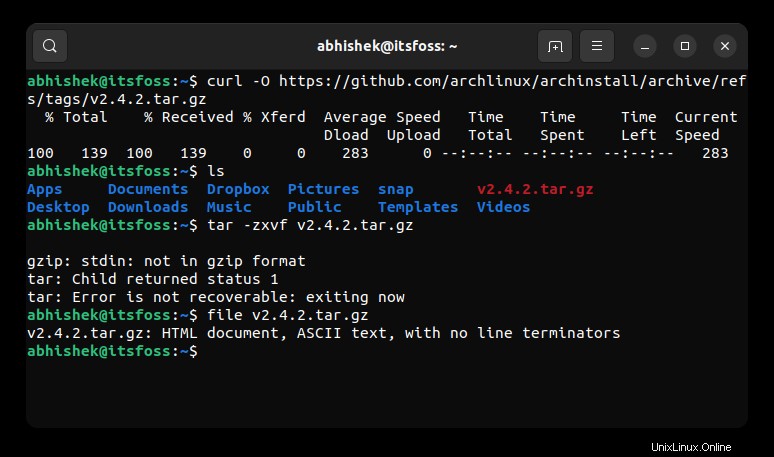
Document HTML au lieu de l'archive zip ou tarball ? Où est le problème ? Laissez-moi vous montrer la solution rapide.
Télécharger correctement le fichier d'archive avec curl
Le problème ici est que l'URL que vous avez redirige vers le fichier d'archive réel. Pour cela, vous devez utiliser des options supplémentaires.
curl -JLO URL_of_the_fileLes options peuvent être dans n'importe quel ordre. C'est juste plus facile de se souvenir de J LO (Jennifer Lopez).
Voici une explication rapide des options basées sur la page de manuel de la commande curl.
- J :cette option indique à l'option -O, --remote-name d'utiliser le nom de fichier Content-Disposition spécifié par le serveur au lieu d'extraire un nom de fichier de l'URL.
- L :si le serveur signale que la page demandée a été déplacée vers un autre emplacement (indiqué par un en-tête Emplacement :et un code de réponse 3XX), cette option obligera curl à refaire la demande au nouvel emplacement.
- O :Avec cette option, vous n'avez pas besoin de spécifier le nom du fichier de sortie pour le téléchargement.
Comme vous pouvez le voir dans la capture d'écran ci-dessous, j'ai pu télécharger le bon fichier cette fois avec l'option curl -JLO.
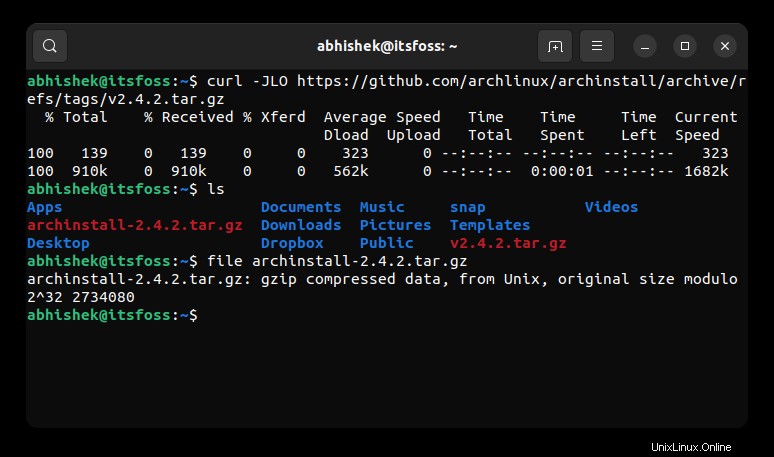
Astuce bonus :avez-vous besoin de vous connecter ?
Cela fonctionne pour les fichiers publics. Mais si vous essayez de télécharger des fichiers à partir de dépôts privés ou de GitLab, un message concernant la redirection vers la page de connexion peut s'afficher.
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
Dans de tels cas, veuillez fournir le jeton API avec l'option -H.
J'espère que cette petite astuce rapide vous aidera à télécharger correctement les fichiers d'archive avec Curl. Faites-moi savoir si vous rencontrez toujours des problèmes avec les téléchargements curl.