Lorsque vous devez comparer deux fichiers contenant du texte similaire sous Linux, l'utilisation de la commande diff peut vous faciliter la tâche. La commande compare deux fichiers pour suggérer des modifications qui rendraient les fichiers identiques. Idéal pour trouver cette accolade supplémentaire qui a cassé votre code récemment mis à jour.
L'utilisation de la commande diff est très simple. Voici la syntaxe :
diff [options] file1 file2Mais comprendre sa production est une autre chose. Ne vous inquiétez pas, je vais vous expliquer le résultat afin que vous puissiez comparer deux fichiers et comprendre la différence entre eux.
Comprendre la commande diff sous Linux
Vous avez besoin de quelques fichiers pour commencer. J'ai généré une liste à l'aide d'un générateur de mots aléatoires.
J'ai ajouté la liste à deux fichiers différents, puis j'ai modifié la liste en :
- Modification de l'ordre de la liste
- Ajouter des lettres
- Changer de casse
J'ai enregistré ces fichiers similaires en tant que 1.txt et 2.txt. Voici à quoi ils ressemblent avant de faire quoi que ce soit.
Je vous suggère de suivre le didacticiel pendant la lecture, alors créez de nouveaux fichiers et ajoutez-y le contenu suivant.
Contenu de 1.txt :
araignée
médaillon
acoustique
expansion
enregistrer
Contenu de 2.txt :
araignée
MÉDAILLON
acoustique
enregistrements
extension
Exemple 1 :Diff sans options
Voyons ce qui se passe lorsque vous exécutez le diff commande sans aucune option.
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordConfus? Tu n'es pas seul. La sortie n'est pas exactement humaine. Afin de comprendre ce qui se passe, vous devez en savoir plus sur le fonctionnement de diff.
Il peut être utile de savoir que lorsque l'analyse est terminée, fichier2 [dans la syntaxe] est traité comme le document de référence avec lequel vous essayez de faire correspondre. Donc, vous pouvez dire que diff fonctionne de cette façon :
diff <file_to_edit> <file_as_reference>Cela signifie également que vous obtiendrez une sortie différente en fonction de l'ordre dans lequel vous placez les noms de fichiers.
L'ordre compte
Un exemple de la façon dont la sortie diffère en fonction de l'ordre des fichiers :
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< record
christopher:~$ diff 2.txt 1.txt
2c2
< LOCKET
---
> locket
4d3
< records
5a5
> recordSymboles importants dans la sortie de la commande diff
En utilisant le tableau ci-dessous comme référence, vous pouvez mieux comprendre ce qui se passe dans votre terminal.
| Symbole | Signification |
|---|---|
| A | Ajouter |
| C | Modifier |
| D | Supprimer |
| # | Numéros de ligne |
| – – – | Sépare les fichiers dans la sortie |
| < | Fichier 1 |
| > | Fichier 2 |
Examinons à nouveau la sortie de la commande diff :
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordExplication de la sortie de la commande diff
Voyons la première différence dans la sortie :
| Ligne de sortie | Explication |
|---|---|
| 2c2 | La ligne 2 du fichier 1, CHANGER avec la ligne 2 du fichier 2. |
| Changez "locket" en "LOCKET" pour correspondre au fichier 2.txt |
Examinons la partie suivante de la sortie :
| Ligne de sortie | Explication |
|---|---|
| 3a4 | Après la ligne 3 du fichier 1, ajoutez la ligne 4 du fichier 2. |
| > enregistrements | C'est pour ajouter des "enregistrements" pour créer la 4ème ligne dans le fichier 1. Ainsi, le fichier 1.txt correspondra au fichier 2.txt |
De même :
| Ligne de sortie | Explication |
|---|---|
5d5 | Supprimez le texte "record" de la 5ème ligne du fichier 1. Ainsi, le fichier 1.txt correspondra au fichier 2.txt | |
Il n'y a pas de fonction de vérification orthographique ou de dictionnaire intégrée dans la commande. Il ne reconnaît pas "record" et "records" comme étant liés. Son seul but est de faire correspondre parfaitement les deux fichiers.
En regardant la sortie, c'est encore assez difficile à traduire. Il est peu probable que vous gagniez beaucoup de temps.
Heureusement, il existe des options qui peuvent être ajoutées pour rendre les choses plus lisibles par l'homme. Regardons quelques exemples différents utilisant la même liste.
Exemple 2 :Diff dans le contexte "Copié" avec -c
L'option de contexte donne une représentation plus visuelle par rapport aux informations plus programmatiques affichées par défaut. Continuons avec notre exemple de texte.
Plus de symboles importants dans la sortie de la commande diff
| Symbole | Signification |
|---|---|
| + | Ajouter |
| ! | Modifier |
| – | Supprimer |
| *** | Fichier 1 |
| – – – | Fichier 2 |
christopher:~$ diff -c 1.txt 2.txt
*** 1.txt 2019-10-20 12:05:09.244673327 -0400
--- 2.txt 2019-10-20 12:11More:31.382547316 -0400
***************
*** 1,5 ****
cobweb
! locket
acoustics
expansion
- record
--- 1,5 ----
cobweb
! LOCKET
acoustics
+ records
expansionIl est beaucoup plus facile de comprendre lorsque vous voyez les informations de cette manière. Au lieu de la sortie alphanumérique, le nouvel ensemble de symboles vous aide à identifier rapidement les différences entre les deux fichiers.
La sortie affiche d'abord le premier fichier, c'est-à-dire 1.txt et sa ligne de 1 à 5. Il indique qu'il y a un léger changement dans (une partie de) la ligne 2 du fichier 1.txt et (une partie de) la ligne 2 du fichier 2 .txt.
Cela indique également que la ligne numéro 5 du fichier 1 a été supprimée (-) dans le second fichier.
— 1,5 —- indique le début du deuxième fichier et indique que la ligne 2 est légèrement modifiée par rapport à la ligne 2 du fichier 1. Cela indique également que la ligne 4 a été ajoutée (+) dans le deuxième fichier et qu'il n'y a pas de correspondance ligne dans le fichier 1.
Exemple 3 :Diff dans le contexte "Unified" avec -u
Cette option fournit une sortie similaire au format de contexte copié. Au lieu d'afficher les deux fichiers séparément, il les fusionne.
christopher:~$ diff 1.txt 2.txt -u
--- 1.txt 2019-10-20 12:05:09.244673327 -0400
+++ 2.txt 2019-10-20 12:11:31.382547316 -0400
@@ -1,5 +1,5 @@
cobweb
-locket
+LOCKET
acoustics
+records
expansion
-record
Comme vous pouvez le voir, il utilise les mêmes symboles qu'auparavant, mais au lieu du symbole de modification, il suggère des modifications à apporter à l'aide de + faciles à lire ou - symboles. Ici, il est recommandé de supprimer la ligne 2 de 1.txt et remplacez-le par la ligne 2 de 2.txt .
À l'avenir, il vous suggère également d'ajouter des enregistrements après la ligne contenant l'acoustique et supprimer la ligne enregistrement après la ligne contenant l'expansion.
Toutes ces modifications sont suggérées pour le premier fichier de la commande diff. Il s'agit d'un autre scénario dans lequel il est utile de se rappeler que le programme diff utilise le deuxième fichier répertorié comme "l'original" ou la base des corrections.
Pour comparer une liste comme celle-ci, je trouve personnellement cette méthode la plus facile à utiliser. Il vous donne une visualisation claire du texte qui doit être modifié afin de rendre les fichiers identiques.
Exemple 4 : Comparer mais ignorer les cas avec -i
Les recherches sensibles à la casse sont la valeur par défaut pour diff, mais vous pouvez désactiver cette option. Regardons ce qui se passe lorsque vous faites cela.
christopher:~$ diff 1.txt 2.txt -i
3a4
> records
5d5
< recordComme vous pouvez le voir, "médaillon" et "MÉDAILLON" ne sont plus répertoriés comme modifications suggérées.
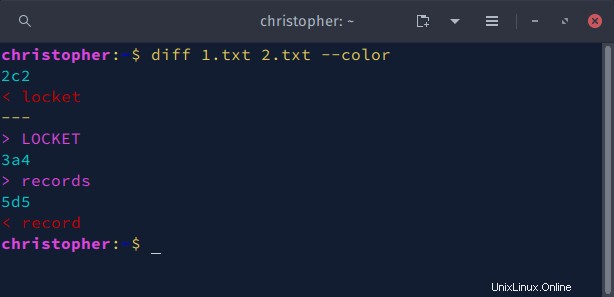
Exemple 5 :Diff avec –color
Vous pouvez utiliser --color pour mettre en surbrillance les modifications dans la sortie de la commande diff. Lorsque la commande est exécutée, des sections de sortie seront imprimées dans différentes couleurs à partir de la palette du terminal.
Exemple 6 :Analyse rapide des fichiers avec les options de commande diff -s et -q
Il existe plusieurs façons simples de vérifier si les fichiers sont identiques ou non. Si vous utilisez -s il vous dira que les fichiers sont identiques ou il exécutera diff normalement.
Utilisation de -q vous dira seulement que les fichiers "diffèrent". Si ce n'est pas le cas, vous n'obtiendrez aucune sortie.
christopher:~$ diff 1.txt 1.txt -s
Files 1.txt and 1.txt are identical
christopher:~$ diff 1.txt 2.txt -q
Files 1.txt and 2.txt differAstuce bonus :utilisation de la commande diff sous Linux avec des fichiers texte volumineux
Vous ne comparez peut-être pas toujours des informations aussi simples. Vous pouvez avoir de gros fichiers texte à analyser et trouver des différences. Je vais détailler quelques méthodes pour gérer ce type de problème.
Pour cet exemple, j'ai créé deux fichiers avec de gros morceaux de texte (lorem ipsum). Chaque ligne comporte des centaines de colonnes. Cela a évidemment rendu la comparaison des lignes difficile.
Lorsque diff est exécuté sur un fichier comme celui-ci, la sortie génère d'énormes morceaux de texte et les symboles sont difficiles à voir même avec des outils comme la sortie contextuelle.
Pour économiser de l'espace, j'ai pris une capture d'écran de la sortie pour que vous puissiez la regarder.
Pas très utile, n'est-ce pas ?
Vous pouvez utiliser certains des mêmes concepts pour analyser ces types de fichiers. Ils ne fonctionneront pas correctement si le fichier n'est pas correctement formaté. Certains grands blocs de texte n'ont pas de saut de ligne. Vous avez probablement rencontré un fichier comme celui-ci où vous deviez activer "Word Wrap" afin d'afficher tout le texte dans l'espace alloué sans utiliser de barre de défilement. La raison pour laquelle cela se produit est que certains formats de texte ne créent pas de sauts de ligne automatiquement. C'est ainsi que vous vous retrouvez avec les gros morceaux de texte sur seulement 2-3 lignes. Il existe une solution assez simple pour cela.
Utiliser le pli pour envelopper le texte dans les lignes
Ceci est le manuel de Linux, donc, naturellement, nous avons une solution pour vous et nous pouvons y intégrer un mini tutoriel. Il y a un excellent article sur fold (Unix) et fmt (GNU) ici. Je vais donner un exemple rapide qui devrait être assez explicite pour nous faire avancer.
La commande fold est utilisée pour couper les lignes en utilisant le nombre de colonnes. Il peut être personnalisé pour vous donner des options sur la façon dont ces nouveaux sauts de ligne sont mis en œuvre.
Dans l'exemple ici, vous allez séparer le fichier en une largeur standardisée et utiliser le -s option. Cela indique au programme de couper UNIQUEMENT là où il y a des espaces, pas au milieu du texte.
Utiliser le pli pour insérer rapidement des sauts de ligne
fold -w 80 -s lorem.txt > lorem.txt
fold -w 80 -s lorem2.txt > lorem2.txtAvec les deux fichiers divisés en 31 lignes au lieu de 3, vous pouvez les comparer beaucoup plus efficacement. Voici un exemple de votre sortie avec le filtre de contexte unifié.
christopher:~$ diff lorem.txt 2lorem.txt -u
--- lorem.txt 2019-10-27 09:39:07.298691695 -0400
+++ 2lorem.txt 2019-10-27 09:39:08.370704501 -0400
@@ -1,10 +1,10 @@
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus in tincidunt
sapien. Maecenas sagittis ex risus, in vehicula turpis imperdiet sed. Phasellus
placerat posuere maximus. In hac habitasse platea dictumst. Ut vel tristique
-eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
+eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
Suspendisse at mauris vitae sapien euismod tincidunt. Sed placerat finibus
blandit. Duis ornare ante at ipsum accumsan, nec bibendum nibh tincidunt.
-Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
+Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
vitae enim. Nam condimentum, purus nec semper efficitur, nisi quam vehicula
sem, eget finibus diam ipsum suscipit velit.
@@ -21,7 +21,7 @@
Maecenas lacinia cursus tristique. Nulla a hendrerit orci. Donec lobortis nisi
sed ante euismod lobortis. Nullam sit amet est nec nunc porttitor sollicitudin
-a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
+a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
interdum mi metus vel tellus. Fusce nec dui a risus posuere mattis at eu orci.
Proin purus sem, finibus eget viverra vel, porta pulvinar ex. In hac habitasse
platea dictumst. Nunc faucibus leo nec tristique porta. Phasellus luctus ipsumUtiliser diff avec -sortie minimale
Vous pouvez rendre cela un peu plus facile à lire avec le --minimal étiqueter. Cela rend les fichiers texte plus volumineux un peu plus faciles à lire. Examinons le résultat.
christopher:~$ diff lorem.txt 2lorem.txt --minimal
4c4
< eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
---
> eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
7c7
< Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
---
> Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
24c24
< a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
---
> a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at Vous pouvez combiner n'importe lequel de ces conseils ou utiliser certaines des autres options répertoriées dans les pages de manuel diff. Il s'agit d'un utilitaire logiciel puissant et facile à utiliser.
J'espère que vous avez trouvé cet article utile. Si vous avez une astuce, n'oubliez pas de nous laisser un commentaire et de nous en parler.