Pour un administrateur système, il est très courant d'effectuer une redirection d'entrée ou de sortie lors de son travail quotidien.
La redirection d'entrée et de sortie est un outil très puissant, vous permettant de connecter plusieurs commandes ensemble ainsi que de synthétiser la sortie de plusieurs commandes.
Redirection d'entrée/sortie est un concept de base des systèmes basés sur Unix - et il peut être utilisé comme un moyen d'augmenter la productivité des programmeurs énormément.
Cependant, la redirection d'entrée et de sortie est un vaste sujet et il y a quelques notions de base que vous devez comprendre si vous voulez être productif.
Avec ce tutoriel, vous allez tout comprendre qu'il y a à savoir sur la redirection d'entrée et de sortie sur les systèmes Linux.
Nous allons réfléchir sur la conception du noyau Linux sur les fichiers ainsi que sur le fonctionnement des processus afin d'avoir une compréhension approfondie et complète de ce qu'est la redirection d'entrée et de sortie.
Quelques exemples seront fournis en cours de route pour s'assurer que les connaissances théoriques sont liées aux exercices pratiques.
Prêt ?
Ce que vous allez apprendre
Si vous suivez ce tutoriel jusqu'à la fin, vous allez apprendre les concepts suivants.
- Quels descripteurs de fichiers ? sont et comment ils sont liés aux entrées et sorties standard;
- Comment vérifier les entrées et sorties standard pour un processus donné sous Linux ;
- Comment rediriger l'entrée et la sortie standard sous Linux ;
- Comment utiliser les pipelines chaîner les entrées et les sorties pour les commandes longues ;
C'est un programme assez long, sans plus tarder, regardons ce que sont les descripteurs de fichiers et comment les fichiers sont conceptualisés par le noyau Linux.
1 - Que sont les processus Linux ?
Avant de comprendre les entrées et les sorties sur un système Linux, il est très important d'avoir quelques bases sur ce que sont les processus Linux et comment ils interagissent avec votre matériel.
Si vous n'êtes intéressé que par les lignes de commande de redirection d'entrée et de sortie, vous pouvez passer aux sections suivantes. Cette section est destinée aux administrateurs système souhaitant approfondir le sujet.
a – Comment les processus Linux sont-ils créés ?
Vous l'avez probablement déjà entendu auparavant, car c'est un adage assez populaire, mais sous Linux, tout est un fichier .
Cela signifie que les processus, les périphériques, les claviers et les disques durs sont représentés comme des fichiers vivant sur le système de fichiers.
Le noyau Linux peut différencier ces fichiers en leur attribuant un type de fichier (un fichier, un répertoire, un soft link ou un socket par exemple) mais ils sont stockés dans la même structure de données par le Kernel.
Comme vous le savez probablement déjà, les processus Linux sont créés comme des forks de processus existants qui peuvent être le processus init ou le processus systemd sur les distributions plus récentes.
Lors de la création d'un nouveau processus, le noyau Linux créera un processus parent et dupliquera une structure qui est la suivante.
b – Comment les fichiers sont-ils stockés sous Linux ?
Je crois qu'un diagramme vaut cent mots, alors voici comment les fichiers sont conceptuellement stockés sur un système Linux.

Comme vous pouvez le voir, pour chaque processus créé, un nouveau task_struct est créé sur votre hôte Linux.
Cette structure contient deux références, une pour les métadonnées du système de fichiers (appelée fs ) où vous pouvez trouver des informations telles que le masque du système de fichiers par exemple.
L'autre est une structure pour les fichiers contenant ce que nous appelons des descripteurs de fichiers .
Il contient également des métadonnées sur les fichiers utilisés par le processus mais nous nous concentrerons sur les descripteurs de fichiers pour ce chapitre.
En informatique, les descripteurs de fichiers sont des références à d'autres fichiers actuellement utilisés par le noyau lui-même.
Mais que représentent ces fichiers ?
c – Comment les descripteurs de fichiers sont-ils utilisés sous Linux ?
Comme vous le savez probablement déjà, le noyau agit comme un interface entre vos périphériques matériels (un écran, une souris, un cédérom ou un clavier).
Cela signifie que votre noyau est capable de comprendre que vous souhaitez transférer certains fichiers entre disques, ou que vous souhaitez créer une nouvelle vidéo sur votre lecteur secondaire par exemple.
En conséquence, le noyau Linux déplace en permanence les données des périphériques d'entrée (un clavier par exemple) vers les périphériques de sortie (un disque dur par exemple).
En utilisant cette abstraction, les processus sont essentiellement un moyen de manipuler les entrées (tel que lu opérations) pour rendre diverses sorties (comme écriture opérations)
Mais comment les processus savent-ils où les données doivent être envoyées ?
Les processus savent où les données doivent être envoyées à l'aide de descripteurs de fichiers.
Sous Linux, le descripteur de fichier 0 (ou fd[0]) est affecté à l'entrée standard.
De même le descripteur de fichier 1 (ou fd[1]) est affecté à la sortie standard , et le descripteur de fichier 2 (ou fd[2]) est affecté à l'erreur type.
C'est une constante sur un système Linux, pour chaque processus, les trois premiers descripteurs de fichiers sont réservés aux entrées, sorties et erreurs standard.
Ces descripteurs de fichiers sont mappés sur les périphériques de votre système Linux.
Périphériques enregistrés lors de l'instanciation du noyau, ils peuvent être vus dans /dev répertoire de votre hébergeur.
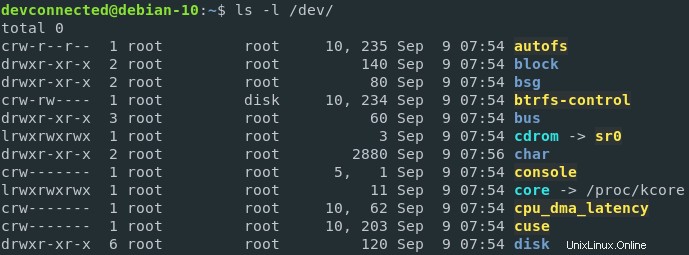
Si vous jetez un coup d'œil aux descripteurs de fichiers d'un processus donné, disons un processus bash par exemple, vous pouvez voir que les descripteurs de fichiers sont essentiellement des liens symboliques vers de vrais périphériques matériels sur votre hôte.
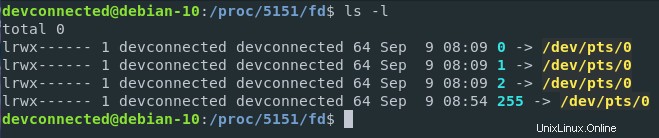
Comme vous pouvez le voir, lors de l'isolation des descripteurs de fichiers de mon processus bash (qui a le PID 5151 sur mon hôte), je peux voir les périphériques qui interagissent avec mon processus (ou les fichiers ouverts par le noyau pour mon processus).
Dans ce cas, /dev/pts/0 représente un terminal qui est un périphérique virtuel (ou tty) sur mon système de fichiers virtuel. En termes plus simples, cela signifie que mon instance bash (exécutée dans une interface de terminal Gnome) attend les entrées de mon clavier, les imprime à l'écran et les exécute lorsqu'on lui demande.
Maintenant que vous avez une meilleure compréhension des descripteurs de fichiers et de la façon dont ils sont utilisés par les processus, nous sommes prêts à décrire comment effectuer la redirection d'entrée et de sortie sous Linux .
2 - Qu'est-ce que la redirection de sortie sous Linux ?
La redirection d'entrée et de sortie est une technique utilisée pour rediriger/modifier entrées et sorties standard, modifiant essentiellement l'endroit où les données sont lues ou l'endroit où les données sont écrites.
Par exemple, si j'exécute une commande sur mon shell Linux, la sortie peut être imprimée directement sur mon terminal (une commande cat par exemple).
Cependant, avec la redirection de sortie, je pourrais choisir de stocker la sortie de ma commande cat dans un fichier pour un stockage à long terme.
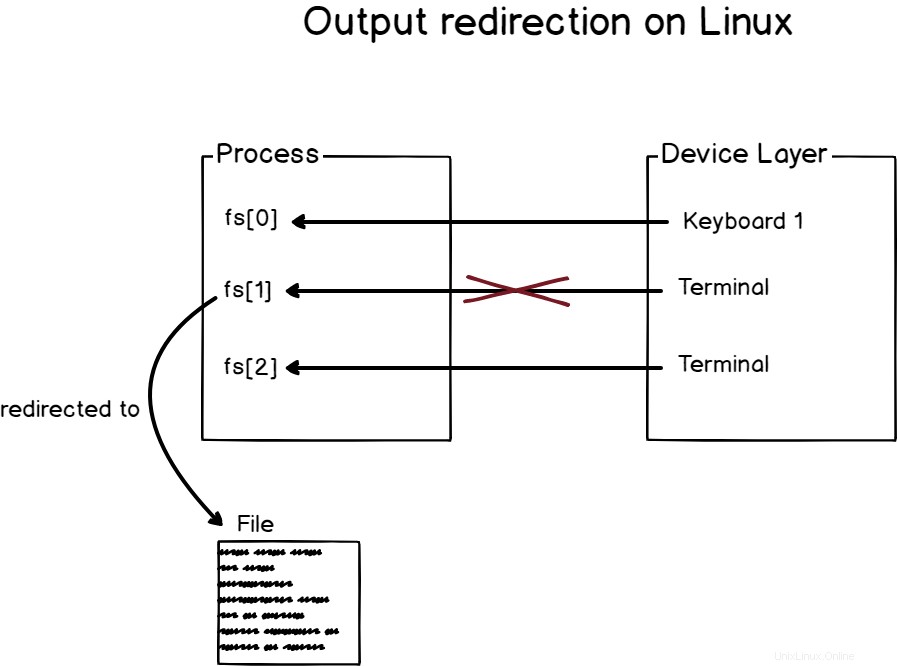
a – Comment fonctionne la redirection de sortie ?
La redirection de sortie consiste à rediriger la sortie d'un processus vers un emplacement choisi, tel que des fichiers, des bases de données, des terminaux ou tout périphérique (ou périphérique virtuel) sur lequel il est possible d'écrire.
À titre d'exemple, examinons la commande echo.
Par défaut, la fonction echo prendra un paramètre de chaîne et l'imprimera sur le périphérique de sortie par défaut.
Par conséquent, si vous exécutez la fonction echo dans un terminal, la sortie sera imprimée dans le terminal lui-même.

Supposons maintenant que je souhaite que la chaîne soit imprimée dans un fichier à la place, pour un stockage à long terme.
Pour rediriger la sortie standard sous Linux, vous devez utiliser l'opérateur ">".
Par exemple, pour rediriger la sortie standard de la fonction echo vers un fichier, vous devez exécuter
$ echo devconnected > fileSi le fichier n'existe pas, il sera créé.
Ensuite, vous pouvez jeter un œil au contenu du fichier et voir que la chaîne "devconnected" y a été correctement imprimée.

Alternativement, il est possible de rediriger la sortie en utilisant le "1> ” syntaxe.
$ echo test 1> file
b - Redirection de sortie vers des fichiers de manière non destructive
Lors de la redirection de la sortie standard vers un fichier, vous avez probablement remarqué que cela efface le contenu existant du fichier.
Parfois, cela peut être assez problématique car vous voudriez conserver le contenu existant du fichier et simplement ajouter quelques modifications à la fin du fichier.
Pour ajouter du contenu à un fichier à l'aide de la redirection de sortie, utilisez l'opérateur ">>" plutôt que l'opérateur ">".
Compte tenu de l'exemple que nous venons d'utiliser, ajoutons une deuxième ligne à notre fichier existant.
$ echo a second line >> file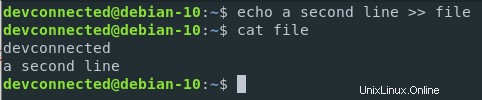
Génial !
Comme vous pouvez le voir, le contenu a été ajouté au fichier, plutôt que de l'écraser complètement.
c – Problèmes de redirection de sortie
Lorsqu'il s'agit de redirection de sortie, vous pourriez être tenté d'exécuter une commande vers un fichier uniquement pour rediriger la sortie vers le même fichier.
Redirection vers le même fichier
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > fileQu'attendez-vous de voir dans le fichier de test ?
Le résultat est que le fichier est complètement vide.

Pourquoi ?
Par défaut, lors de l'analyse de votre commande, le noyau n'exécutera pas les commandes de manière séquentielle.
Cela signifie qu'il n'attendra pas la fin de la commande sed pour ouvrir votre nouveau fichier et y écrire le contenu.
Au lieu de cela, le noyau va ouvrir votre fichier, effacer tout le contenu qu'il contient et attendre que le résultat de votre opération sed soit traité.
Comme votre opération sed voit un fichier vide (car tout le contenu a été effacé par l'opération de redirection de sortie), le contenu est vide.
Par conséquent, rien n'est ajouté au fichier et le contenu est complètement vide.
Afin de rediriger la sortie vers le même fichier, vous pouvez utiliser des tubes ou des commandes plus avancées telles que
command … input_file > temp_file && mv temp_file input_fileProtéger un fichier contre l'écrasement
Sous Linux, il est possible de protéger les fichiers contre l'écrasement par l'opérateur ">".
Vous pouvez protéger vos fichiers en définissant le paramètre "noclobber" sur l'environnement shell actuel.
$ set -o noclobberIl est également possible de restreindre la redirection de sortie en courant
$ set -CRemarque :pour réactiver la redirection de sortie, exécutez simplement set +C
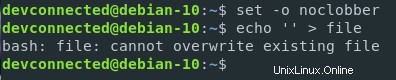
Comme vous pouvez le voir, le fichier ne peut pas être remplacé lors de la définition de ce paramètre.
Si je veux vraiment forcer le remplacement, je peux utiliser le ">| ” opérateur pour le forcer.

3 - Qu'est-ce que la redirection d'entrée sous Linux ?
a – Comment fonctionne la redirection d'entrée ?
La redirection d'entrée est l'acte de rediriger l'entrée d'un processus vers un périphérique donné (ou périphérique virtuel) afin qu'il commence à lire à partir de ce périphérique et non à partir de celui par défaut attribué par le noyau.
Par exemple, lorsque vous ouvrez un terminal, vous interagissez avec lui avec votre clavier.
Cependant, dans certains cas, vous souhaiterez peut-être travailler avec le contenu d'un fichier, car vous souhaitez envoyer par programmation le contenu du fichier à votre commande.
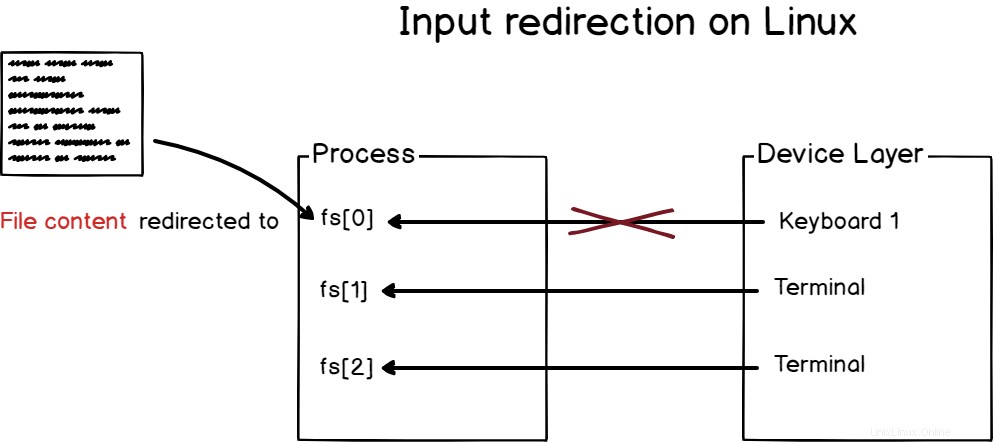
Pour rediriger l'entrée standard sous Linux, vous devez utiliser l'opérateur "<".
Par exemple, supposons que vous souhaitiez utiliser le contenu d'un fichier et exécuter une commande spéciale dessus.
Dans ce cas, je vais utiliser un fichier contenant des domaines, et la commande sera une simple commande de tri.
De cette manière, les domaines seront triés par ordre alphabétique.
Avec la redirection d'entrée, je peux exécuter la commande suivante
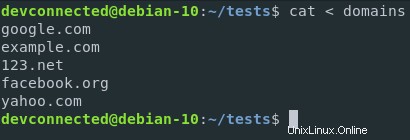
Si je veux trier ces domaines, je peux rediriger le contenu du fichier des domaines vers l'entrée standard de la fonction de tri.
$ sort < domains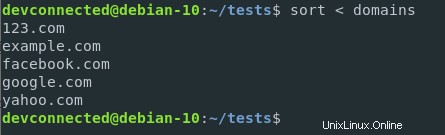
Avec cette syntaxe, le contenu du fichier des domaines est redirigé vers l'entrée de la fonction de tri. C'est assez différent de la syntaxe suivante
$ sort domainsMême si la sortie peut être la même, dans ce cas, la fonction de tri prend un fichier en paramètre.
Dans l'exemple de redirection d'entrée, la fonction de tri est appelée sans paramètre.
Par conséquent, lorsqu'aucun paramètre de fichier n'est fourni à la fonction, la fonction le lit à partir de l'entrée standard par défaut.
Dans ce cas, il lit le contenu du fichier fourni.
b - Redirection de l'entrée standard avec un fichier contenant plusieurs lignes
Si votre fichier contient plusieurs lignes, vous pouvez toujours rediriger l'entrée standard de votre commande pour chaque ligne de votre fichier.
Supposons, par exemple, que vous souhaitiez avoir une requête ping pour chaque entrée du fichier de domaines.
Par défaut, la commande ping s'attend à ce qu'une seule adresse IP ou URL fasse l'objet d'un ping.
Vous pouvez cependant rediriger le contenu de votre fichier de domaines vers une fonction personnalisée qui exécutera une fonction ping pour chaque entrée.
$ ( while read ip; do ping -c 2 $ip; done ) < ips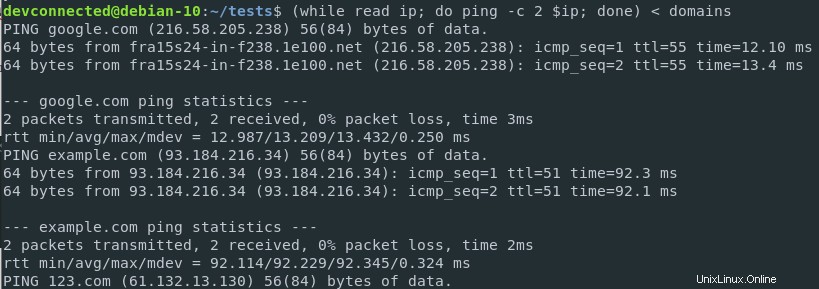
c - Combiner la redirection d'entrée avec la redirection de sortie
Maintenant que vous savez que l'entrée standard peut être redirigée vers une commande, il est utile de mentionner que la redirection d'entrée et de sortie peut être effectuée dans la même commande.
Maintenant que vous exécutez des commandes ping, vous obtenez les statistiques ping pour chaque site Web de la liste des domaines.
Les résultats sont imprimés sur la sortie standard, qui est dans ce cas le terminal.
Et si vous vouliez enregistrer les résultats dans un fichier ?
Ceci peut être réalisé en combinant les redirections d'entrée et de sortie sur la même commande .
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt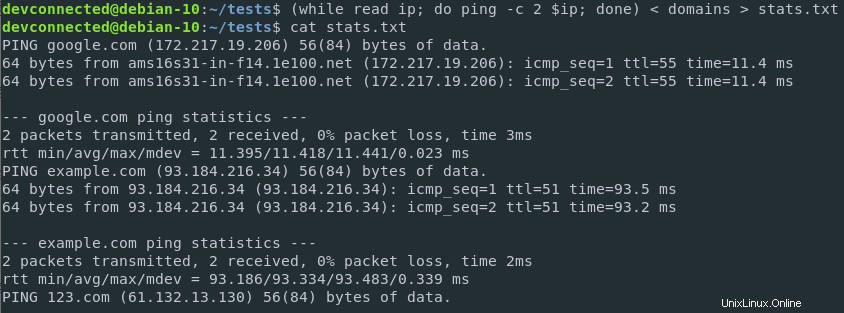
Génial!
Les résultats ont été correctement enregistrés dans un fichier et peuvent être analysés ultérieurement par d'autres équipes de votre entreprise.
d – Supprimer complètement la sortie standard
Dans certains cas, il peut être utile de supprimer complètement la sortie standard.
C'est peut-être parce que vous n'êtes pas intéressé par la sortie standard d'un processus ou parce que ce processus imprime trop de lignes sur la sortie standard.
Pour supprimer complètement la sortie standard sous Linux, redirigez la sortie standard vers /dev/null.
La redirection vers /dev/null entraîne la suppression et l'effacement complets des données.
$ cat file > /dev/nullRemarque :la redirection vers /dev/null n'efface pas le contenu du fichier mais supprime uniquement le contenu de la sortie standard.
4 – Qu'est-ce que la redirection d'erreur standard sous Linux ?
Enfin, après la redirection des entrées et des sorties, voyons comment l'erreur standard peut être redirigée.
a – Comment fonctionne la redirection d'erreur standard ?
De manière très similaire à ce que nous avons vu précédemment, la redirection des erreurs redirige les erreurs renvoyées par les processus vers un périphérique défini sur votre hôte.
Par exemple, si j'exécute une commande avec de mauvais paramètres, ce que je vois sur mon écran est un message d'erreur et il a été traité via le descripteur de fichier responsable des messages d'erreur (fd[2]).
Notez qu'il n'y a pas de moyens triviaux de différencier un message d'erreur d'un message de sortie standard dans le terminal, vous devrez vous fier au programmeur qui envoie les messages d'erreur au bon descripteur de fichier.
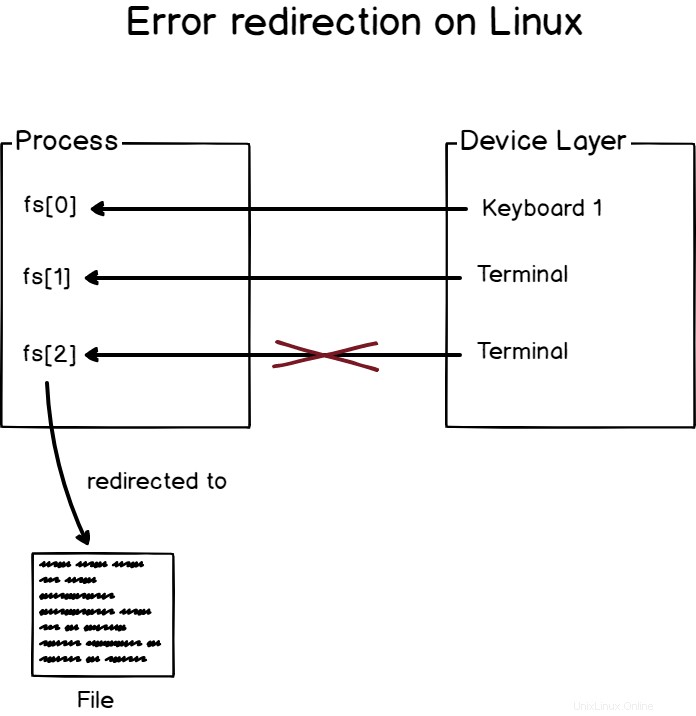
Pour rediriger la sortie d'erreur sous Linux, utilisez le "2> ” opérateur
$ command 2> filePrenons l'exemple de la commande ping afin de générer un message d'erreur sur le terminal.

Voyons maintenant une version où la sortie d'erreur est redirigée vers un fichier d'erreur.

Comme vous pouvez le voir, j'ai utilisé l'opérateur "2>" pour rediriger les erreurs vers le fichier "error-file".
Si je devais rediriger uniquement la sortie standard vers le fichier, rien ne serait imprimé dessus.

Comme vous pouvez le voir, le message d'erreur a été imprimé sur mon terminal et rien n'a été ajouté à ma sortie "fichier normal".
b - Combinaison de l'erreur standard avec la sortie standard
Dans certains cas, vous souhaiterez peut-être combiner les messages d'erreur avec la sortie standard et la rediriger vers un fichier.
Cela peut être particulièrement pratique car certains programmes renvoient non seulement des messages standard ou des messages d'erreur, mais un mélange des deux.
Prenons l'exemple de trouver commande.
Si j'exécute une commande find sur le répertoire racine sans droits sudo, il se peut que je ne sois pas autorisé à accéder à certains répertoires, comme des processus que je ne possède pas par exemple.
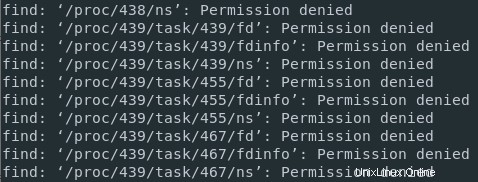
En conséquence, il y aura un mélange de messages standard (les fichiers appartenant à mon utilisateur) et les messages d'erreur (lorsque j'essaie d'accéder à un répertoire qui ne m'appartient pas).
Dans ce cas, je veux que les deux sorties soient stockées dans un fichier.
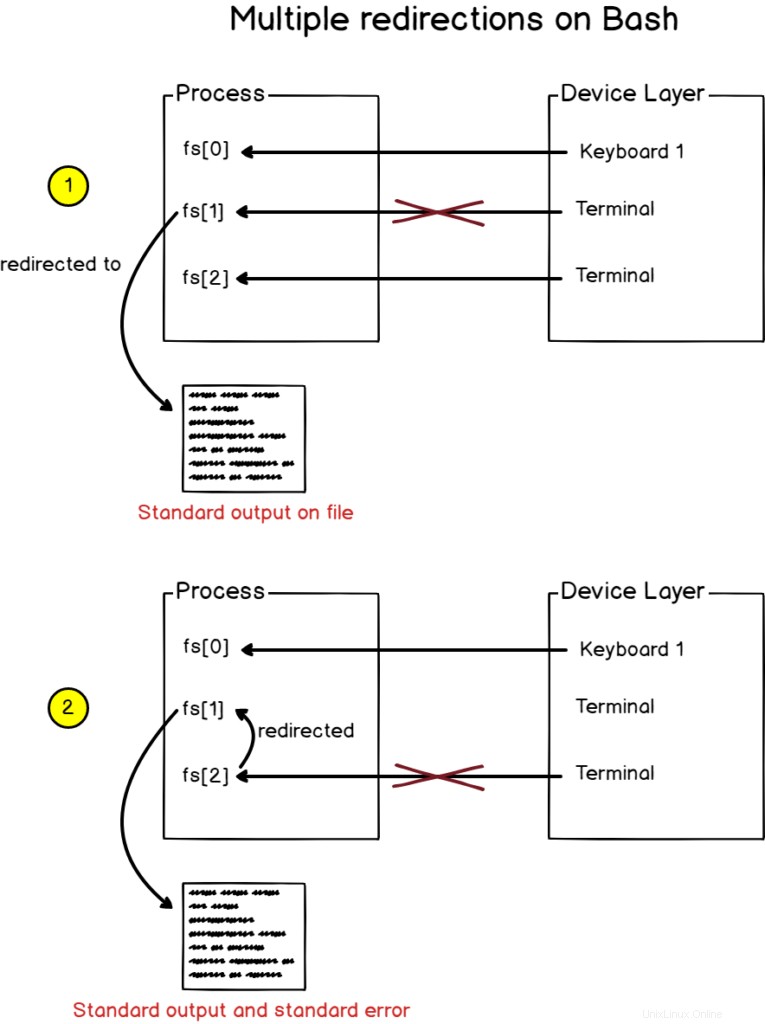
Pour rediriger la sortie standard ainsi que la sortie d'erreur vers un fichier, utilisez la syntaxe "2<&1" avec un ">" précédent.
$ find / -user devconnected > file 2>&1Alternativement, vous pouvez utiliser le "&>" syntaxe comme un moyen plus court de rediriger à la fois la sortie et les erreurs.
$ find / -user devconnected &> fileAlors que s'est-il passé ici ?
Lorsque bash voit plusieurs redirections, il les traite de de gauche à droite.
Par conséquent, la sortie de la fonction de recherche est d'abord redirigée vers le fichier.
Ensuite, la deuxième redirection est traitée et redirige l'erreur standard vers la sortie standard (qui était précédemment affectée au fichier).
5 – Que sont les pipelines sous Linux ?
Les pipelines sont un peu différents des redirections.
Lors de la redirection d'entrée ou de sortie standard, vous écrasiez essentiellement l'entrée ou la sortie par défaut dans un fichier personnalisé.
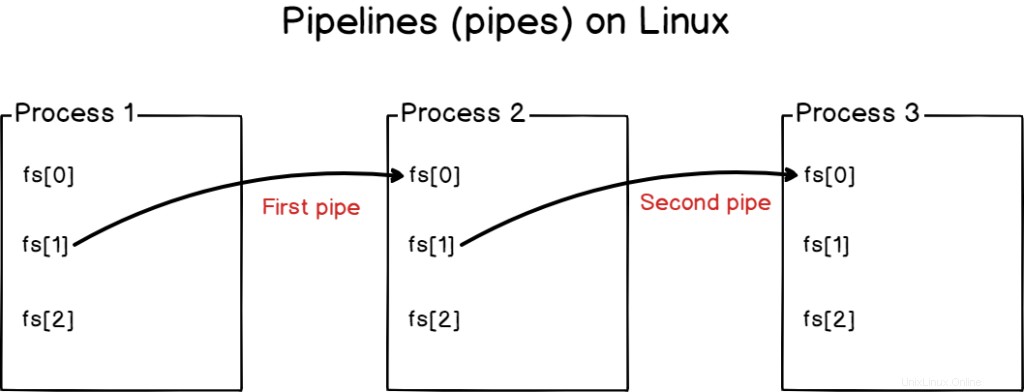
Avec les pipelines, vous n'écrasez pas les entrées ou les sorties, mais vous les connectez ensemble.
Les pipelines sont utilisés sur les systèmes Linux pour connecter les processus entre eux, reliant les sorties standard d'un programme à l'entrée standard d'un autre.
Plusieurs processus peuvent être liés avec des pipelines (ou tuyaux )
Les canaux sont largement utilisés par les administrateurs système afin de créer des requêtes complexes en combinant des requêtes simples.
L'un des exemples les plus populaires consiste probablement à compter le nombre de lignes dans un fichier texte, après avoir appliqué des filtres personnalisés sur le contenu du fichier.
Revenons au fichier de domaines que nous avons créé dans les sections précédentes et modifions leurs extensions de pays pour inclure les domaines .net.
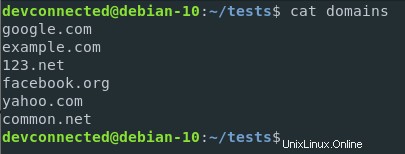
Supposons maintenant que vous souhaitiez compter le nombre de domaines .com dans le fichier.
Comment feriez-vous cela? En utilisant des tuyaux.
Tout d'abord, vous souhaitez filtrer les résultats pour isoler uniquement les domaines .com dans le fichier. Ensuite, vous voulez diriger le résultat vers la commande "wc" afin de les compter.
Voici comment compter les domaines .com dans le fichier.
$ grep .com domains | wc -l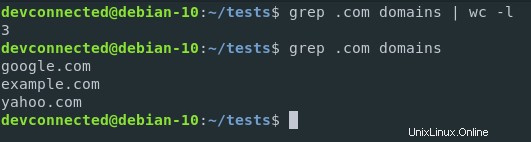
Voici ce qui s'est passé avec un diagramme au cas où vous ne le comprendriez toujours pas.
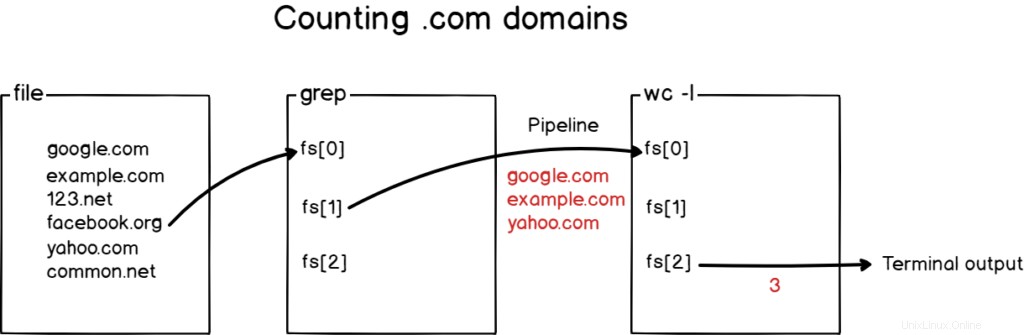
Génial !
6 – Conclusion
Dans le didacticiel d'aujourd'hui, vous avez appris ce qu'est la redirection d'entrée et de sortie et comment elle peut être utilisée efficacement pour effectuer des opérations administratives sur votre système Linux.
Vous avez également découvert les pipelines (ou tuyaux) qui servent à enchaîner les commandes afin d'exécuter des commandes plus longues et plus complexes sur votre hôte.
Si vous êtes curieux d'en savoir plus sur l'administration Linux, nous avons toute une catégorie qui lui est dédiée sur devconnected, alors n'hésitez pas à y jeter un coup d'œil !