Aujourd'hui, j'aimerais rompre avec mon récent modèle de didacticiels Windows vers Linux, qui se sont concentrés sur la façon d'installer, de configurer et d'utiliser une variété de programmes, généralement conçus ou destinés uniquement à Windows, en utilisant des cadres comme VIN. Ce dont nous allons discuter aujourd'hui est le sujet juteux de la gestion des disques et des lecteurs.
Au-delà des applications, il y a des données à prendre en compte. Et les données sont essentielles à tout. Les choses deviennent encore plus compliquées lorsque l'on considère les différences cardinales entre Windows et Linux. Le premier utilise NTFS et les données sont organisées en lecteurs (C:, D:, etc.). Linux stocke tout sous une arborescence de système de fichiers (racine, /) et utilise différents formats de système de fichiers (comme ext4), bien qu'il puisse gérer NTFS. Alors, qu'est-ce qui se passe si vous essayez de déplacer vos affaires ? Ce didacticiel est une suggestion intéressante pour ceux qui recherchent l'ordre, la simplicité et la clarté.
Lecture préliminaire
Ce guide ne peut pas vivre isolé. Il y a des lois dures de la physique auxquelles nous devons obéir. Tout d'abord, si vous ne connaissez rien à la gestion des disques et/ou des lecteurs, aux systèmes de fichiers, etc., cet article n'est pas vraiment pour vous. Vous avez besoin d'une base de base de ces principes. Soyons réalistes. Cet article est destiné aux nerds, même s'ils n'ont que peu d'expérience pratique de Linux (pour l'instant).
Cela dit, voici quelques-uns de mes articles que vous devriez lire avant d'approfondir :
Tutoriel du logiciel de partitionnement GParted
Le guide Linux ultime pour les débutants Windows
Pareil mais différent
Très bien, maintenant que nous connaissons le jargon et les détails techniques, discutons d'un scénario. Supposons que vous ayez une machine Windows avec deux disques physiques et un total de cinq partitions de disque. Supposons que la mise en page est la suivante :
- Lecteur C:\ :fichiers du système d'exploitation Windows et principal, fichiers de programme, données utilisateur
- Lecteur D:\ :installation des jeux (y compris, par exemple, Steam).
- E:\ lecteur – Données de l'utilisateur (fichiers, films, musique, documents, etc.) NON stockées sous Mes documents et autres.
- F:\ drive (sur le second disque) - Utilisé pour la sauvegarde ; ici, les données de l'utilisateur sont copiées une fois par semaine.
- Lecteur H:\ (sur le deuxième disque) :utilisé pour les éléments sans importance (téléchargements, vidéos brutes, etc.).
Supposons maintenant que le propriétaire de l'ordinateur avec l'arrangement de disque suivant souhaite passer à Linux. Donc, ce qu'ils font est comme suit :
Ils repartitionnent leurs disques - plus précisément, ils réduisent le lecteur H:\, puis créent un certain nombre de nouvelles partitions dans l'espace libéré (et maintenant vide). Ils installent ensuite une distribution Linux ici. Maintenant, ils exécutent un système à double amorçage, et lorsqu'ils allument l'ordinateur ou le redémarrent, ils voient un menu qui leur permet de choisir de continuer dans l'environnement Linux ou Windows.
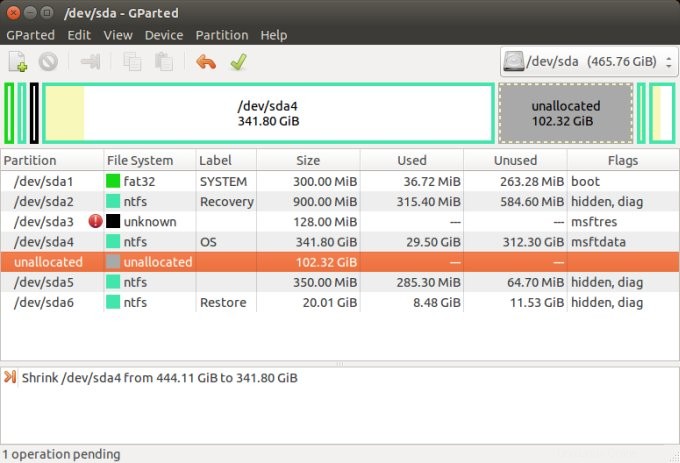
Comme vous pouvez le constater, j'ai décrit ce scénario et des scénarios similaires dans mes divers articles sur le double démarrage, comme celui lié ci-dessus, ainsi que dans les guides Windows 7 et Ubuntu et Windows 7 et CentOS. Cela devrait vous donner un bon point de référence pour une aventure similaire, ainsi que vous permettre d'avoir une idée de ce à quoi ressembleraient les différences initiales dans la gestion des disques sous Linux.
Or, l'utilisateur dispose d'un système à deux systèmes d'exploitation. Cependant, il y a un problème. La majeure partie des données réside toujours dans Windows et/ou est enregistrée/conservée sur des lecteurs Windows, formatés avec le système de fichiers NTFS. Il y a plusieurs questions ici :
- L'utilisateur peut-il accéder aux données Windows ?
- L'utilisateur peut-il modifier les données Windows ?
- L'utilisateur peut-il migrer les données des disques Windows vers les systèmes de fichiers Linux natifs sur d'autres partitions ?
- L'utilisateur peut-il (s'il le souhaite) convertir des systèmes de fichiers NTFS en systèmes Linux natifs ?
Répondons à ces questions, alors, d'accord !
- Linux peut lire les systèmes de fichiers NTFS sans aucun problème majeur. La plupart des distributions le supportent nativement.
- De même, Linux peut écrire sur les systèmes de fichiers NTFS. Cependant, toutes les distributions n'ont pas cette capacité prête à l'emploi. La solution à ce problème consiste à installer l'utilitaire NTFS-3g, qui offre les fonctionnalités nécessaires. Par exemple, dans les distributions Red Hat telles que CentOS, AlmaLinux ou Rocky Linux :
sudo dnf installer ntfs-3g ntfsprogs
- L'utilisateur peut migrer les données, mais dans le scénario ci-dessus, il se peut qu'il n'y ait tout simplement pas assez d'espace disponible sur la ou les partitions Linux nouvellement créées pour accueillir tous les éléments Windows, y compris les données, les sauvegardes et d'autres éléments. d'informations.
- La conversion de systèmes de fichiers est une opération risquée qui peut entraîner une perte de données. Cela ne devrait jamais être fait sans une sauvegarde complète et vérifiable des données en place. Mais d'ailleurs, si vous avez une sauvegarde en place, vous pouvez tout aussi bien formater les partitions avec le système de fichiers natif et copier les données dessus.
Opacité de la gestion des disques
La solution à la rareté de l'espace disque et/ou au chemin de migration facile des données est alors de présenter les données Windows à l'intérieur du système Linux, mais d'une manière qui sera facile à discerner, tout en permettant des sauvegardes de données pratiques. Pour expliquer ce que je veux dire, considérez ce qui suit :
Sous Linux, tous les chemins se résolvent en une racine (/). Par exemple, /home/igor serait le point de montage du répertoire personnel de l'utilisateur nommé "igor". Mais le mappage physique de ce répertoire peut être n'importe où. Il peut s'agir d'une partition différente, d'un disque différent, voire d'un système différent (sur un réseau). Par exemple :
- Le système de fichiers racine (/) est un point de montage pour /dev/sda1 (la première partition sur le premier disque).
- home/igor est un répertoire et non un point de montage séparé. Les données résident sur /dev/sda1 (le même disque).
- Alternativement, le chemin /home/igor pourrait être résolu en /dev/sda2 ou /dev/sdc7 ou même en partages NFS, CIFS ou Samba.
Cela signifie que si un utilisateur monte des lecteurs Windows, ils seront présentés sous Linux dans le cadre du système de fichiers racine unique, et ils ne seront pas nécessairement discernables à partir d'autres emplacements ou chemins. Encore une fois, par exemple :
La plupart des systèmes Linux monteront des périphériques amovibles, externes ou non-Linux sous /run/media ou /media. Ainsi, si vous voyez deux répertoires sous ces emplacements, quel que soit leur nom, vous ne pourrez pas nécessairement les distinguer. L'une peut être une partition interne au format Windows NTFS et l'autre une clé USB au format FAT32.
La solution, alors
Pour contourner ce problème, j'utilise la méthode suivante :
- Je crée un nouveau répertoire de niveau supérieur sous la racine appelé drives (/drives).
- À l'intérieur, je crée des répertoires qui serviront de points de montage pour les lecteurs Windows, avec des lettres comme identifiants. Par exemple, /drive/C sera utilisé comme point de montage pour le lecteur C:\, et /drive/E sera utilisé comme point de montage pour le lecteur E:\, et ainsi de suite.
- Je crée des règles de montage permanentes pour les lecteurs Windows sous /etc/fstab (plus d'informations à ce sujet sous peu). Cela signifie qu'au démarrage du système, les lecteurs Windows seront montés en tant que périphériques inscriptibles et présentés sous forme de répertoires sous l'emplacement /drives de niveau supérieur.
Qu'est-ce que cette méthode garantit ?
Cette approche présente de nombreux avantages utiles :
- Il permet une séparation claire et visible entre les chemins Linux uniquement ou Linux pur et les chemins Windows.
- Il ne mélange pas tous les périphériques/partitions non-Linux sous des répertoires génériques.
- L'exécution de scripts de sauvegarde garantit que tout n'est pas copié ou sauvegardé, mais uniquement ce dont vous avez besoin. Si vous effectuez une sauvegarde complète de votre système Linux et que vous avez d'autres systèmes de fichiers et lecteurs montés, vous ne voulez pas nécessairement qu'ils soient inclus dans la sauvegarde et vous ne voulez pas avoir à tenir compte de chaque chemin "inconnu". .
Voici comment vous pouvez le faire
Suivant notre exemple précédent, la première étape consiste à comprendre comment Linux "voit" les disques durs internes et comment il identifie les lecteurs Windows. Encore une fois, vous avez besoin d'un peu d'expertise ici. Vous pouvez utiliser les outils de ligne de commande tels que fdisk pour afficher la liste des périphériques et leurs partitions. Supposons ce qui suit :
- /dev/sda1 - lecteur C:\
- /dev/sda2 - lecteur D:\
- /dev/sda3 - lecteur E:\
- /dev/sdb1 - lecteur F:\
- /dev/sdb2 - lecteur H:\
- /dev/sdb3 - racine Linux (/)
- /dev/sdb4 - Échange Linux
- /dev/sdb5 - Linux home (/home)
Créez le chemin de niveau supérieur /drives et les répertoires en dessous (pour les lecteurs Windows uniquement) :
sudo mkdir /drives
sudo mkdir /drives/C
sudo mkdir /drives/D
...
Maintenant, en tant que root ou sudo, créez une sauvegarde du fichier /etc/fstab puis modifiez-le dans un éditeur de texte (comme nano) :
sudo cp /etc/fstab /home/"votre utilisateur"/fstab-backup
sudo nano /etc/fstab
Dans l'éditeur de texte, ajoutez des points de montage à vos lecteurs Windows.
/dev/sda1 /drives/C ntfs-3g defaults,locale=utf8 0 0
/dev/sda2 /drives/D ntfs-3g defaults,locale=utf8 0 0
...
Qu'avons-nous ici ?
- Nous spécifions le périphérique/la partition que nous voulons monter.
- Nous spécifions le point de montage.
- Nous spécifions le système de fichiers - dans ce cas, nous utilisons le pilote de système de fichiers ntfs-3g (nous donne un accès en lecture/écriture).
- Nous spécifions les options de montage - en gardant les choses simples avec les valeurs par défaut, plus l'encodage UTF8.
- Nous définissons les deux derniers champs (dump et fsck) sur 0, ils sont donc exclus des opérations Linux classiques.
Voici un exemple réel de l'un de mes systèmes :
#
# / était sur /dev/nvme0n1p5 lors de l'installation
# /boot/efi était sur /dev/nvme0n1p1 pendant l'installation
UUID=7f4087e7-e572-44fd-a4a1-7489099937a0 / ext4 errors=remount-ro 0 1
UUID=C05A-951D /boot/efi vfat umask=0077 0 1
/swapfile aucun swap sw 0 0
/dev/nvme0n1p3 /drives/C ntfs-3g defaults,locale=utf8 0 0
Les trois premières entrées non commentées sont des entrées de montage pour les systèmes de fichiers Linux, y compris la racine (/), /boot/efi, qui est requise sur les systèmes UEFI (elle affiche également un système de fichiers VFAT), et un fichier d'échange plutôt qu'une partition d'échange.
La quatrième entrée est l'ajout d'un lecteur Windows. Veuillez noter que l'identifiant de l'appareil n'est pas /dev/sdaXY mais plutôt /dev/nvmeXnYp3. La raison en est que le système dispose d'un disque dur NVMe et que le système Linux l'identifie différemment des périphériques IDE/SATA/SCSI. Mais à toutes fins pratiques, la notation est la même.
Nous avons un premier (0) bus NVMe, un premier (1) périphérique, une troisième (3) partition. Encore une fois, veuillez vous référer à mes guides sur la gestion du disque dur plus tôt, ainsi qu'au tutoriel GRUB, car la notation pour les périphériques et les partitions est différente. Et donc, dans l'exemple ci-dessus, nous montons notre partition Windows, en fait la troisième partition sur le disque NVMe, sous /drives/C.
Vous n'avez pas besoin de redémarrer pour voir l'effet, il vous suffit de tout remonter :
sudo mount -a
Maintenant, vos lecteurs Windows seront montés sur les chemins correspondants et vous pourrez voir les données. L'étape suivante consiste à faciliter l'utilisation et l'accès aux données montées.
Gestionnaire de fichiers et lecteurs Windows
Si vous souhaitez utiliser les données de l'interface graphique (pas de la ligne de commande), vous pouvez faire l'astuce suivante :
- Créez des liens symboliques dans votre répertoire personnel vers les lecteurs montés.
- Plus précisément, liez symboliquement chaque lecteur (lettre) à un dossier doté d'un identifiant significatif, comme les noms de lecteur Windows.
ln -s /lecteurs/C ~/Windows
La commande ci-dessus créera un lien symbolique dans votre répertoire personnel. Windows mappera sur /drives/C, qui est le point de montage sur le lecteur C:\. Ainsi, lorsque vous cliquez sur le dossier Windows dans votre gestionnaire de fichiers Linux, vous verrez le contenu du lecteur Windows.
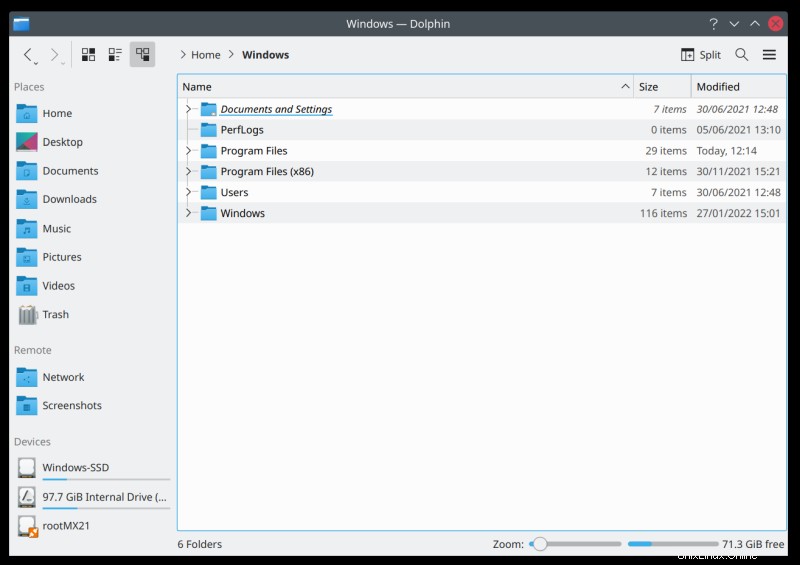
Maintenant, vous pouvez aller plus loin et créer des raccourcis vers ces lecteurs. Par exemple, dans l'environnement de bureau Plasma, vous pouvez ajouter des raccourcis à la barre latérale, de sorte que Windows mappe vers /drives/C, les jeux mappent vers /drives/D, les données mappent vers /drives/E, etc. Votre prochaine étape consiste à ajouter potentiellement des tâches de sauvegarde dans le flux, mais c'est un sujet pour un autre didacticiel.
Conclusion
Mon tutoriel n'est pas le Saint Graal de la gestion des données. Loin de là. Mais il fournit des suggestions élégantes aux problèmes courants auxquels les gens peuvent être confrontés en passant de Windows à Linux. Il fournit un moyen de présenter les données Windows de manière visible et intuitive. Il n'inclut aucune opération destructive. Il permet des sauvegardes pratiques et une séparation des données. Et il offre aux personnes habituées au flux de travail Windows de s'adapter lentement au nouvel environnement sans compromettre les indices familiers ou les flux de travail établis.
Avec les lecteurs Windows uniquement montés dans leur propre chemin, des liens symboliques pour vous donner un accès pratique via des outils d'interface graphique et un mappage logique, vous devriez maintenant avoir une bonne base solide pour votre migration. L'étape suivante consiste à vous assurer que vos données importantes sont sauvegardées. Parce que les données sans sauvegardes ne sont qu'une tragédie qui attend de se produire. Nous couvrirons cela, ainsi que de nombreux autres conseils pratiques au jour le jour dans des articles de suivi. Pour l'instant, réfléchissez un peu au schéma de données que j'ai décrit ci-dessus. Et restez à l'écoute pour des guides de configuration de programme supplémentaires. A bientôt.