En tant qu'administrateur Linux ou utilisateur avancé, la maîtrise de la gestion des fichiers dans la distribution du système d'exploitation Linux que vous utilisez est primordiale. La gestion des fichiers est un aspect essentiel de l'administration du système d'exploitation Linux et sans elle, nous ne serions pas en mesure d'adopter des fonctionnalités liées aux fichiers telles que le cryptage des fichiers, la gestion des utilisateurs de fichiers, la conformité des fichiers, les mises à jour et la maintenance des fichiers et la gestion du cycle de vie des fichiers.
Dans cet article, nous examinerons un aspect important de la gestion de fichiers Linux qui divise les fichiers volumineux en parties à des numéros de ligne donnés. Si l'objectif de cet article était simplement de diviser un gros fichier en petits fichiers gérables sans tenir compte des numéros de ligne de fichier, alors tout ce dont nous aurions besoin est la commodité du split commande.
Exemple de fichier de référence
Pour que ce didacticiel ait un sens, nous allons introduire un exemple de fichier texte qui servira de fichier volumineux que nous souhaitons séparer à partir de numéros de ligne donnés. Créez un exemple de fichier texte et remplissez-le comme indiqué.
$ sudo nano sample_file.txt
Ouvrez ce fichier avec la commande cat pour noter ses numéros de ligne associés :
$ cat -n sample_text.txt
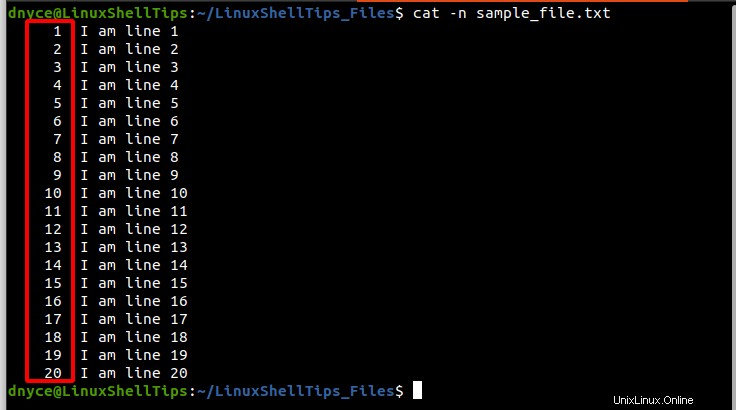
Comme vous l'avez noté, le fichier ci-dessus contient 1 à 20 numéros de ligne. Supposons maintenant que nous voulions diviser ce fichier en 4 pièces aux numéros de ligne 5 , 11 , et 17 .
On obtiendrait les fichiers suivants :
- file_1 contenant les lignes 1 à 5 de sample_file.txt.
- file_2 contenant les lignes 6 à 11 de sample_file.txt.
- file_3 contenant les lignes 12 à 17 de sample_file.txt.
- file_4 contenant les lignes 18 à 20 de sample_file.txt.
Maintenant que nous avons compris notre énoncé de problème, il est temps d'examiner les méthodologies nécessaires pour une solution viable.
1. Utilisation des commandes de tête et de queue
L'efficacité de la combinaison de ces deux commandes pour diviser un fichier volumineux en parties à partir des numéros de ligne fournis nécessite l'inclusion du -n option dans le cadre de l'exécution de sa commande.
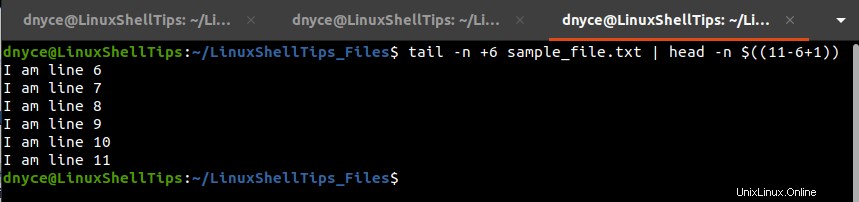
Pour extraire les numéros de ligne 6 à 11 , nous allons exécuter la commande suivante.
$ tail -n +3 sample_file.txt | head -n $(( 11-6+1 ))
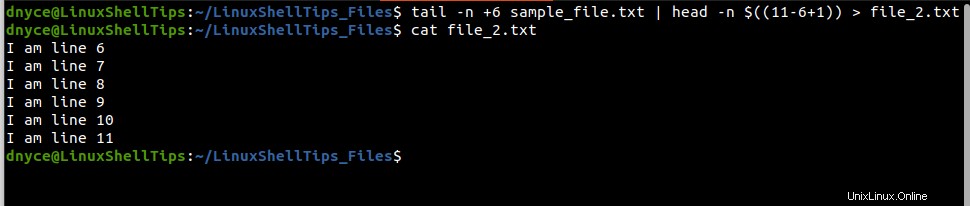
Pour enregistrer cette sortie dans file_2.txt :
$ tail -n +6 sample_file.txt | head -n $((11-6+1)) > file_2.txt $ cat file_2.txt
2. Utilisation de la commande sed
Depuis le sed la commande prend en charge deux plages d'adresses données, nous pouvons extraire les lignes 12 à 17 de la manière suivante.
$ sed -n '12,17p; 18q' sample_file.txt

Nous pouvons modifier la commande pour enregistrer la sortie ci-dessus dans file_3.txt .
$ sed -n '12,17p; 18q' sample_file.txt > file_3.txt $ cat file_3.txt

3. Utilisation de la commande awk
Le maladroit La commande prend en charge de nombreuses fonctionnalités telles que la redirection, les boucles et les tableaux. Par conséquent, nous pouvons l'utiliser pour créer toutes les parties de fichiers nécessaires (file_1.txt , fichier_2.txt , fichier_3.txt , et file_4.txt ) à partir d'un fichier volumineux (sample_file.txt ) avec une seule phrase de commande, comme illustré ci-dessous.
Le maladroit la commande est fournie avec les numéros de ligne clés (5 , 11 , et 17 ) nécessaire pour diviser sample_file.txt en quatre parties (file_1.txt , fichier_2.txt , fichier_3.txt , et file_4.txt ).
$ awk -v nums="5 11 17" '
BEGIN {
c=split(nums,b)
for(i=1; i<=c; i++) a[b[i]] j=1; out = "file_1.txt" } { print > out }
NR in a {
close(out)
out = "file_" ++j ".txt"
}' sample_file.txt
Le résultat de l'exécution du awk ci-dessus La commande est évidente dans la capture d'écran suivante.
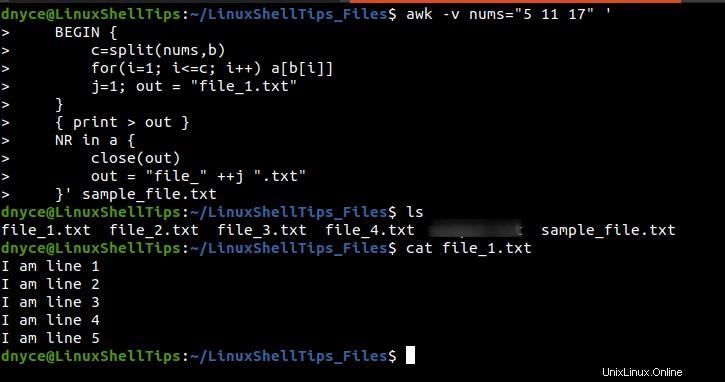
Nous pouvons maintenant diviser confortablement des fichiers volumineux en parties en fonction des numéros de ligne fournis grâce à diverses approches, comme indiqué dans ce didacticiel.
Vous aimerez peut-être également lire les articles connexes suivants :
- Comment compresser plus rapidement des fichiers volumineux (plus de 100 Go) sous Linux
- Comment créer un gros fichier de 1 Go ou 10 Go sous Linux
- Comment copier un grand nombre de fichiers sous Linux