En tant qu'administrateur système, il est impératif de faciliter la haute disponibilité à tous les niveaux possibles dans l'architecture et la conception d'un système et l'environnement SAP n'est pas différent. Dans cet article, j'explique comment tirer parti de Red Hat Enterprise Linux (RHEL) Pacemaker pour la haute disponibilité (HA) de SAP NetWeaver Advanced Business Application Programming (ABAP) SAP Central Service (ASCS)/Enqueue Replication Server (ERS).
[ Vous pourriez également aimer : Guide de démarrage rapide d'Ansible pour les administrateurs système Linux ]
SAP a une architecture à trois couches :
- Couche de présentation —Présente une interface graphique pour l'interaction avec l'application SAP
- Couche d'application —Contient un ou plusieurs serveurs d'applications et un serveur de messages
- Couche de base de données —Contient la base de données avec toutes les données liées à SAP (par exemple, Oracle)
Dans cet article, l'accent est mis sur la couche application. Les instances de serveur d'applications fournissent les fonctions de traitement de données réelles d'un système SAP. En fonction de la configuration système requise, plusieurs serveurs d'applications sont créés pour gérer la charge sur le système SAP. Un autre composant principal de la couche application est le service central ABAP SAP (ASCS). Les services centraux comprennent deux composants principaux :Message Server (MS) et Enqueue Server (ES). Le Message Server agit comme un canal de communication entre tous les serveurs d'application et gère la répartition de la charge. Le serveur de mise en file d'attente contrôle le mécanisme de verrouillage.
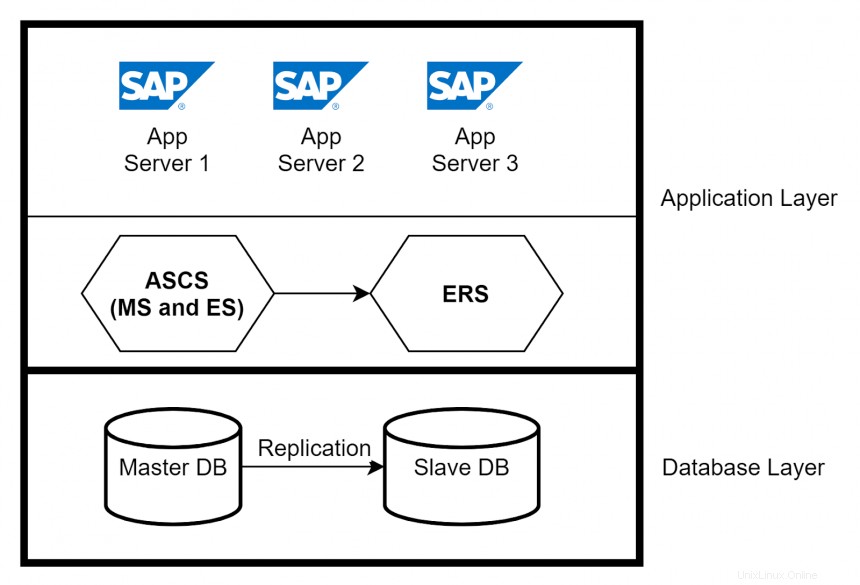
Haute disponibilité dans les couches application et base de données
Vous pouvez implémenter la haute disponibilité pour les serveurs d'applications en utilisant un équilibreur de charge et en faisant en sorte que plusieurs serveurs d'applications gèrent les demandes des utilisateurs. Si un serveur d'applications tombe en panne, seuls les utilisateurs connectés à ce serveur sont impactés. Isolez le plantage en supprimant le serveur d'applications de l'équilibreur de charge. Pour une haute disponibilité d'ASCS, utilisez Enqueue Replication Server (ERS) pour répliquer les entrées de la table de verrouillage. Dans la couche de base de données, vous pouvez configurer la réplication de base de données native entre les bases de données principales et secondaires pour garantir une haute disponibilité.
Introduction à la haute disponibilité RHEL avec Pacemaker
La haute disponibilité RHEL permet aux services de basculer d'un nœud à un autre de manière transparente au sein d'un cluster sans provoquer d'interruption du service. ASCS et ERS peuvent être intégrés dans un cluster RHEL Pacemaker. En cas de défaillance d'un nœud ASCS, les packages de cluster se déplacent vers un nœud ERS où les instances MS et ES continueront de fonctionner sans arrêter le système. En cas de défaillance d'un nœud ERS, le système n'est pas affecté car MS et ES continueront de fonctionner sur le nœud ASCS. Dans ce cas, l'instance ERS ne s'exécutera pas sur le nœud ASCS car les instances ES et ERS n'ont pas besoin de s'exécuter sur le même nœud.
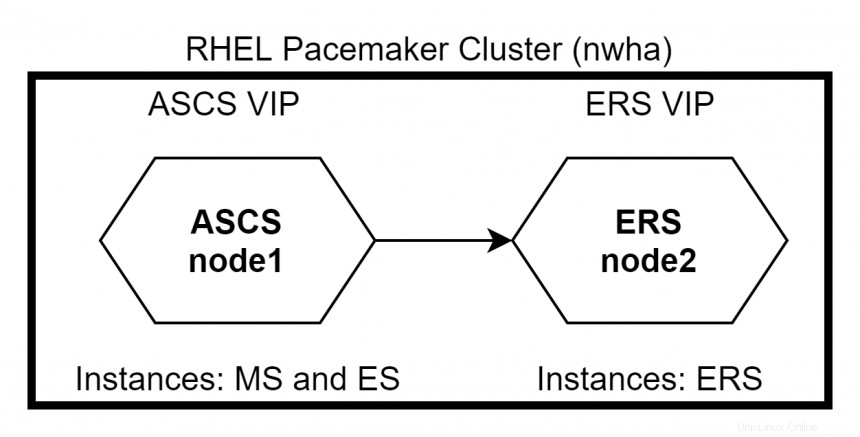
Configuration du stimulateur cardiaque RHEL
Il existe deux manières de configurer les nœuds ASCS et ERS dans le cluster RHEL Pacemaker :Primaire/Secondaire et autonome . Le Primaire/Secondaire est prise en charge dans toutes les versions mineures de RHEL 7. L'approche autonome est prise en charge dans RHEL 7.5 et versions ultérieures. RHEL recommande l'utilisation de l'approche autonome pour tous les nouveaux déploiements.
Paramétrage du cluster
Les grandes étapes de la configuration du cluster incluent :
- Installez les packages Pacemaker sur les deux nœuds du cluster.
# yum -y install pcs pacemaker - Créer le HACLUSTER ID utilisateur avec.
Pour utiliser# passwd haclusterpcspour configurer le cluster et communiquer entre les nœuds, vous devez définir un mot de passe sur chaque nœud pour l'ID utilisateur hacluster , qui est lepcscompte administratif. Il est recommandé que le mot de passe de l'utilisateur hacluster être le même sur chaque nœud. - Activer et démarrer le
pcsprestations de service.# systemctl enable pcsd.service; systemctl start pcsd.service - Authentifier
pcsavec hacluster user
Authentifier lepcsutilisateur hacluster pour chaque nœud du cluster. La commande suivante authentifie l'utilisateur hacluster sur nœud1 pour les deux nœuds d'un cluster à deux nœuds (node1.example.com et node2.example.com).# pcs cluster auth node1.example.com node2.example.com Username: hacluster Password: node1.example.com: Authorized node2.example.com: Authorized - Créez le cluster.
Cluster nwha est créé en utilisant node1 et node2 :# pcs cluster setup --name nwha node1 node2 - Démarrez le cluster.
# pcs cluster start --all - Activez le démarrage automatique du cluster après le redémarrage.
# pcs cluster enable --all
Création de ressources pour les instances ASCS et ERS
Maintenant que le cluster est configuré, vous devez ajouter les ressources pour les nœuds ASCS et ERS. Les étapes générales incluent :
- Installer
resource-agents-sapsur tous les nœuds du cluster.# yum install resource-agents-sap - Configurez le système de fichiers partagé en tant que ressources gérées par le cluster.
Le système de fichiers partagé, tel que/sapmnt,/usr/sap/trans,/usr/sap/sont ajoutées en tant que ressources montées automatiquement sur le cluster à l'aide de la commande :SYS # pcs resource create <resource-name> Filesystem device=’<path-of-filesystem>’ directory=’<directory-name>’ fstype=’<type-of-fs>’
Exemple :# pcs resource create sid_fs_sapmnt Filesystem device='nfs_server:/export/sapmnt' directory='/sapmnt' fstype='nfs' - Configurer le groupe de ressources pour ASCS.
Pour le nœud ASCS, les trois groupes de ressources requis sont les suivants (en supposant que l'ID d'instance d'ASCS est 00) :- Adresse IP virtuelle pour l'ASCS
- Système de fichiers ASCS (par exemple,
/usr/sap/<SID>/ASCS00) - Instance de profil ASCS (par exemple,
/sapmnt/<SID>/profile/<SID>_ASCS00_<hostname>)
- Configurer le groupe de ressources pour ERS.
Pour le nœud ERS, les trois groupes de ressources requis sont les suivants (en supposant l'ID d'instance d'ERS dans 30) :- Adresse IP virtuelle pour l'ERS
- Système de fichiers ERS (par exemple,
/usr/sap/<SID>/ERS30) - Instance de profil ERS (par exemple,
/sapmnt/<SID>/profile/<SID>_ERS30_<hostname>)
- Créez les contraintes.
Définissez les contraintes des groupes de ressources ASCS et ERS pour les éléments suivants :- Empêcher les deux groupes de ressources de s'exécuter sur le même nœud
- Exécuter ASCS sur le nœud où ERS s'exécutait en cas de basculement
- Maintenir l'ordre de démarrage/d'arrêt
- Assurez-vous que le cluster est démarré uniquement après le montage des systèmes de fichiers requis
Test de basculement de cluster
En supposant qu'ASCS s'exécute sur node1 et ERS s'exécute sur node2 initialement. Si nœud1 tombe en panne, ASCS et ERS passent tous les deux à node2 . En raison de la contrainte définie, ERS ne fonctionnera pas sur node2 .
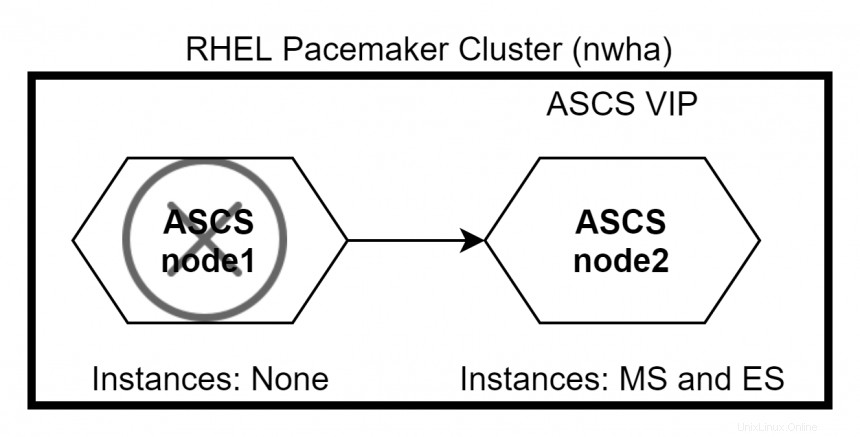
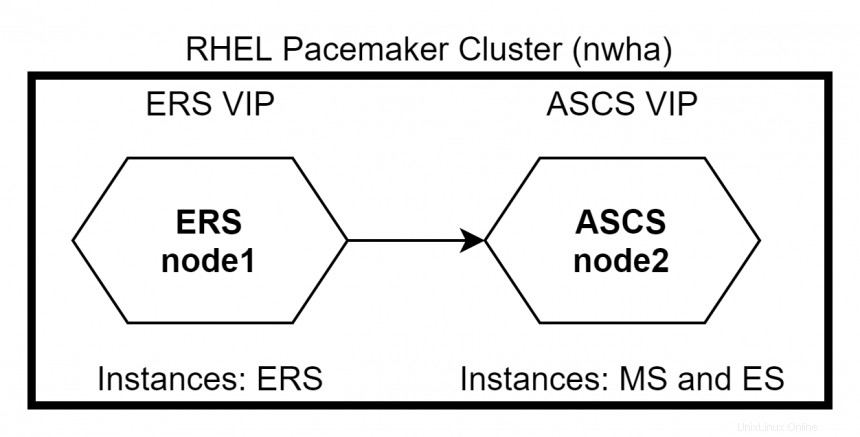
Lorsque nœud1 revient, ERS passera à node1 tandis que ASCS reste sur node2 . Utilisez la commande #pcs status pour vérifier l'état du cluster.
[ Un cours gratuit pour vous :présentation technique de la virtualisation et de la migration d'infrastructure. ]
Conclusion
RHEL Pacemaker est un excellent utilitaire pour atteindre un cluster hautement disponible pour SAP. Vous pouvez également effectuer une clôture en configurant STONITH pour garantir l'intégrité des données et éviter l'utilisation des ressources par un nœud défectueux dans le cluster.
Pour tous les passionnés d'automatisation, vous pouvez utiliser Ansible pour contrôler votre cluster Pacemaker en utilisant le module Ansible pacemaker_cluster. Autant que vous protégez vos systèmes, prenez soin de vous et restez en sécurité.