Nous enchevêtrerons des bourgeons et des fleurs et des poutres
Qui scintillent au bord de la fontaine, et font
Combinaisons étranges de choses communes
"Prométhée non lié" par Percy Bysshe Shelley
Bienvenue dans le monde de la collecte de métriques et du suivi des performances. Comme pour la plupart des choses informatiques, des secteurs entiers du marché ont été construits pour vendre ces outils. Et, bien sûr, plusieurs utilitaires open source ont le même objectif. C'est l'un de ces outils open source que nous allons examiner.
Qu'est-ce que Prométhée ?
Prometheus est un outil de collecte de métriques et d'alerte développé et publié en open source par SoundCloud. Prometheus est similaire dans sa conception au système de surveillance Borgmon de Google, et un système relativement modeste peut gérer la collecte de centaines de milliers de métriques chaque seconde. Correctement réglé et déployé, un cluster Prometheus peut collecter des millions de métriques chaque seconde.
Prometheus est composé d'environ quatre parties :
- L'application Prometheus principale elle-même, chargée de récupérer les métriques, de les stocker dans la base de données et (éventuellement) de les récupérer lorsqu'elles sont interrogées.
- Le backend de la base de données est une base de données interne de séries temporelles. Cette base de données est toujours utilisée, mais les données peuvent également être envoyées à des backends de stockage distants.
- Les exportateurs sont des programmes externes facultatifs qui ingèrent des données provenant de diverses sources et les convertissent en métriques que Prometheus peut récupérer.
- Les exportateurs sont spécialement conçus pour travailler avec des applications et du matériel spécifiques.
- AlertManager est un système de gestion des alertes fourni avec Prometheus.
- Les bibliothèques clientes peuvent être utilisées pour instrumenter des applications personnalisées.
Je dis "environ" quatre parties car de nombreuses applications supplémentaires sont souvent utilisées avec un cluster Prometheus standard. Si vous avez besoin ou souhaitez de meilleures capacités graphiques, des applications comme Grafana peuvent être déployées. Si vous avez besoin de stocker des métriques pendant de longues périodes, les backends de stockage à distance valent la peine d'être envisagés. Et la liste continue. Pour cet article, cependant, nous allons nous concentrer sur Prometheus lui-même avec un petit détour par les exportateurs.
[ Vous pourriez également aimer : 6 compétences d'administrateur système dont les développeurs Web ont besoin ]
Qu'est-ce qu'une statistique ?
Avant d'en arriver là, nous devons comprendre pourquoi quelque chose comme Prometheus existe. Commençons donc par une question :que sont les métriques ? En termes simples, les métriques mesurent quelque chose. Par exemple, le temps qu'il vous faut pour lire cet article est une métrique. Le nombre de mots est une métrique. Le nombre moyen de lettres dans les mots de cet article est une mesure.
Cependant, ces mesures sont assez statiques et ne nécessitent pas nécessairement un système comme Prometheus. Prometheus excelle dans les métriques qui changent avec le temps. Par exemple, que se passe-t-il si vous voulez savoir combien de "vues" cet article obtient ? Et si vous vouliez savoir combien de trafic entre et sort de votre réseau ? Ou combien de cycles de construction et de déploiement se produisent chaque heure ? Toutes ces métriques peuvent être introduites dans Prometheus.
Maintenant que nous comprenons ce qu'est une métrique, regardons comment Prometheus obtient les métriques qu'il doit stocker. La première chose dont Prometheus a besoin est une cible . Les cibles sont les points de terminaison qui fournissent les métriques stockées par Prometheus. Ces points de terminaison peuvent être le point de terminaison réel surveillé, ou ils peuvent être un élément de middleware connu sous le nom d'exportateur. Les points de terminaison peuvent être fournis via une configuration statique ou ils peuvent être "trouvés" via un processus appelé découverte de service. La découverte de service est un sujet plus avancé pour un prochain article.
Une fois que Prometheus dispose d'une liste de points de terminaison, il peut commencer à en récupérer les métriques. Prometheus récupère les métriques de manière très simple; une simple requête HTTP. La configuration pointe vers un emplacement spécifique sur le point de terminaison qui fournit un flux de texte identifiant la métrique et sa valeur actuelle. Prometheus lit ce flux de texte, ignore les lignes commençant par un # sous forme de commentaires et stocke les métriques qu'il reçoit dans une base de données locale.
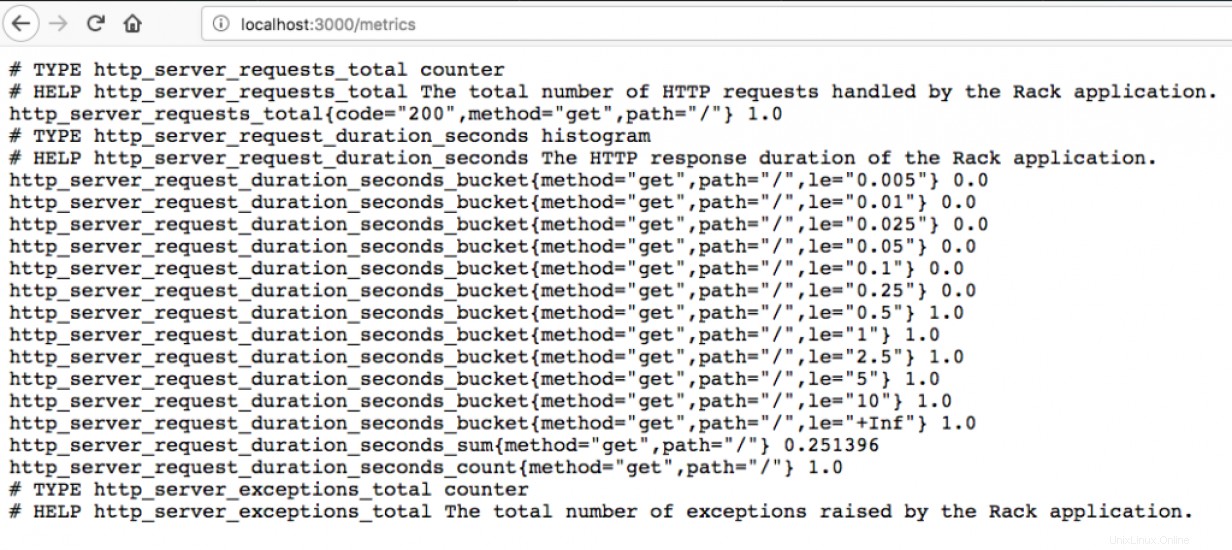
Un court détour vers les exportateurs
Prometheus ne peut utiliser HTTP que pour communiquer avec des points de terminaison pour la collecte de métriques. Que se passe-t-il lorsque vous essayez de surveiller un routeur ou un commutateur qui communique uniquement via SNMP ? Ou peut-être souhaitez-vous surveiller un service cloud qui n'a pas de point de terminaison de métrique Prometheus natif ? Heureusement, il existe une solution :les exportateurs.
Les exportateurs se présentent sous de nombreuses formes et tailles. Ce sont de petits programmes spécialement conçus pour se tenir entre Prometheus et tout ce que vous souhaitez surveiller qui ne prend pas nativement en charge Prometheus. Certains exportateurs restent inactifs jusqu'à ce que Prometheus leur demande des données. Lorsque cela se produit, l'exportateur contacte l'appareil qu'il surveille, obtient les données pertinentes et les convertit dans un format que Prometheus peut ingérer. D'autres exportateurs interrogent automatiquement les appareils, mettant en cache les résultats localement pour que Prometheus les récupère plus tard.
Quelle que soit leur conception, les exportateurs agissent comme des traducteurs entre Prometheus et les terminaux que vous souhaitez surveiller. Si vous essayez de surveiller un appareil ou une application courant, il y a de fortes chances qu'il existe un exportateur pour cela.
Stockage des données
Prometheus utilise un type spécial de base de données sur le back-end connu sous le nom de base de données de séries chronologiques. En termes simples, cette base de données est optimisée pour stocker et récupérer des données organisées en valeurs sur une période de temps. Les métriques sont un excellent exemple du type de données que vous stockeriez dans une telle base de données.
Le stockage externe est également une option. Il existe de nombreux choix, tels que Thanos, Cortex et VictoriaMetrics, qui offrent une variété d'avantages. L'un des principaux avantages est la centralisation des métriques collectées et le stockage à long terme. Des outils tels que Grafana peuvent interroger directement ces solutions de stockage tierces.
Donc, vous avez un tas de métriques...
Maintenant que vous êtes un expert de Prometheus et que vous l'avez stocké, comment utilisez-vous ces données ? Tout comme une base de données SQL, Prometheus a un langage de requête personnalisé appelé PromQL. PromQL est assez simple pour les métriques simples mais a beaucoup de complexité en cas de besoin. Le fait de fournir le nom d'une métrique affichera toutes les "instances" de cette métrique :
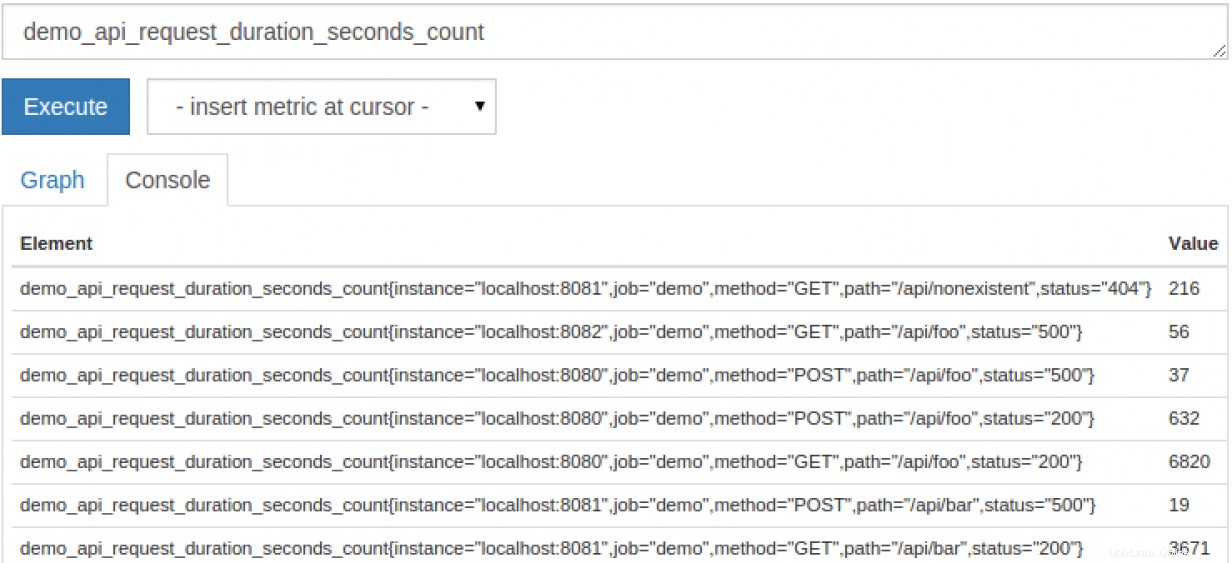
Vous pouvez également utiliser certaines méthodes PromQL pour générer un graphique représentant les données que vous recherchez.
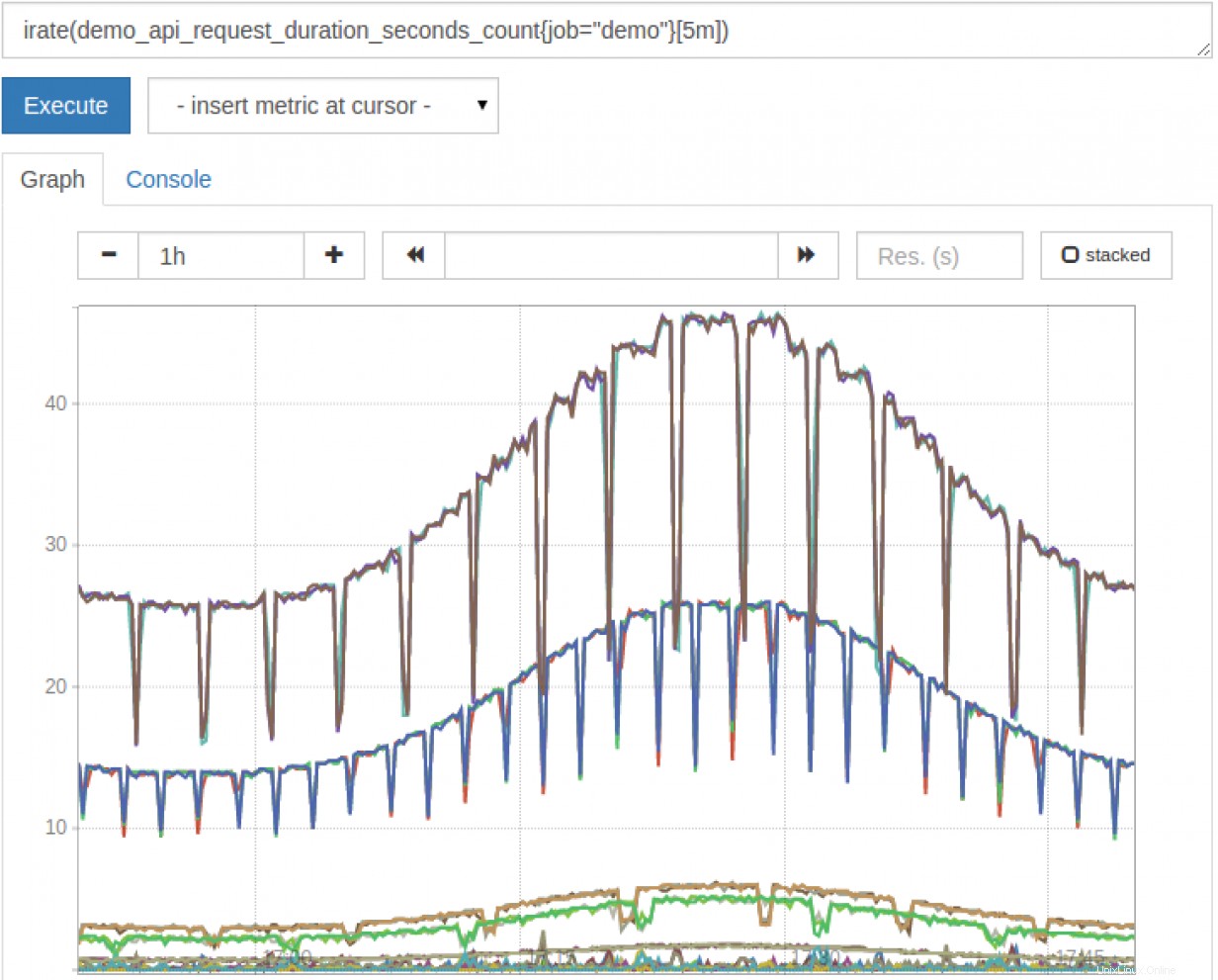
Bien sûr, si vous êtes sérieux au sujet des graphiques, cela vaut la peine d'examiner un package tel que Grafana. Grafana vous permet de créer des tableaux de bord de métriques, d'envoyer des alertes, etc.
Alerte
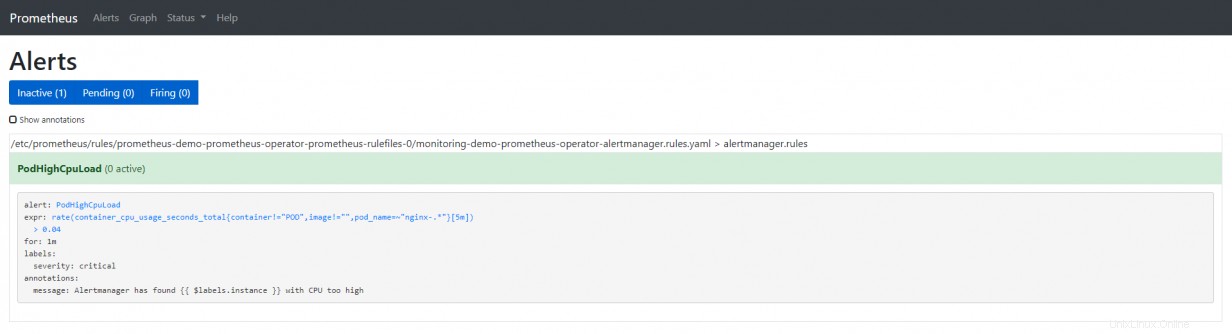
Bien que les graphiques soient jolis à regarder, les métriques peuvent servir un autre objectif important. Ils peuvent être utilisés pour envoyer des alertes. Prometheus inclut une application distincte, appelée AlertManager, qui sert à cette fin. AlertManager reçoit les notifications de Prometheus et gère toute la logique nécessaire pour dédupliquer et envoyer les alertes.
Les alertes sont créées en écrivant des règles d'alerte. Ces règles sont simplement des requêtes PromQL qui se déclenchent lorsque la requête est vraie. Autrement dit, si vous avez une requête qui vérifie si la température sur le processeur est supérieure à 80 °C, la requête se déclenche pour chaque métrique qui remplit cette condition.
Les règles d'alerte peuvent également inclure une période pendant laquelle une règle doit être évaluée comme vraie. En développant notre exemple de température, dépasser 80 ° C est acceptable si c'est une courte période de temps, mais si cela dure plus de cinq minutes, envoyez une alerte. Les alertes peuvent être envoyées par e-mail, Slack, Twitter, SMS et à peu près tout ce pour quoi vous pouvez écrire une interface.
[ Vous souhaitez en savoir plus sur l'automatisation du système ? Démarrez avec The Automated Enterprise, un livre gratuit de Red Hat. ]
Récapitulez
La surveillance est importante. Cela aide à identifier quand les choses ont mal tourné et cela peut montrer quand les choses vont bien. Une surveillance appropriée peut être utilisée dans diverses disciplines pour extraire tout ce que vous pouvez de l'objet surveillé.
Prometheus est un puissant package de métriques open source. Il est hautement évolutif, robuste et extrêmement rapide. Un seul serveur moderne peut être utilisé pour surveiller un million de métriques ou plus par seconde. La distribution des serveurs Prometheus permet de surveiller plusieurs dizaines, voire centaines de millions de métriques chaque seconde.
PromQL fournit un langage d'interrogation robuste qui peut être utilisé pour les graphiques ainsi que pour les alertes. Le système graphique intégré est idéal pour les visualisations rapides, mais les tableaux de bord à plus long terme doivent être gérés dans des applications externes telles que Grafana.