Lors du téléchargement de fichiers, il n'est pas rare de voir le .tar , .zip ou .gz extensions. Mais connaissez-vous la différence entre Tar et Zip et Gz ? Pourquoi les utilisons-nous et lequel est le plus efficace, tar ou zip ou gz ?
Différence entre tar, zip et gz
Si vous êtes pressé ou si vous souhaitez simplement obtenir quelque chose de facile à retenir, voici la différence entre zip, tar et gz :
.tar ==fichier archive non compressé
.zip ==(généralement) fichier archive compressé
.gz ==fichier (archive ou non) compressé avec gzip

Un peu d'historique des fichiers d'archives
Comme beaucoup de choses sur les systèmes Unix et de type Unix, l'histoire commence il y a très longtemps, dans une galaxie pas si lointaine appelée les années soixante-dix. Par un froid matin de janvier 1979, le goudron L'utilitaire a fait son apparition dans le cadre du nouveau Unix V7.
Le tar L'utilitaire a été conçu comme un moyen d'écrire efficacement de nombreux fichiers sur des bandes. Même si de nos jours les lecteurs de bande sont inconnus de la grande majorité des utilisateurs individuels de Linux, les archives tar — le surnom de tar archives - sont encore couramment utilisées pour regrouper plusieurs fichiers ou même une arborescence de répertoires entière (ou même des forêts) dans un seul fichier.
Une chose clé à retenir est un tar simple le fichier n'est qu'une archive dont les données ne sont pas compressées. En d'autres termes, si vous goudronnez 100 fichiers de 50ko, vous vous retrouverez avec une archive dont la taille sera d'environ 5000ko. Le seul gain auquel vous pouvez vous attendre en utilisant tar seul serait d'éviter l'espace gaspillé par le système de fichiers, car la plupart d'entre eux allouent de l'espace avec une certaine granularité (par exemple, sur mon système, un fichier d'un octet utilise 4 Ko d'espace disque, 1000 de ils utiliseront 4 Mo mais l'archive tar correspondante "seulement" 1 Mo).
| Cela mérite d'être mentionné ici tar n'est certainement pas le seul outil Unix standard pour créer des archives. Les programmeurs savent probablement ar car il est surtout utilisé aujourd'hui pour créer des bibliothèques statiques, qui ne sont rien de plus que des archives de compilé des dossiers. Mais ar peut être utilisé pour créer des archives de toute sorte. En fait, .deb les fichiers de package utilisés sur les systèmes Debian sont ar les archives! Et sur MacOS X, mpkg les paquets sont (étaient ?) cpio compressés avec gzip les archives. Cela étant dit, ni ar ni cpio a gagné autant de popularité que tar parmi les utilisateurs. Peut-être parce que la commande tar était assez bonne et plus simple à utiliser. |

Créer des archives, c'est bien. Mais au fil du temps, et avec l'avènement de l'ère des ordinateurs personnels, les gens ont réalisé qu'ils pouvaient faire d'énormes économies sur le stockage en compressant Les données. Donc, une décennie après l'introduction ou tar , zip est apparu dans le monde MS-DOS en tant que format d'archive prenant en charge la compression . Le schéma de compression le plus courant pour zip est dégonfler qui est lui-même une implémentation de l'algorithme LZ77. Mais développé commercialement par PKWARE, le zip Le format souffre d'une charge de brevets depuis des années.
Donc, en parallèle, gzip a été créé pour implémenter l'algorithme LZ77 dans un logiciel libre sans casser aucun brevet PKWARE.
Un élément clé de la philosophie Unix étant « Faire une chose et le faire bien » , gzip a été conçu pour uniquement compresser les fichiers. Donc, pour créer une archive compressée , vous devez d'abord créer une archive en utilisant le tar utilitaire par exemple. Et après cela, vous allez compresser ces archives. Ceci est un .tar.gz fichier (parfois abrégé en .tgz pour ajouter encore à cette confusion - et pour se conformer aux limitations de nom de fichier MS-DOS 8.3 oubliées depuis longtemps).
Au fur et à mesure que l'informatique évoluait, d'autres algorithmes de compression ont été conçus pour un taux de compression plus élevé. Par exemple, l'algorithme Burrows–Wheeler implémenté dans bzip2 (menant à .tar.bz2 les archives). Ou plus récemment xz qui est un LZMA implémentation d'un algorithme similaire à celui utilisé dans le 7zip utilitaire.
Disponibilité et limitations
Aujourd'hui, vous pouvez utiliser librement n'importe quel format de fichier d'archive à la fois sur Linux et Windows.
Mais comme le zip est supporté nativement sur Windows, celui-ci est particulièrement présent dans les environnements multiplateformes. Vous pouvez même trouver le zip format de fichier dans des endroits inattendus. Par exemple, ce format de fichier a été retenu par Sun pour JAR archives utilisées pour distribuer des applications Java compilées. Ou pour les fichiers OpenDocument (.odf , .odp …) utilisé par LibreOffice ou d'autres suites bureautiques. Tous ces formats de fichiers sont des archives zip déguisées. Si vous êtes curieux, n'hésitez pas à décompresser l'un d'eux pour voir ce qu'il y a dedans :
sh$ unzip some-file.odt Archive:some-file.odt extracting: mimetype inflating: meta.xml inflating: settings.xml inflating: content.xm [...] inflating: styles.xml inflating: META-INF/manifest.xml
Tout cela étant dit, dans le monde de type Unix, je préférerait toujours tar type d'archive car le zip Le format de fichier ne prend pas en charge toutes les métadonnées du système de fichiers Unix de manière fiable. Pour obtenir des explications concrètes sur cette dernière déclaration, vous devez savoir que le format de fichier ZIP ne définit qu'un petit ensemble d'attributs de fichier obligatoires à stocker pour chaque entrée :nom de fichier, date de modification, autorisations. Au-delà de ces attributs de base, un archiveur peut stocker des métadonnées supplémentaires dans le soi-disant champ supplémentaire de l'en-tête ZIP. Mais, comme des champs supplémentaires sont définis par l'implémentation, il n'y a aucune garantie, même pour les archiveurs conformes, de stocker ou de récupérer le même ensemble de métadonnées. Vérifions cela sur un exemple d'archive :
sh$ ls -lsn data/team total 0 0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team Central directory entry #5: --------------------------- data/team [...] apparent file type: binary Unix file attributes (100644 octal): -rw-r--r-- MS-DOS file attributes (00 hex): none The central-directory extra field contains: - A subfield with ID 0x5455 (universal time) and 5 data bytes. The local extra field has UTC/GMT modification/access times. - A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes: 01 04 e8 03 00 00 04 d0 07 00 00.
Comme vous pouvez le voir, les informations de propriété (UID/GID) font partie du champ supplémentaire. Cela peut ne pas être évident si vous ne connaissez pas l'hexadécimal, ni les métadonnées ZIP. sont stockés little-endian, mais pour faire court "e803" est "03e8" avec "1000", l'UID du fichier. Et "07d0" est "d007" qui est 2000, le fichier GID.
Dans ce cas particulier, le zip Info-ZIP L'outil disponible sur mon système Debian a stocké des métadonnées utiles dans le champ supplémentaire. Mais il n'y a aucune garantie que ce champ supplémentaire soit écrit par chaque archiveur. Et même s'il est présent, il n'y a aucune garantie que cela soit compris par l'outil utilisé pour extraire l'archive.
Alors que nous ne pouvons pas rejeter la tradition comme motivation pour continuer à utiliser les archives tar , avec ce petit exemple, vous comprenez pourquoi il y a encore des cas (de coin ?) où tar ne peut pas être remplacé par zip . Cela est particulièrement vrai lorsque vous souhaitez conserver tout métadonnées de fichier standard.
Test d'efficacité Tar vs Zip vs Gz
Je parlerai ici d'efficacité spatiale, pas d'efficacité temporelle, mais en règle générale, plus un algorithme de compression est potentiellement efficace, plus il nécessite de CPU.
Et pour vous donner une idée du taux de compression obtenu en utilisant différents algorithmes, j'ai rassemblé sur mon disque dur environ 100 Mo de fichiers de formats de fichiers populaires. Voici le résultat obtenu sur mon système Debian Stretch (toutes tailles tel que rapporté par du -sh ):
| type de fichier | .jpg | .mp3 | .mp4 | .odt | .png | .txt |
| nombre de fichiers | 2163 | 45 | 279 | 2 990 | 2072 | 4397 |
| espace sur le disque | 98M | 99M | 99M | 98M | 98M | 98M |
| tar | 94M | 99M | 98 M | 93 M | 92M | 89M |
| zip (pas de compression) | 92M | 99M | 98 M | 91M | 91M | 86 M |
| zip (dégonfler) | 87 M | 98 M | 93 M | 85 M | 77 M | 28 M |
| tar + gzip | 86 M | 98 M | 93 M | 82 M | 77 M | 27 M |
| tar + bz2 | 87 M | 98 M | 93 M | 42 M | 71M | 22 M |
| tar + xz | 70 M | 98 M | 22 M | 348 Ko | 51M | 19 M |
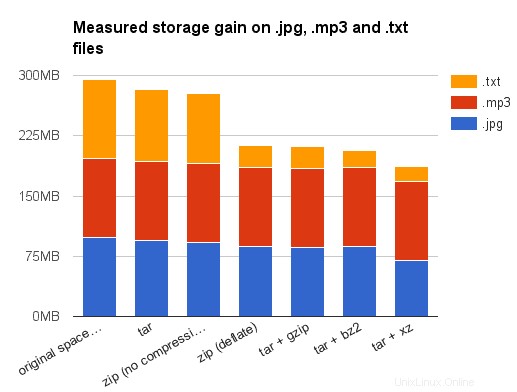 Tout d'abord, je vous encourage à prendre ces résultats avec un énorme grain de sel :les fichiers de données étaient en fait des fichiers suspendus sur mon disque dur, et je ne prétendrais en aucun cas qu'ils soient représentatifs. Ensuite, je dois avouer que je n'ai pas choisi ces types de fichiers au hasard. Je l'ai déjà dit, .odt les fichiers sont déjà des fichiers zip. Donc le gain modeste obtenu en les compressant une deuxième fois n'est pas surprenant (sauf pour bzip2 ou xy, mais je le ferais considérer cela comme une anomalie statistique causée par la faible hétérogénéité de mes fichiers de données — contenant plusieurs sauvegardes ou versions de travail des mêmes documents).
Tout d'abord, je vous encourage à prendre ces résultats avec un énorme grain de sel :les fichiers de données étaient en fait des fichiers suspendus sur mon disque dur, et je ne prétendrais en aucun cas qu'ils soient représentatifs. Ensuite, je dois avouer que je n'ai pas choisi ces types de fichiers au hasard. Je l'ai déjà dit, .odt les fichiers sont déjà des fichiers zip. Donc le gain modeste obtenu en les compressant une deuxième fois n'est pas surprenant (sauf pour bzip2 ou xy, mais je le ferais considérer cela comme une anomalie statistique causée par la faible hétérogénéité de mes fichiers de données — contenant plusieurs sauvegardes ou versions de travail des mêmes documents).
Concernant .jpg , .mp3 et .mp4 maintenant :peut-être savez-vous que ce sont déjà fichier de données compressé. Mieux encore, vous avez peut-être entendu dire qu'ils utilisent la compression destructive . Cela signifie que vous ne pouvez pas reconstruire exactement l'image d'origine après une compression JPEG. Et c'est vrai. Mais ce qui est peu connu, c'est après la phase de compression destructive en soi , les données sont compressées une deuxième fois à l'aide de l'algorithme non destructif de longueur de mot variable de Huffman pour supprimer la redondance des données.
Pour toutes ces raisons, on s'attendait à ce que la compression d'images JPEG ou de fichiers MP3/MP4 ne permette pas des gains élevés. Veuillez noter qu'un fichier typique contient à la fois des données hautement compressées et des métadonnées non compressées, nous pouvons toujours y gagner un petit quelque chose. Cela explique pourquoi j'ai toujours un gain notable pour les images JPEG car j'en avais beaucoup - donc la taille globale des métadonnées n'était pas si négligeable par rapport à la taille totale du fichier. Encore une fois, les résultats surprenants lors de la compression de fichiers MP4 en utilisant xz sont probablement liés aux fortes similitudes entre les différents fichiers MP4 utilisés lors de mes tests. Ou ne le sont-ils pas ?
Pour éventuellement lever ces doutes, je vous encourage fortement à faire vos propres comparaisons. Et n'hésitez pas à partager vos observations avec nous en utilisant la section des commentaires ci-dessous !