Kubernetes est une plate-forme open source de gestion des charges de travail et des services conteneurisés qui facilite la configuration et l'automatisation déclaratives. Le nom Kubernetes vient du grec, signifiant timonier ou pilote. Il est portable et extensible et possède un écosystème en croissance rapide. Les services et outils de Kubernetes sont largement disponibles.
Dans cet article, nous passerons en revue une vue de 10 000 pieds des principaux composants de Kubernetes, de la composition de chaque conteneur à la façon dont un conteneur dans un pod est déployé et planifié sur chacun des travailleurs. Il est crucial de comprendre tous les détails du cluster Kubernetes afin de pouvoir déployer et concevoir une solution basée sur Kubernetes en tant qu'orchestrateur pour les applications conteneurisées.
Voici un bref aperçu des choses que nous allons couvrir dans cet article :
- Composants du panneau de configuration
- Composants du nœud de calcul Kubernetes
- Pods en tant que blocs de construction de base
- Services Kubernetes, équilibreurs de charge et contrôleurs Ingress
- Déploiements Kubernetes et ensembles de démons
- Stockage persistant dans Kubernetes
Le plan de contrôle Kubernetes
Les nœuds maîtres Kubernetes sont l'endroit où résident les principaux services du plan de contrôle ; tous les services ne doivent pas nécessairement résider sur le même nœud ; cependant, pour la centralisation et l'aspect pratique, ils sont souvent déployés de cette façon. Cela pose évidemment des questions de disponibilité des services; cependant, ils peuvent facilement être surmontés en ayant plusieurs nœuds et en fournissant des requêtes d'équilibrage de charge pour obtenir un ensemble hautement disponible de nœuds maîtres .
Les nœuds maîtres sont composés de quatre services de base :
- Le kube-apiserver
- Le planificateur kube
- Le kube-controller-manager
- La base de données etcd
Les nœuds maîtres peuvent s'exécuter sur des serveurs bare metal, des machines virtuelles ou un cloud privé ou public, mais il n'est pas recommandé d'y exécuter des charges de travail de conteneur. Nous verrons plus à ce sujet plus tard.
Le schéma suivant montre les composants des nœuds maîtres Kubernetes :
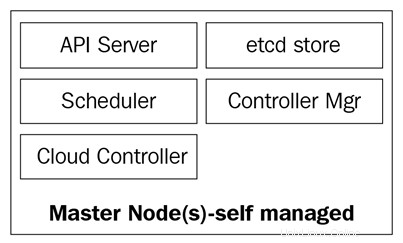
Le serveur kube-api
Le serveur d'API est ce qui lie tout ensemble. C'est l'API REST frontale du cluster qui reçoit les manifestes pour créer, mettre à jour et supprimer des objets d'API tels que des services, des pods, Ingress et autres.
Le kube-apiserver est le seul service auquel nous devrions parler ; c'est également le seul qui écrit et communique avec la base de données etcd pour enregistrer l'état du cluster. Avec la commande kubectl , nous enverrons des commandes pour interagir avec elle. Ce sera notre couteau suisse en matière de Kubernetes.
Le gestionnaire de kube-controller
Le démon kube-controller-manager, en un mot, est un ensemble de boucles de contrôle infinies qui sont livrées pour plus de simplicité dans un seul binaire. Il surveille l'état souhaité défini du cluster et s'assure qu'il est accompli et satisfait en déplaçant tous les éléments nécessaires pour y parvenir. Le kube-controller-manager n'est pas qu'un seul contrôleur ; il contient plusieurs boucles différentes qui surveillent différents composants du cluster. Certains d'entre eux sont le contrôleur de service, le contrôleur d'espace de noms, le contrôleur de compte de service et bien d'autres. Vous pouvez trouver chaque contrôleur et sa définition dans le référentiel Kubernetes GitHub :https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
Le planificateur kube
Le kube-scheduler planifie vos pods nouvellement créés sur des nœuds avec suffisamment d'espace pour satisfaire les besoins en ressources des pods. Il écoute essentiellement le kube-apiserver et le kube-controller-manager pour les pods nouvellement créés qui sont placés dans une file d'attente puis programmés sur un nœud disponible par le planificateur. La définition de kube-scheduler peut être trouvée ici :https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Outre les ressources de calcul, le kube-scheduler lit également les règles d'affinité et d'anti-affinité des nœuds pour savoir si un nœud peut ou non exécuter ce pod.
La base de données etcd
La base de données etcd est un magasin clé-valeur cohérent très fiable qui est utilisé pour stocker l'état du cluster Kubernetes. Il contient l'état actuel des pods sur lesquels le nœud s'exécute, le nombre de nœuds actuellement présents dans le cluster, l'état de ces nœuds, le nombre de répliques de déploiement en cours d'exécution, les noms des services, etc.
Comme nous l'avons mentionné précédemment, seul le kube-apiserver communique avec la base de données etcd. Si le kube-controller-manager doit vérifier l'état du cluster, il passera par le serveur d'API afin d'obtenir l'état de la base de données etcd, au lieu d'interroger directement le magasin etcd. La même chose se produit avec le kube-scheduler si le planificateur doit faire savoir qu'un pod a été arrêté ou alloué à un autre nœud ; il informera le serveur API, et le serveur API stockera l'état actuel dans la base de données etcd.
Avec etcd, nous avons couvert tous les composants principaux de nos nœuds maîtres Kubernetes afin que nous soyons prêts à gérer notre cluster. Mais un cluster n'est pas uniquement composé de maîtres; nous avons toujours besoin des nœuds qui effectueront le gros du travail en exécutant nos applications.
Nœuds de travail Kubernetes
Les nœuds de travail qui effectuent cette tâche dans Kubernetes sont simplement appelés nœuds. Auparavant, vers 2014, on les appelait des sbires, mais ce terme a ensuite été remplacé par de simples nœuds, car le nom prêtait à confusion avec la terminologie de Salt et faisait penser que Salt jouait un rôle majeur dans Kubernetes.
Ces nœuds sont le seul endroit où vous exécuterez des charges de travail, car il n'est pas recommandé d'avoir des conteneurs ou des charges sur les nœuds maîtres, car ils doivent être disponibles pour gérer l'ensemble du cluster. Les nœuds sont très simples en termes de composants; ils n'ont besoin que de trois services pour remplir leur tâche :
- Kubelet
- Kube-proxy
- Exécution du conteneur
Explorons ces trois composants un peu plus en profondeur.
Le kubelet
Le kubelet est un composant Kubernetes de bas niveau et l'un des plus importants après le kube-apiserver ; ces deux composants sont essentiels pour le provisionnement des pods/conteneurs dans le cluster. Le kubelet est un service qui s'exécute sur les nœuds Kubernetes et écoute le serveur d'API pour la création de pod. Le kubelet est uniquement chargé de démarrer/arrêter et de s'assurer que les conteneurs dans les dosettes sont sains ; le kubelet ne pourra pas gérer les conteneurs qui n'ont pas été créés par lui.
Le kubelet atteint les objectifs en communiquant avec l'environnement d'exécution du conteneur via l'interface d'exécution du conteneur (CRI) . Le CRI fournit une connectabilité au kubelet via un client gRPC, qui est capable de parler à différents runtimes de conteneurs. Comme nous l'avons mentionné précédemment, Kubernetes prend en charge plusieurs environnements d'exécution de conteneurs pour déployer des conteneurs, et c'est ainsi qu'il parvient à une prise en charge aussi diversifiée pour différents moteurs.
Vous pouvez vérifier le code source de kubelet via https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
Le proxy kube
Le kube-proxy est un service qui réside sur chaque nœud du cluster et qui rend possible les communications entre les pods, les conteneurs et les nœuds. Ce service surveille le kube-apiserver pour détecter les modifications apportées aux services définis (le service est une sorte d'équilibreur de charge logique dans Kubernetes ; nous approfondirons les services plus tard dans cet article) et maintient le réseau à jour via des règles iptables qui transfèrent le trafic vers les bons points de terminaison. Kube-proxy définit également des règles dans iptables qui effectuent un équilibrage de charge aléatoire entre les pods derrière un service.
Voici un exemple de règle iptables créée par le proxy kube :
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment --comment "default/example:has no endpoints" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
Notez qu'il s'agit d'un service sans points de terminaison (pas de pods derrière).
Exécution du conteneur
Pour pouvoir lancer des conteneurs, nous avons besoin d'un environnement d'exécution de conteneur . Il s'agit du moteur de base qui créera les conteneurs dans le noyau des nœuds pour que nos pods s'exécutent. Le kubelet parlera à ce runtime et lancera ou arrêtera nos conteneurs à la demande.
Actuellement, Kubernetes prend en charge tous les environnements d'exécution de conteneurs compatibles OCI, tels que Docker, rkt, runc, runsc, etc.
Vous pouvez consulter ce https://github.com/opencontainers/runtime-spec pour en savoir plus sur toutes les spécifications de la page OCI Git-Hub.
Maintenant que nous avons exploré tous les composants de base qui forment un cluster, examinons maintenant ce qui peut être fait avec eux et comment Kubernetes va nous aider à orchestrer et gérer nos applications conteneurisées.
Objets Kubernetes
Les objets Kubernetes sont exactement cela :ce sont des objets ou des abstractions persistants logiques qui représenteront l'état de votre cluster. Vous êtes chargé de dire à Kubernetes quel est l'état souhaité de cet objet afin qu'il puisse travailler pour le maintenir et s'assurer que l'objet existe.
Pour créer un objet, il doit avoir deux choses :un statut et sa spécification. Le statut est fourni par Kubernetes et correspond à l'état actuel de l'objet. Kubernetes gérera et mettra à jour ce statut selon les besoins pour être conforme à l'état souhaité. Le champ de spécification, en revanche, est ce que vous fournissez à Kubernetes et ce que vous lui dites pour décrire l'objet que vous désirez. Par exemple, l'image que vous souhaitez que le conteneur exécute, le nombre de conteneurs de cette image que vous souhaitez exécuter, etc.
Chaque objet a des champs de spécification spécifiques pour le type de tâche qu'il exécute, et vous fournirez ces spécifications sur un fichier YAML qui est envoyé au kube-apiserver avec kubectl, qui le transforme en JSON et l'envoie en tant que requête API . Nous approfondirons chaque objet et ses champs de spécification plus loin dans cet article.
Voici un exemple de fichier YAML envoyé à kubectl :
chat <
Les champs de base de la définition d'objet sont les tout premiers, et ceux-ci ne varient pas d'un objet à l'autre et sont très explicites. Examinons-les rapidement :
Nous avons donc parcouru les champs les plus utilisés et leur contenu ; vous pouvez en savoir plus sur les conventions de l'API Kuberntes sur https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Certains des champs de l'objet peuvent être modifiés ultérieurement après la création de l'objet, mais cela dépendra de l'objet et du champ que vous souhaitez modifier.
Voici une courte liste des différents objets Kubernetes que vous pouvez créer :
Et il y en a bien d'autres.
Examinons de plus près chacun de ces éléments.
Les pods sont les objets les plus basiques de Kubernetes et aussi les plus importants. Tout tourne autour d'eux; on peut dire que Kubernetes c'est pour les pods ! Tous les autres objets sont là pour les servir, et toutes les tâches qu'ils accomplissent consistent à faire en sorte que les pods atteignent l'état souhaité.
Alors, qu'est-ce qu'un pod et pourquoi les pods sont-ils si importants ?
Un pod est un objet logique qui exécute un ou plusieurs conteneurs ensemble sur le même espace de noms réseau, la même communication inter-processus (IPC) et, parfois, selon la version de Kubernetes, le même ID de processus (PID) espace de noms. En effet, ce sont eux qui vont gérer nos conteneurs et seront donc au centre de l'attention. L'intérêt de Kubernetes est d'être un orchestrateur de conteneurs, et avec les pods, nous rendons l'orchestration possible.
Comme nous l'avons mentionné précédemment, les conteneurs d'un même pod vivent dans une "bulle" où ils peuvent se parler via localhost, car ils sont locaux les uns par rapport aux autres. Un conteneur dans un pod a la même adresse IP que l'autre conteneur car ils partagent un espace de noms réseau, mais dans la plupart des cas, vous fonctionnerez sur une base individuelle, c'est-à-dire un seul conteneur par pod . Plusieurs conteneurs par pod ne sont utilisés que dans des scénarios très spécifiques, par exemple lorsqu'une application nécessite un assistant tel qu'un pousseur de données ou un proxy qui doit communiquer de manière rapide et résiliente avec l'application principale.
La façon dont vous définissez un pod est la même que vous le feriez pour n'importe quel autre objet Kubernetes :via un YAML qui contient toutes les spécifications et définitions du pod :
kind :PodapiVersion :v1metadata:name :hello-podlabels : hello:podspec: containers: - name :hello-container image :alpine args : - echo - "Hello World"
Passons en revue les définitions de pod de base nécessaires dans le champ spec pour créer notre pod :
Ce sont les spécifications les plus élémentaires que vous allez déclarer sur un pod ; d'autres spécifications nécessiteront que vous ayez un peu plus de connaissances de base sur la façon de les utiliser et sur la façon dont elles interagissent avec divers autres objets Kubernetes. Nous les reviendrons plus loin dans cet article; certains d'entre eux sont les suivants :
Pour afficher les pods en cours d'exécution dans votre cluster, vous pouvez exécuter kubectl get pods :
[email protected] : $ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
Vous pouvez également exécuter des pods de description kubectl sans spécifier de pod. Cela imprimera une description de chaque pod en cours d'exécution dans le cluster. Dans ce cas, il s'agira uniquement du pod busybox, car c'est le seul en cours d'exécution :
[Protégé par e-mail]:~ $ kubectl décrire podSname:busyboxNamespace:defaultPriority:0PriorityClassName:
Les gousses sont mortelles. Une fois qu'il meurt ou est supprimé, ils ne peuvent pas être récupérés. Son adresse IP et les conteneurs qui y étaient exécutés auront disparu ; ils sont totalement éphémères. Les données sur les pods montés en tant que volume peuvent survivre ou non, selon la façon dont vous les configurez. Si nos pods meurent et que nous les perdons, comment nous assurer que tous nos microservices fonctionnent ? Eh bien, les déploiements sont la solution.
Les pods en eux-mêmes ne sont pas très utiles car il n'est pas très efficace d'avoir plus d'une seule instance de notre application en cours d'exécution dans un seul pod. Provisionner des centaines de copies de notre application sur différents pods sans avoir de méthode pour les rechercher tous deviendra très rapidement incontrôlable.
C'est là que les déploiements entrent en jeu. Avec les déploiements, nous pouvons gérer nos pods avec un contrôleur. Cela nous permet non seulement de décider combien nous voulons exécuter, mais nous pouvons également gérer les mises à jour en modifiant la version de l'image ou l'image elle-même que nos conteneurs exécutent. Les déploiements sont ce avec quoi vous travaillerez la plupart du temps. Avec les déploiements ainsi que les pods et tous les autres objets que nous avons mentionnés précédemment, ils ont leur propre définition dans un fichier YAML :
apiVersion :apps/v1kind :Deploymentmetadata :nom :nginx-deployment labels : déploiement :nginxspec :répliques :3 sélecteur : matchLabels : app :nginx template : metadata : labels : app :nginx spec : containers : - name :nginx image :nginx :1.7.9 ports : - conteneurPort :80
Commençons à explorer leur définition.
Au début du YAML, nous avons des champs plus généraux, tels que apiVersion, kind et metadata. Mais sous spécifications, nous trouverons les options spécifiques pour cet objet API.
Sous spec, nous pouvons ajouter les champs suivants :
Sélecteur :Avec le champ Sélecteur, le déploiement saura quels pods cibler lorsque les modifications seront appliquées. Vous utiliserez deux champs sous le sélecteur : matchLabels et matchExpressions. Avec matchLabels, le sélecteur utilisera les libellés des pods (paires clé/valeur). Il est important de noter que tous les libellés que vous spécifiez ici seront associés AND. Cela signifie que le pod devra disposer de toutes les étiquettes que vous spécifiez sous matchLabels.
Répliques :cela indiquera le nombre de pods dont le déploiement a besoin pour continuer à fonctionner via le contrôleur de réplication ; par exemple, si vous spécifiez trois répliques et que l'un des pods meurt, le contrôleur de réplication observera la spécification des répliques comme l'état souhaité et informera le planificateur de planifier un nouveau pod, car l'état actuel est maintenant 2 depuis que le pod est mort.
RevisionHistoryLimit :chaque fois que vous apportez une modification au déploiement, cette modification est enregistrée en tant que révision du déploiement, que vous pouvez ensuite rétablir à cet état précédent ou conserver un enregistrement de ce qui a été modifié. Vous pouvez consulter votre historique avec kubectl déploiement de l'historique de déploiement/
Stratégie :Cela vous permettra de décider comment vous souhaitez gérer toute mise à jour ou mise à l'échelle horizontale des modules. Pour écraser la valeur par défaut, qui est rollingUpdate, vous devez écrire la clé de type, où vous pouvez choisir entre deux valeurs : recreate ou rollingUpdate.
Bien que la recréation soit un moyen rapide de mettre à jour votre déploiement, elle supprimera tous les pods et les remplacera par de nouveaux, mais cela impliquera que vous devrez tenir compte du fait qu'un temps d'arrêt du système sera en place pour ce type de stratégie. RollingUpdate, en revanche, est plus fluide et plus lent et est idéal pour les applications avec état qui peuvent rééquilibrer leurs données. La rollingUpdate ouvre la porte à deux autres champs, qui sont maxSurge et maxUnavailable.
Le premier sera le nombre de pods au-dessus du montant total que vous souhaitez lors d'une mise à jour ; par exemple, un déploiement avec 100 pods et un maxSurge de 20 % augmentera jusqu'à un maximum de 120 pods lors de la mise à jour. L'option suivante vous permettra de sélectionner le nombre de pods dans le pourcentage que vous êtes prêt à tuer afin de les remplacer par de nouveaux dans un scénario de 100 pods. Dans les cas où il y a 20 % d'indisponibilité maximale, seuls 20 pods seront supprimés et remplacés par de nouveaux avant de continuer à remplacer le reste du déploiement.
Modèle :Il s'agit simplement d'un champ de spécification de pod imbriqué dans lequel vous incluez toutes les spécifications et métadonnées des pods que le déploiement va gérer.
Nous avons vu qu'avec les déploiements, nous gérons nos pods, et ils nous aident à les maintenir dans l'état que nous désirons. Tous ces pods sont toujours dans quelque chose appelé le cluster réseau , qui est un réseau fermé dans lequel seuls les composants du cluster Kubernetes peuvent communiquer entre eux, même avec leur propre ensemble de plages d'adresses IP. Comment parlons-nous à nos pods de l'extérieur ? Comment accède-t-on à notre candidature ? C'est là que les services entrent en jeu.
Services :
Le nom service ne décrit pas complètement ce que les services font réellement dans Kubernetes. Les services Kubernetes acheminent le trafic vers nos pods. Nous pouvons dire que les services sont ce qui lie les pods ensemble.
Imaginons que nous ayons une application typique de type frontend/backend où nos pods frontend communiquent avec nos backend via les adresses IP des pods. Si un pod du backend meurt, nous perdons la communication avec notre backend. Ce n'est pas seulement parce que le nouveau pod n'aura pas la même adresse IP que le pod qui est mort, mais maintenant nous devons également reconfigurer notre application pour utiliser la nouvelle adresse IP. Ce problème et des problèmes similaires sont résolus avec les services.
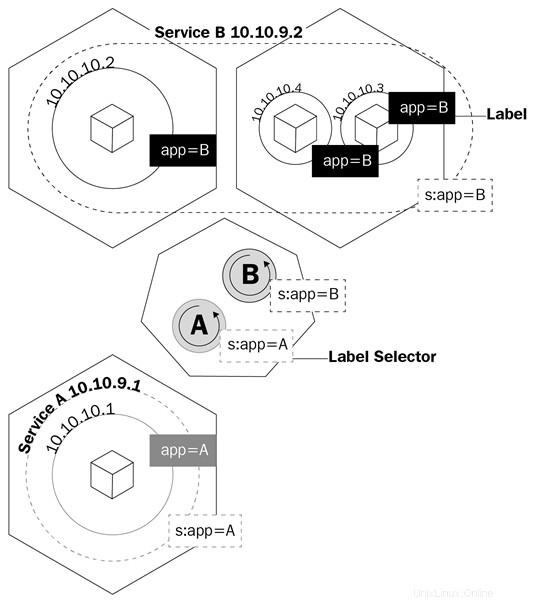
Un service est un objet logique qui indique au proxy kube de créer des règles iptables en fonction des pods qui se trouvent derrière le service. Les services configurent leurs points de terminaison, c'est-à-dire comment les pods derrière un service sont appelés, de la même manière que les déploiements savent quels pods contrôler, le champ de sélection et les étiquettes des pods.
Ce diagramme vous montre comment les services utilisent les libellés pour gérer le trafic :
Les services ne feront pas que créer des règles à kube-proxy pour acheminer le trafic ; cela déclenchera également quelque chose appelé kube-dns.
Kube-dns est un ensemble de pods avec des conteneurs SkyDNS qui s'exécutent sur le cluster qui fournit un serveur DNS et un redirecteur, qui créera des enregistrements pour les services et parfois des pods pour une utilisation facile. Chaque fois que vous créez un service, un enregistrement DNS pointant vers l'adresse IP interne du cluster du service est créé sous la forme service-name.namespace.svc.cluster.local. Vous pouvez en savoir plus sur les spécifications DNS de Kubernetes ici : https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Pour en revenir à notre exemple, nous n'aurons plus qu'à configurer notre application pour parler au service nom de domaine complet (FQDN) afin de parler à nos pods backend. De cette façon, peu importe l'adresse IP des pods et des services. Si un pod derrière le service meurt, le service s'occupera de tout en utilisant l'enregistrement A, car nous pourrons dire à notre interface d'acheminer tout le trafic vers my-svc. La logique du service s'occupera de tout le reste.
Il existe plusieurs types de service que vous pouvez créer chaque fois que vous déclarez l'objet à créer dans Kubernetes. Passons en revue pour voir lequel sera le mieux adapté au type de travail dont nous avons besoin :
IP de cluster :Il s'agit du service par défaut. Chaque fois que vous créez un service ClusterIP, il crée un service avec une adresse IP interne au cluster qui ne sera routable qu'à l'intérieur du cluster Kubernetes. Ce type est idéal pour les pods qui n'ont besoin que de se parler et de ne pas sortir du cluster.
NodePort :lorsque vous créez ce type de service, par défaut, un port aléatoire compris entre 30000 et 32767 sera alloué pour transférer le trafic vers les pods de point de terminaison du service. Vous pouvez ignorer ce comportement en spécifiant un port de nœud dans le tableau des ports. Une fois cela défini, vous pourrez accéder à vos pods via
Équilibreur de charge :La plupart du temps, vous exécuterez Kubernetes sur un fournisseur de cloud. Le type LoadBalancer est idéal pour ces situations, car vous pourrez allouer des adresses IP publiques à votre service via l'API de votre fournisseur de cloud. C'est le service idéal lorsque vous souhaitez communiquer avec vos pods depuis l'extérieur de votre cluster. Avec LoadBalancer, vous pourrez non seulement allouer une adresse IP publique mais également, à l'aide d'Azure, allouer une adresse IP privée depuis votre réseau privé virtuel. Ainsi, vous pouvez parler à vos pods depuis Internet ou en interne sur votre sous-réseau privé.
Passons en revue la définition YAML d'un service :
apiVersion :v1kind :Servicemetadata : name :my-servicespec:selector : app :front-end type :NodePort ports : - name :http port :80 targetPort :8080 nodePort :30024 protocol :TCP
Le YAML d'un service est très simple et les spécifications varient en fonction du type de service que vous créez. Mais la chose la plus importante que vous devez prendre en compte, ce sont les définitions de port. Jetons un coup d'œil à ceux-ci :
Bien que nous comprenions maintenant comment nous pouvons communiquer avec les pods de notre cluster, nous devons encore comprendre comment nous allons gérer le problème de la perte de nos données chaque fois qu'un pod est arrêté. C'est là que Persistent Volumes (VP ) vient à être utilisé.
Le stockage persistant dans le monde des conteneurs est un problème sérieux. Le seul stockage persistant d'une exécution à l'autre du conteneur est constitué par les couches de l'image, et elles sont en lecture seule. La couche sur laquelle le conteneur s'exécute est en lecture/écriture, mais toutes les données de cette couche sont supprimées une fois le conteneur arrêté. Avec les gousses, c'est pareil. Lorsqu'un conteneur meurt, les données qui y sont écrites ont disparu.
Kubernetes dispose d'un ensemble d'objets pour gérer le stockage entre les pods. Le premier dont nous parlerons est celui des volumes.
Les volumes résolvent l'un des plus gros problèmes en matière de stockage persistant. Tout d'abord, les volumes ne sont pas réellement des objets, mais une définition de la spécification d'un pod. Lorsque vous créez un pod, vous pouvez définir un volume dans le champ spec du pod. Les conteneurs de ce pod pourront monter le volume sur leur espace de noms de montage, et le volume sera disponible lors des redémarrages ou des plantages du conteneur. Les volumes sont liés aux pods, cependant, et si le pod est supprimé, le volume disparaîtra également. Les données sur le volume sont une autre histoire; la persistance des données dépendra du backend de ce volume.
Kubernetes prend en charge plusieurs types de volumes ou de sources de volumes et la façon dont ils sont appelés dans les spécifications de l'API, qui vont des cartes de système de fichiers du nœud local, des disques virtuels des fournisseurs de cloud et des volumes basés sur le stockage défini par logiciel. Les montages de systèmes de fichiers locaux sont les plus courants que vous verrez lorsqu'il s'agit de volumes réguliers. Il est important de noter que l'inconvénient d'utiliser le système de fichiers de nœud local est que les données ne seront pas disponibles sur tous les nœuds du cluster, et uniquement sur le nœud où le pod a été planifié.
Examinons comment un pod avec un volume est défini dans YAML :
apiVersion :v1kind :Podmetadata :nom :test-pdspec :conteneurs :- image :k8s.gcr.io/test-webserver nom :test-container volumeMounts : - mountPath :/test-pd nom :test-volume volumes :- nom :test-volume hostPath : chemin :/data type :Directory
Notez qu'il existe un champ appelé volumes sous spec et qu'il y en a un autre appelé volumeMounts.
Le premier champ (volumes) est l'endroit où vous définissez le volume que vous souhaitez créer pour ce pod. Ce champ nécessitera toujours un nom, puis une source de volume. Selon la source, les exigences seront différentes. Dans cet exemple, la source serait hostPath, qui est le système de fichiers local d'un nœud. hostPath prend en charge plusieurs types de mappages, allant des répertoires, des fichiers, des périphériques de bloc et même des sockets Unix.
Sous le deuxième champ, volumeMounts, nous avons mountPath, où vous définissez le chemin à l'intérieur du conteneur sur lequel vous souhaitez monter votre volume. Le paramètre de nom est la manière dont vous spécifiez au pod le volume à utiliser. Ceci est important car vous pouvez avoir plusieurs types de volumes définis sous volumes, et le nom sera le seul moyen pour le pod de savoir lequel
Vous pouvez en savoir plus sur les différents types de volumes ici https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes et dans le document de référence de l'API Kubernetes (https://kubernetes.io/docs /reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Faire mourir des volumes avec les gousses n'est pas idéal. Nous avons besoin d'un stockage qui persiste, et c'est ainsi qu'est né le besoin de PV.
La principale différence entre les volumes et les PV est que, contrairement aux volumes, les PV sont en fait des objets d'API Kubernetes. Vous pouvez donc les gérer individuellement comme des entités distinctes. Par conséquent, ils persistent même après la suppression d'un pod.
Vous vous demandez peut-être pourquoi cette sous-section a PV, persistant volume revendications (PVC ), et des classes de stockage toutes mélangées. En effet, elles dépendent toutes les unes des autres, et il est crucial de comprendre comment elles interagissent entre elles pour provisionner le stockage pour nos pods.
Let's begin with PVs and PVCs. Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
Pods – la base de Kubernetes
Déploiements
Kubernetes et le stockage persistant
Volumes
Volumes persistants, revendications de volume persistant et classes de stockage