L'analyse médico-légale d'une image disque Linux fait souvent partie de la réponse aux incidents pour déterminer si une violation s'est produite. La criminalistique Linux est un monde différent et fascinant par rapport à la criminalistique Microsoft Windows. Dans cet article, j'analyserai une image disque d'un système Linux potentiellement compromis afin de déterminer qui, quoi, quand, où, pourquoi et comment de l'incident et de créer des chronologies d'événements et de systèmes de fichiers. Enfin, je vais extraire les artefacts intéressants de l'image disque.
Dans ce didacticiel, nous utiliserons de nouveaux outils et d'anciens outils pour créer de nouvelles façons créatives d'effectuer une analyse médico-légale d'une image disque.
Le scénario
Plus de ressources Linux
- Aide-mémoire des commandes Linux
- Aide-mémoire des commandes Linux avancées
- Cours en ligne gratuit :Présentation technique de RHEL
- Aide-mémoire sur le réseau Linux
- Aide-mémoire SELinux
- Aide-mémoire sur les commandes courantes de Linux
- Que sont les conteneurs Linux ?
- Nos derniers articles Linux
Premiere Fabrication Engineering (PFE) soupçonne qu'il y a eu un incident ou un compromis impliquant le serveur principal de l'entreprise nommé pfe1. Ils pensent que le serveur a peut-être été impliqué dans un incident et a pu être compromis entre le premier mars et le dernier mars. Ils ont engagé mes services en tant qu'examinateur médico-légal pour enquêter si le serveur a été compromis et impliqué dans un incident. L'enquête déterminera qui, quoi, quand, où, pourquoi et comment derrière la possible compromission. De plus, PFE a demandé mes recommandations pour d'autres mesures de sécurité pour leurs serveurs.
L'image disque
Pour effectuer l'analyse médico-légale du serveur, je demande à PFE de m'envoyer une image disque médico-légale de pfe1 sur une clé USB. Ils sont d'accord et disent, "l'USB est dans le courrier." La clé USB arrive et je commence à examiner son contenu. Pour effectuer l'analyse médico-légale, j'utilise une machine virtuelle (VM) exécutant la distribution SANS SIFT. La station de travail SIFT est un groupe d'outils gratuits et open source de réponse aux incidents et d'outils médico-légaux conçus pour effectuer des examens médico-légaux numériques détaillés dans une variété de contextes. SIFT dispose d'un large éventail d'outils médico-légaux, et s'il n'a pas d'outil que je veux, je peux en installer un sans trop de difficulté car il s'agit d'une distribution basée sur Ubuntu.
Après examen, je trouve que l'USB ne contient pas d'image disque, mais plutôt des copies des fichiers hôtes VMware ESX, qui sont des fichiers VMDK du cloud hybride de PFE. Ce n'était pas ce à quoi je m'attendais. J'ai plusieurs options :
- Je peux contacter PFE et être plus explicite sur ce que j'attends d'eux. Au début d'un engagement comme celui-ci, ce n'est peut-être pas la meilleure chose à faire.
- Je peux charger les fichiers VMDK dans un outil de virtualisation tel que VMPlayer et l'exécuter en tant que machine virtuelle en direct à l'aide de ses programmes Linux natifs pour effectuer une analyse médico-légale. Il y a au moins trois raisons de ne pas le faire. Tout d'abord, les horodatages des fichiers et du contenu des fichiers seront modifiés lors de l'exécution des fichiers VMDK en tant que système en direct. Deuxièmement, étant donné que le serveur est considéré comme compromis, chaque fichier et programme des systèmes de fichiers VMDK doit être considéré comme compromis. Troisièmement, l'utilisation des programmes natifs sur un système compromis pour effectuer une analyse médico-légale peut avoir des conséquences imprévues.
- Pour analyser les fichiers VMDK, je pourrais utiliser le package libvmdk-utils qui contient des outils pour accéder aux données stockées dans les fichiers VMDK.
- Cependant, une meilleure approche consiste à convertir le format de fichier VMDK au format RAW. Cela facilitera l'exécution des différents outils de la distribution SIFT sur les fichiers de l'image disque.
Pour convertir du format VMDK au format RAW, j'utilise l'utilitaire qemu-img, qui permet de créer, convertir et modifier des images hors ligne. La figure suivante montre la commande pour convertir le format VMDK en format RAW.

Ensuite, je dois répertorier la table de partition à partir de l'image disque et obtenir des informations sur le début de chaque partition (secteurs) à l'aide de l'utilitaire mmls. Cet utilitaire affiche la disposition des partitions dans un système de volume, y compris les tables de partition et les étiquettes de disque. Ensuite, j'utilise le secteur de départ et interroge les détails associés au système de fichiers à l'aide de l'utilitaire fsstat, qui affiche les détails associés à un système de fichiers. Les figures ci-dessous montrent les mmls et fsstat commandes en cours d'exécution.
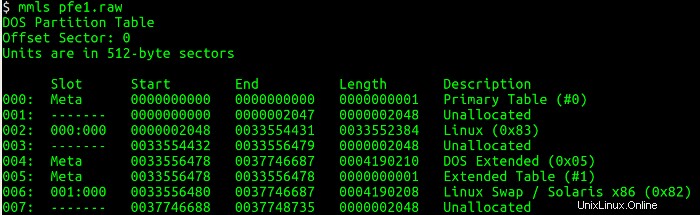
J'apprends plusieurs choses intéressantes grâce au mmls sortie :une partition principale Linux commence au secteur 2048 et a une taille d'environ 8 gigaoctets. Une partition DOS, probablement la partition de démarrage, a une taille d'environ 8 mégaoctets. Enfin, il y a une partition swap d'environ 8 gigaoctets.
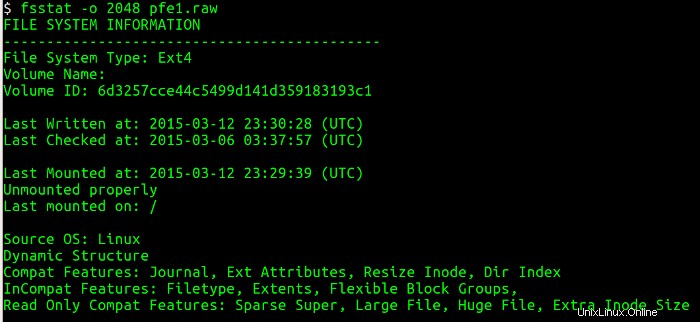
Exécution de fsstat me dit beaucoup de choses utiles sur la partition :le type de système de fichiers, la dernière fois que des données ont été écrites sur le système de fichiers, si le système de fichiers a été proprement démonté et où le système de fichiers a été monté.
Je suis prêt à monter la partition et à lancer l'analyse. Pour ce faire, je dois lire les tables de partition sur l'image brute spécifiée et créer des cartes de périphériques sur les segments de partition détectés. Je pourrais le faire à la main avec les informations de mmls et fsstat — ou je pourrais utiliser kpartx pour le faire pour moi.

J'utilise des options pour créer un mappage en lecture seule (-r ), ajoutez le mappage de partition (-a ), et donner une sortie détaillée (-v ). La loop0p1 est le nom d'un fichier de périphérique sous /dev/mapper Je peux utiliser pour accéder à la partition. Pour le monter, je lance :
$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
Notez que je monte la partition en lecture seule (-o ro ) pour éviter toute contamination accidentelle.
Après avoir monté le disque, je commence mon analyse médico-légale et mon enquête en créant une chronologie. Certains médecins légistes ne croient pas à la création d'un calendrier. Au lieu de cela, une fois qu'ils ont une partition montée, ils se faufilent dans le système de fichiers à la recherche d'artefacts qui pourraient être pertinents pour l'enquête. Je qualifie ces médecins légistes de "creepers". Bien qu'il s'agisse d'une façon d'enquêter de manière médico-légale, elle est loin d'être reproductible, est sujette à des erreurs et peut manquer des preuves précieuses.
Je pense que la création d'une chronologie est une étape cruciale car elle comprend des informations utiles sur les fichiers qui ont été modifiés, consultés, changés et créés dans un format lisible par l'homme, connu sous le nom de preuve temporelle MAC (modifié, consulté, changé). Cette activité permet d'identifier l'heure précise et l'ordre dans lequel un événement a eu lieu.
Remarques sur les systèmes de fichiers Linux
Les systèmes de fichiers Linux comme ext2 et ext3 n'ont pas d'horodatage pour la création/l'heure de naissance d'un fichier. L'horodatage de création a été introduit dans ext4. Le livreForensic Discovery (1ère édition) par Dan Farmer et Wietse Venema décrit les différents horodatages.
- Heure de la dernière modification : Pour les répertoires, il s'agit de la dernière fois qu'une entrée a été ajoutée, renommée ou supprimée. Pour les autres types de fichiers, il s'agit de la dernière fois que le fichier a été écrit.
- Heure du dernier accès (lecture) : Pour les répertoires, c'est la dernière fois qu'il a été recherché. Pour les autres types de fichiers, il s'agit de la dernière fois que le fichier a été lu.
- Dernier changement d'état : Des exemples de changements de statut sont le changement de propriétaire, le changement d'autorisation d'accès, le changement du nombre de liens physiques ou un changement explicite de l'une des heures MAC.
- Heure de suppression : ext2 et ext3 enregistrent l'heure à laquelle un fichier a été supprimé dans le
dtimehorodatage, mais tous les outils ne le prennent pas en charge. - Durée de création : ext4fs enregistre l'heure à laquelle le fichier a été créé dans le
crtimehorodatage, mais tous les outils ne le prennent pas en charge.
Les différents horodatages sont stockés dans les métadonnées contenues dans les inodes. Les inodes sont similaires au numéro d'entrée MFT dans le monde Windows. Une façon de lire les métadonnées du fichier sur un système Linux consiste à obtenir d'abord le numéro d'inode à l'aide de la commande ls -i file puis utilisez istat contre le périphérique de partition et spécifiez le numéro d'inode. Cela vous montrera les différents attributs de métadonnées, y compris les horodatages, la taille du fichier, le groupe du propriétaire et l'ID utilisateur, les autorisations et les blocs qui contiennent les données réelles.
Création de la super chronologie
Ma prochaine étape consiste à créer une super chronologie en utilisant log2timeline/plaso. Plaso est une réécriture basée sur Python de l'outil log2timeline basé sur Perl initialement créé par Kristinn Gudjonsson et amélioré par d'autres. Il est facile de créer une super chronologie avec log2timeline, mais l'interprétation est difficile. La dernière version du moteur plaso peut analyser l'ext4 ainsi que différents types d'artefacts, tels que les messages syslog, l'audit, l'utmp et autres.
Pour créer la super chronologie, je lance log2timeline sur le dossier de disque monté et j'utilise les analyseurs Linux. Ce processus prend un certain temps; quand il se termine, j'ai une chronologie avec les différents artefacts au format de base de données plaso, alors je peux utiliser psort.py pour convertir la base de données plaso en un nombre quelconque de formats de sortie différents. Pour voir les formats de sortie que psort.py prend en charge, entrez psort -o list . J'ai utilisé psort.py pour créer une super chronologie au format Excel. La figure ci-dessous décrit les étapes pour effectuer cette opération.

(Remarque :les lignes superflues ont été supprimées des images)

J'importe la super chronologie dans un tableur pour faciliter la visualisation, le tri et la recherche. Bien que vous puissiez afficher une super chronologie dans un tableur, il est plus facile de l'utiliser dans une vraie base de données telle que MySQL ou Elasticsearch. Je crée une deuxième super chronologie et l'envoie directement à une instance Elasticsearch à partir de psort.py . Une fois la super chronologie indexée par Elasticsearch, je peux visualiser et analyser les données avec Kibana.

Enquête avec Elasticsearch/Kibana
Comme l'a dit le sergent-chef Farrell, "Grâce à la préparation et à la discipline, nous sommes maîtres de notre destin." Lors de l'analyse, il vaut la peine d'être patient et méticuleux et d'éviter d'être une plante grimpante. Une chose qui aide une super analyse chronologique est d'avoir une idée du moment où l'incident a pu se produire. Dans ce cas (jeu de mots), le client dit que l'incident s'est peut-être produit en mars. Je considère toujours la possibilité que le client se trompe sur le délai. Armé de ces informations, je commence à réduire le calendrier de la super chronologie et à le réduire. Je cherche des artefacts d'intérêt qui ont une "proximité temporelle" avec la date supposée de l'incident. Le but est de recréer ce qui s'est passé en se basant sur différents artefacts.
Pour réduire la portée de la super chronologie, j'utilise l'instance Elasticsearch/Kibana que j'ai configurée. Avec Kibana, je peux configurer n'importe quel nombre de tableaux de bord complexes pour afficher et corréler les événements médico-légaux d'intérêt, mais je veux éviter ce niveau de complexité. Au lieu de cela, je sélectionne les index d'intérêt pour l'affichage et crée un graphique à barres d'activité par date :
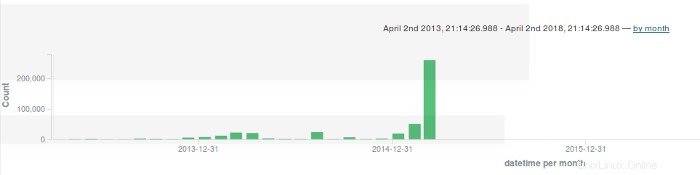
L'étape suivante consiste à développer la grande barre à la fin du graphique :

Il y a un grand bar le 5 mars. Je développe cette barre pour voir l'activité à cette date particulière :
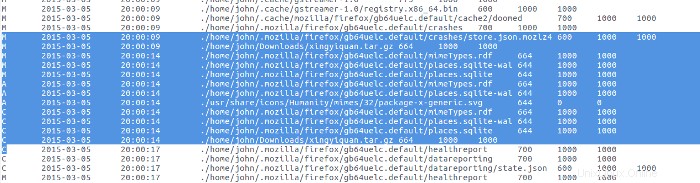
En regardant l'activité du fichier journal à partir de la super chronologie, je vois que cette activité provenait d'une installation/mise à niveau de logiciel. Il y a très peu à trouver dans ce domaine d'activité.
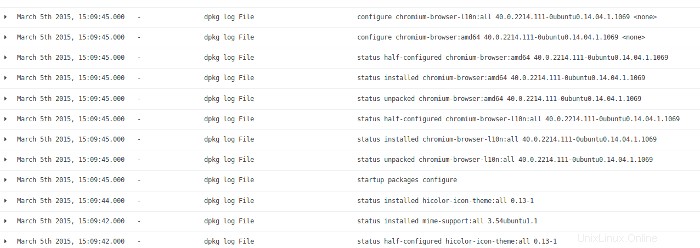
Je retourne à Kibana pour voir la dernière série d'activités sur le système et je trouve ceci dans les journaux :
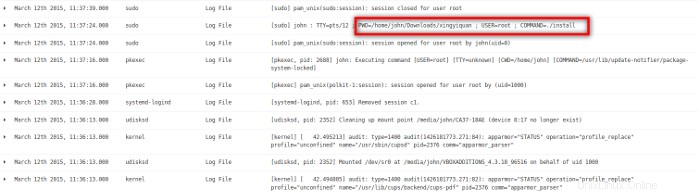
L'une des dernières activités sur le système a été l'utilisateur john qui a installé un programme à partir d'un répertoire nommé xingyiquan. Le Xing Yi Quan est un style d'arts martiaux chinois similaire au Kung Fu et au Tai Chi Quan. Il semble étrange que l'utilisateur john installe un programme d'arts martiaux sur un serveur d'entreprise à partir de son propre compte d'utilisateur. J'utilise la capacité de recherche de Kibana pour trouver d'autres instances de xingyiquan dans les fichiers journaux. J'ai trouvé trois périodes d'activité autour de la chaîne xingyiquan les 5 mars, 9 mars et 12 mars.

Ensuite, je regarde les entrées du journal pour ces jours. Je commence par 05-Mar et trouve des preuves d'une recherche sur Internet à l'aide du navigateur Firefox et du moteur de recherche Google pour un rootkit nommé xingyiquan. La recherche Google a trouvé l'existence d'un tel rootkit sur packetstormsecurity.com. Ensuite, le navigateur est allé sur packetstormsecurity.com et a téléchargé un fichier nommé xingyiquan.tar.gz de ce site dans le répertoire de téléchargement de l'utilisateur john.
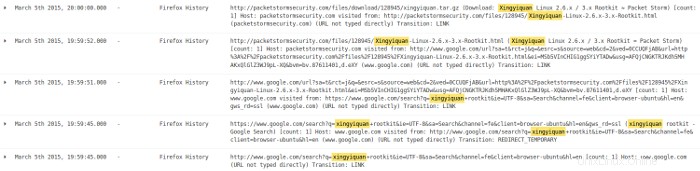
Bien qu'il semble que l'utilisateur John soit allé sur google.com pour rechercher le rootkit, puis sur packetstormsecurity.com pour télécharger le rootkit, ces entrées de journal n'indiquent pas l'utilisateur à l'origine de la recherche et du téléchargement. Je dois approfondir cette question.
Le navigateur Firefox conserve ses informations d'historique dans une base de données SQLite sous le .mozilla répertoire dans le répertoire personnel d'un utilisateur (c'est-à-dire l'utilisateur john) dans un fichier nommé places.sqlite . Pour afficher les informations dans la base de données, j'utilise un programme appelé sqlitebrowser. Il s'agit d'une application graphique qui permet à un utilisateur d'explorer une base de données SQLite et d'afficher les enregistrements qui y sont stockés. J'ai lancé sqlitebrowser et importé places.sqlite depuis le .mozilla répertoire sous le répertoire personnel de l'utilisateur john. Les résultats sont affichés ci-dessous.

Le nombre dans la colonne de droite correspond à l'horodatage de l'activité de gauche. Comme test de congruence, j'ai converti l'horodatage 1425614413880000 au temps humain et a obtenu le 5 mars 2015, 20:00:13.880 PM. Cela correspond étroitement à l'heure du 5 mars 2015, 20:00:00.000 de Kibana. Nous pouvons dire avec une certitude raisonnable que l'utilisateur john a recherché un rootkit nommé xingyiquan et a téléchargé un fichier de packetstormsecurity.com nommé xingyiquan.tar.gz au répertoire de téléchargement de l'utilisateur john.
Enquête avec MySQL
À ce stade, je décide d'importer la super chronologie dans une base de données MySQL pour obtenir une plus grande flexibilité dans la recherche et la manipulation des données que ne le permet seul Elasticsearch/Kibana.
Construire le rootkit xingyiquan
Je charge la super chronologie que j'ai créée à partir de la base de données plaso dans une base de données MySQL. En travaillant avec Elasticsearch/Kibana, je sais que l'utilisateur John a téléchargé le rootkit xingyiquan.tar.gz de packetstormsecurity.com vers le répertoire de téléchargement. Voici la preuve de l'activité de téléchargement à partir de la base de données chronologique MySQL :
Peu de temps après le téléchargement du rootkit, la source de tar.gz l'archive a été extraite.
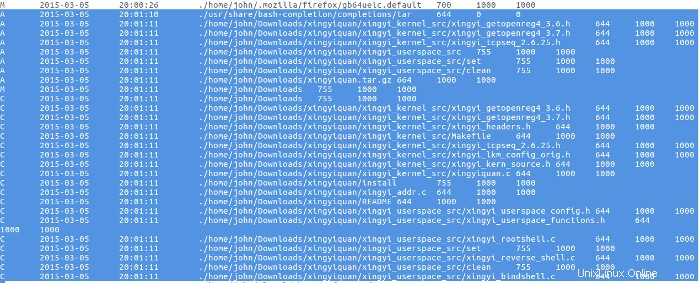
Rien n'a été fait avec le rootkit jusqu'au 9 mars, lorsque le mauvais acteur a lu le fichier README du rootkit avec le programme More, puis a compilé et installé le rootkit.
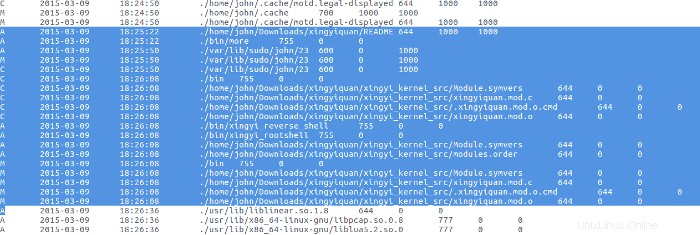
Historiques des commandes
Je charge les historiques de tous les utilisateurs sur pfe1 qui ont bash l'historique des commandes dans une table de la base de données MySQL. Une fois les historiques chargés, je peux facilement les afficher à l'aide d'une requête telle que :
select * from histories order by recno; Pour obtenir un historique pour un utilisateur spécifique, j'utilise une requête comme :
select historyCommand from histories where historyFilename like '%<username>%' order by recno;
Je trouve plusieurs commandes intéressantes du bash de l'utilisateur john l'histoire. À savoir, l'utilisateur johnn a créé le compte johnn, l'a supprimé, l'a recréé, a copié /bin/true à /bin/false , a donné les mots de passe aux comptes whoopsie et lightdm, a copié /bin/bash à /bin/false , modifié les fichiers de mot de passe et de groupe, déplacé le répertoire personnel de l'utilisateur johnn de johnn à .johnn , (ce qui en fait un répertoire caché), a changé le fichier de mot de passe en utilisant sed après avoir cherché comment utiliser
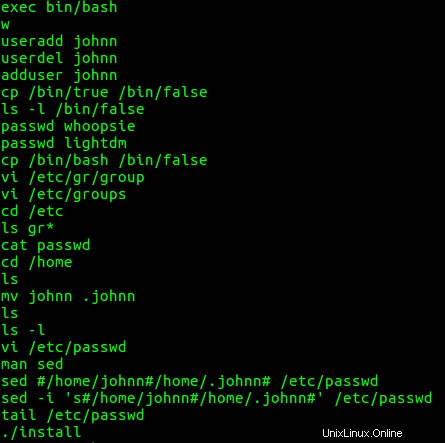
Ensuite, je regarde le bash historique des commandes pour l'utilisateur johnn. Il n'a montré aucune activité inhabituelle.
Notant que l'utilisateur john a copié /bin/bash à /bin/false , je teste si cela était vrai en vérifiant la taille de ces fichiers et en obtenant un hachage MD5 des fichiers. Comme indiqué ci-dessous, les tailles de fichier et les hachages MD5 sont les mêmes. Ainsi, les fichiers sont les mêmes.
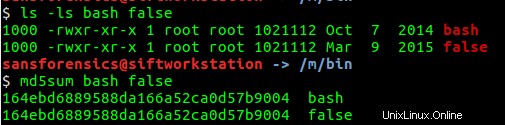
Enquête sur les connexions réussies et échouées
Pour répondre à une partie de la question "quand", je charge les fichiers journaux contenant des données sur les connexions, les déconnexions, les démarrages et les arrêts du système dans une table de la base de données MySQL. Utiliser une requête simple comme :
select * from logins order by start Je trouve l'activité suivante :

À partir de cette figure, je vois que l'utilisateur john s'est connecté à pfe1 à partir de l'adresse IP 192.168.56.1 . Cinq minutes plus tard, l'utilisateur johnn s'est connecté à pfe1 à partir de la même adresse IP. Deux connexions par l'utilisateur lightdm ont suivi quatre minutes plus tard et une autre une minute plus tard, puis l'utilisateur johnn s'est connecté moins d'une minute plus tard. Puis pfe1 a été redémarré.
En regardant les connexions infructueuses, je trouve cette activité :

Encore une fois, l'utilisateur lightdm a tenté de se connecter à pfe1 à partir de l'adresse IP 192.168.56.1 . À la lumière de faux comptes se connectant à pfe1, l'une de mes recommandations à PFE sera de vérifier le système avec l'adresse IP 192.168.56.1 pour preuve de compromission.
Enquêter sur les fichiers journaux
Cette analyse des connexions réussies et échouées fournit des informations précieuses sur le moment où les événements se sont produits. Je porte mon attention sur l'investigation des fichiers journaux sur pfe1, en particulier l'activité d'authentification et d'autorisation dans /var/log/auth* . Je charge tous les fichiers journaux sur pfe1 dans une table de base de données MySQL et utilise une requête comme :
select logentry from logs where logfilename like '%auth%' order by recno;
et enregistrez-le dans un fichier. J'ouvre ce fichier avec mon éditeur préféré et recherche 192.168.56.1 . Voici une section de l'activité :
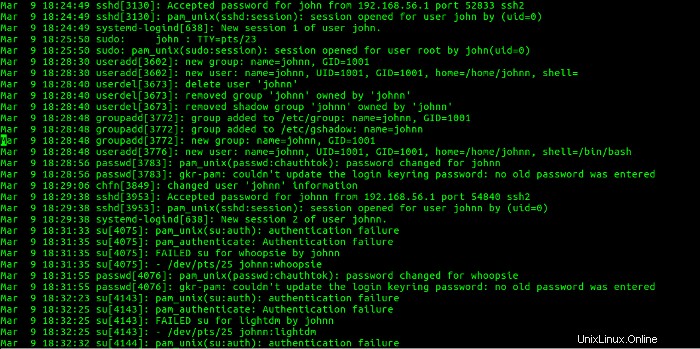
Cette section montre que l'utilisateur john s'est connecté à partir de l'adresse IP 192.168.56.1 et créé le compte johnn, supprimé le compte johnn et créé à nouveau. Ensuite, l'utilisateur johnn s'est connecté à pfe1 à partir de l'adresse IP 192.168.56.1 . Ensuite, l'utilisateur johnn a tenté de devenir l'utilisateur whoopsie avec un su commande, qui a échoué. Ensuite, le mot de passe de l'utilisateur whoopsie a été modifié. L'utilisateur johnn a ensuite tenté de devenir l'utilisateur lightdm avec un su commande, qui a également échoué. Cela correspond à l'activité illustrée dans les figures 21 et 22.
Conclusions de mon enquête
- L'utilisateur john a recherché, téléchargé, compilé et installé un rootkit nommé xingyiquan sur le serveur pfe1. Le rootkit xingyiquan cache les processus, les fichiers, les répertoires, les processus et les connexions réseau ; ajoute des portes dérobées ; et plus encore.
- L'utilisateur john a créé, supprimé et recréé un autre compte sur pfe1 nommé johnn. L'utilisateur john a fait du répertoire personnel de l'utilisateur johnn un fichier caché pour masquer l'existence de ce compte d'utilisateur.
- L'utilisateur john a copié le fichier
/bin/truesur/bin/falsepuis/bin/bashsur/bin/falsepour faciliter les connexions des comptes système qui ne sont normalement pas utilisés pour les connexions interactives. - L'utilisateur john a créé des mots de passe pour les comptes système whoopsie et lightdm. Ces comptes n'ont normalement pas de mot de passe.
- Le compte d'utilisateur johnn a été connecté avec succès et l'utilisateur johnn a tenté en vain de devenir les utilisateurs whoopsie et lightdm.
- Le serveur pfe1 a été sérieusement compromis.
Mes recommandations à PFE
- Reconstruisez le serveur pfe1 à partir de la distribution d'origine et appliquez tous les correctifs pertinents au système avant de le remettre en service.
- Configurez un serveur syslog centralisé et connectez tous les systèmes du cloud hybride PFE au serveur syslog centralisé et aux journaux locaux pour consolider les données des journaux et empêcher la falsification des journaux système. Utilisez un produit de surveillance des informations et des événements de sécurité (SIEM) pour faciliter l'examen et la corrélation des événements de sécurité.
- Mettre en œuvre
bashhorodatages des commandes sur tous les serveurs de l'entreprise. - Activez la journalisation d'audit du compte racine sur tous les serveurs PFE et dirigez les journaux d'audit vers le serveur syslog centralisé où ils peuvent être corrélés avec d'autres informations de journal.
- Inspectez le système avec l'adresse IP
192.168.56.1pour les violations et les compromis, car il a été utilisé comme point pivot dans le compromis de pfe1.
Si vous avez utilisé la criminalistique pour analyser votre système de fichiers Linux à la recherche de compromis, veuillez partager vos conseils et recommandations dans les commentaires.
Gary Smith prendra la parole au LinuxFest Northwest cette année. Consultez les temps forts du programme ou inscrivez-vous pour y assister.