Les expressions régulières peuvent être l'un des outils les plus puissants de votre boîte à outils en tant qu'utilisateur Linux, administrateur système ou même en tant que programmeur. Cela peut aussi être l'une des choses les plus intimidantes à apprendre, mais ce n'est pas obligatoire ! Bien qu'il existe un nombre infini de façons d'écrire une expression, vous n'avez pas besoin d'apprendre chaque commutateur et indicateur. Dans ce court tutoriel, je vais vous montrer quelques façons simples d'utiliser les regex qui vous permettront de démarrer en un rien de temps et partager quelques ressources de suivi qui feront de vous un maître des regex si vous le souhaitez.
Un aperçu rapide
Les expressions régulières, également appelées modèles "regex" ou même "instructions régulières", sont en termes simples "une séquence de caractères qui définissent un modèle de recherche". L'idée est née dans les années 1950 lorsque Stephen Cole Kleene a écrit une description d'une idée qu'il a appelée un "langage régulier", dont une partie est devenue connue sous le nom de "théorème de Kleene". À un niveau très élevé, il indique que si les éléments du langage peuvent être définis, alors une expression peut être écrite pour correspondre aux modèles de ce langage.
Plus de ressources Linux
- Aide-mémoire des commandes Linux
- Aide-mémoire des commandes Linux avancées
- Cours en ligne gratuit :Présentation technique de RHEL
- Aide-mémoire sur le réseau Linux
- Aide-mémoire SELinux
- Aide-mémoire sur les commandes courantes de Linux
- Que sont les conteneurs Linux ?
- Nos derniers articles Linux
Depuis lors, les expressions régulières ont fait partie des premiers programmes Unix, y compris vi, sed, awk, grep et autres. En fait, le mot grep est dérivé de la commande utilisée dans le premier éditeur "ed", à savoir g/re/p , ce qui signifie essentiellement "faites une recherche globale pour cette expression régulière et imprimez les lignes". Cool !
Pourquoi avons-nous besoin d'expressions régulières
Comme mentionné ci-dessus, les expressions régulières sont utilisées pour définir un modèle pour nous aider à faire correspondre ou "trouver" des objets qui correspondent à ce modèle. Ces objets peuvent être des fichiers dans un système de fichiers lors de l'utilisation de find commande par exemple, ou un bloc de texte dans un fichier que nous pourrions rechercher en utilisant grep, awk, vi ou sed, par exemple.
Commencer par les bases
Commençons au tout début; c'est un très bon point de départ.
La première regex que tout le monde semble apprendre est probablement celle que vous connaissez déjà et que vous ne saviez pas ce que c'était. Avez-vous déjà voulu imprimer une liste de fichiers dans un répertoire, mais c'était trop long ? Peut-être avez-vous vu quelqu'un taper \*.gif pour lister les images GIF dans un répertoire, comme :
$ ls *.gif
C'est une expression régulière !
Lors de l'écriture d'expressions régulières, certains caractères ont une signification particulière pour nous permettre d'aller au-delà de la simple correspondance de caractères pour faire correspondre des ensembles entiers de caractères. Dans ce cas, le * Le caractère, également appelé "étoile" ou "splat", remplace les noms de fichiers et vous permet de faire correspondre tous les fichiers se terminant par .gif .
Rechercher des modèles dans un fichier
La prochaine étape de votre formation regex foo consiste à rechercher des modèles dans un fichier, en particulier en utilisant le modèle de remplacement pour effectuer des modifications rapides.
Voici deux façons courantes de procéder :
- Utilisez vi pour ouvrir le fichier, rechercher un motif et effectuer la modification (même automatiquement en utilisant le remplacement).
- Utilisez "l'éditeur de flux", alias sed, pour rechercher par programmation dans le fichier et apporter la modification.
Commençons par apprendre quelques regex en utilisant vi pour éditer le fichier suivant :
Le renard brun rapide a sauté par-dessus le chien paresseux.
Test simple
Test plus difficile
Cas de test extrême
ABC 123 abc 567
Le chien est paresseuxMaintenant, avec ce fichier ouvert dans vi, regardons quelques exemples de regex qui nous aideront à trouver des chaînes correspondantes à l'intérieur et même à les remplacer automatiquement.
Pour rendre les choses plus faciles, réglons vi pour ignorer la casse. Tapez
set icpour activer la recherche insensible à la casse.Maintenant, pour commencer la recherche dans vi, tapez le
/caractère suivi de votre modèle de recherche.Rechercher des éléments au début ou à la fin d'une ligne
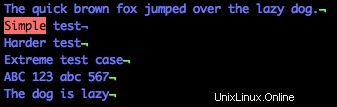
Pour trouver une ligne commençant par "Simple", utilisez ce modèle d'expression régulière :
/^SimpleRemarquez dans l'image ci-dessous que seule la ligne commençant par "Simple" est en surbrillance. Le symbole du carat (
^) est l'équivalent regex de "commence par".
Ensuite, utilisons le
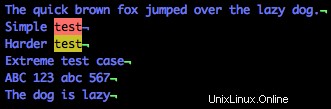
$symbole, qui en langage regex est "se termine par"./test$
Vous voyez comment il met en évidence les deux lignes qui se terminent par "test" ? Notez également que la quatrième ligne contient le mot test, mais pas à la fin, donc cette ligne n'est pas mise en surbrillance.
C'est la puissance des expressions régulières, qui vous donne la possibilité de parcourir rapidement un grand nombre de correspondances avec facilité, mais en particulier de rechercher uniquement les correspondances exactes.
Tester la fréquence d'occurrence
Pour approfondir vos compétences en expressions régulières, examinons quelques caractères spéciaux plus courants qui nous permettent de rechercher non seulement du texte correspondant, mais également des modèles de correspondances.
Caractères correspondant à la fréquence :
| Personnage | Signification | Exemple |
|---|---|---|
* | Zéro ou plus | ab* – la lettre a suivi de zéro ou plus b s |
+ | Un ou plusieurs | ab+ – la lettre a suivi d'un ou plusieurs b s |
? | Zéro ou un | ab? – zéro ou un seul b |
{n} | Étant donné un nombre, trouver exactement ce nombre | ab{2} – la lettre a suivi exactement de deux b s |
{n,} | Étant donné un nombre, trouvez au moins ce nombre | ab{2,} – la lettre a suivi d'au moins deux b s |
{n,y} | Étant donné deux nombres, trouvez une plage de ce nombre | ab{1,3} – la lettre a suivi de un à trois b s |
Rechercher des classes de caractères
La prochaine étape de la formation regex consiste à utiliser des classes de caractères dans notre correspondance de modèles. Ce qu'il est important de noter ici, c'est que ces classes peuvent être combinées soit sous forme de liste, comme [a,d,x,z] , ou sous forme de plage, telle que [a-z] , et que les caractères sont généralement sensibles à la casse.
Pour voir ce travail dans vi, nous devrons désactiver la casse ignorée que nous avons définie précédemment. Tapons :set noic pour désactiver à nouveau la casse.
Certaines classes courantes de caractères utilisées comme plages sont :
- a-z – tous les caractères en minuscules
- A-Z :tous les caractères MAJUSCULES
- 0-9 – chiffres
Essayons maintenant une recherche similaire à celle que nous avons effectuée précédemment :
/tT
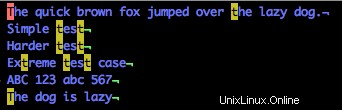
Vous remarquez qu'il ne trouve rien ? C'est parce que la regex précédente recherche exactement "tT". Si nous remplaçons ceci par :
/[tT]
Nous verrons que les T minuscules et MAJUSCULES correspondent dans tout le document.
Maintenant, enchaînons quelques gammes de classes ensemble et voyons ce que nous obtenons. Essayez :
/[A-Z1-3]
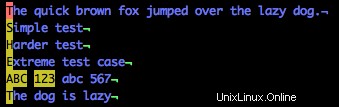
Notez que les majuscules et 123 sont mis en surbrillance, mais pas les minuscules (y compris la fin de la ligne cinq).
Drapeaux
La dernière étape de votre formation initiale aux expressions régulières consiste à comprendre les indicateurs qui existent pour rechercher des types spéciaux de caractères sans avoir à les répertorier dans une plage.
.– n'importe quel caractère\s– espace blanc\w– mot\d– chiffre (nombre)
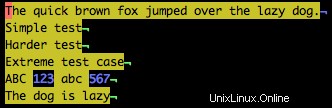
Par exemple, pour trouver tous les chiffres dans l'exemple de texte, utilisez :
/\d
Notez dans l'exemple ci-dessous que tous les chiffres sont mis en surbrillance.
Pour correspondre à l'opposé, vous utilisez généralement le même drapeau, mais en MAJUSCULES. Par exemple :
\S– pas un espace\W– pas un mot\D– pas un chiffre
Notez dans l'exemple ci-dessous qu'en utilisant \D , tous les caractères SAUF les chiffres sont mis en surbrillance.
Recherche avec sed
Une note rapide sur sed :c'est un éditeur de flux, ce qui signifie que vous n'interagissez pas avec une interface utilisateur. Il prend le flux entrant d'un côté et l'écrit de l'autre côté.
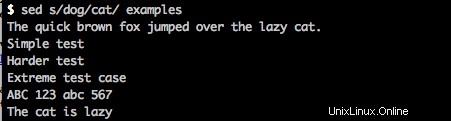
L'utilisation de sed est très similaire à vi, sauf que vous lui donnez l'expression régulière à rechercher et à remplacer, et qu'elle renvoie la sortie. Par exemple :
sed s/dog/cat/ examples
renverra ce qui suit à l'écran :
Si vous souhaitez enregistrer ce fichier, ce n'est qu'un peu plus délicat. Vous devrez enchaîner quelques commandes pour a) écrire ce fichier et b) le copier par-dessus le premier fichier.
Pour ce faire, essayez :
sed s/dog/cat/ examples> temp.out ; Exemples de mv temp.out
Maintenant, si vous regardez vos examples fichier, vous verrez que le mot "chien" a été remplacé.
Le renard brun rapide a sauté par-dessus le chat paresseux.
Test simple
Test plus difficile
Cas de test extrême
ABC 123 abc 567
Le chat est paresseuxPour plus d'informations
J'espère que ce fut un aperçu utile des expressions régulières. Bien sûr, ce n'est que la pointe de l'iceberg, et j'espère que vous continuerez à en apprendre davantage sur cet outil puissant en consultant les ressources supplémentaires ci-dessous.
Où obtenir de l'aide
- Ma ressource préférée est la PERL Pocket Reference
- Pour une maîtrise avancée des expressions régulières, consultez Maîtriser les expressions régulières par Jeff Friedl
Pour plus d'exemples, consultez
- Comment rechercher des fichiers sous Linux
- Validation des données en Perl avec Regexp::Common
- 7 raisons d'aimer Vim