Scrapy est un logiciel open source utilisé pour extraire des données de sites Web. Le framework Scrapy est développé en Python et effectue le travail d'exploration de manière rapide, simple et extensible. Nous avons créé une machine virtuelle (VM) dans une boîte virtuelle et Ubuntu 14.04 LTS y est installé.
Installer Scrapy
Scrapy dépend de Python, des bibliothèques de développement et du logiciel pip. La dernière version de Python est pré-installée sur Ubuntu. Nous devons donc installer les bibliothèques de développement pip et python avant l'installation de Scrapy.
Pip remplace easy_install pour l'indexeur de packages python. Il est utilisé pour l'installation et la gestion des packages Python.
Pour installer le package pip, exécutez :
$ sudo apt-get install python-pip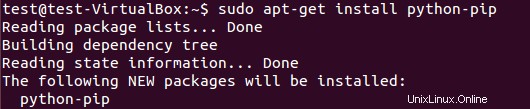
Nous devons installer les bibliothèques de développement Python en utilisant la commande suivante. Si ce package n'est pas installé, l'installation de scrapy framework génère une erreur concernant le fichier d'en-tête python.h.
$ sudo apt-get install python-dev
Le framework Scrapy peut être installé à partir du package deb ou du code source. Cependant, nous avons installé le package deb à l'aide de pip (gestionnaire de packages Python).
$ sudo pip install scrapy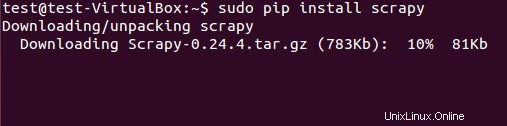
L'installation réussie de Scrapy prend un certain temps.

Extraction de données à l'aide du framework Scrapy
(Tutoriel de base)
Nous utiliserons Scrapy pour extraire les noms de magasins (qui fournissent des cartes) des articles du site Web fatwallet.com. Tout d'abord, nous avons créé un nouveau projet scrapy "store_name" en utilisant la commande suivante.
$ sudo scrapy startproject store_name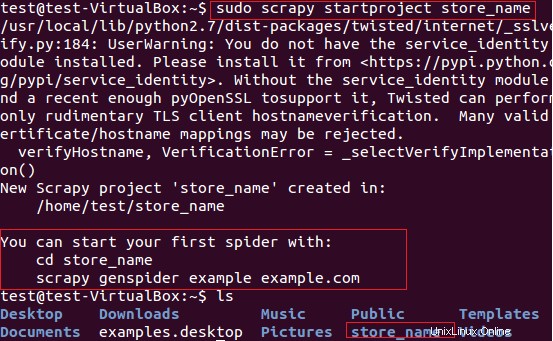
La commande ci-dessus crée un répertoire avec le titre "store_name" au chemin actuel. Ce répertoire principal du projet contient des fichiers/dossiers qui sont illustrés dans la figure 6 suivante.
$ sudo ls –lR store_name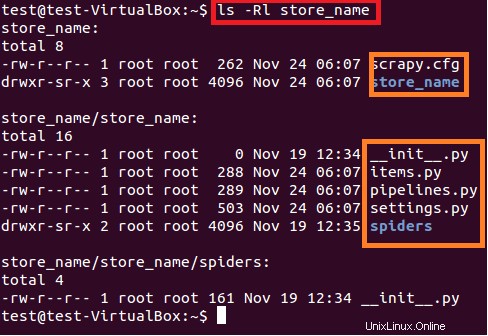
Une brève description de chaque fichier/dossier est donnée ci-dessous :
- scrapy.cfg est le fichier de configuration du projet
- store_name/ est un autre répertoire à l'intérieur du répertoire principal. Ce répertoire contient le code python du projet.
- store_name/items.py contient les éléments qui seront extraits par l'araignée.
- store_name/pipelines.py est le fichier pipelines.
- Le paramètre du projet store_name se trouve dans le fichier store_name/settings.py.
- et le répertoire store_name/spiders/, contient spider pour l'exploration
Comme nous sommes intéressés à extraire les noms de magasin des cartes du site fatwallet.com, nous avons donc mis à jour le contenu du fichier comme indiqué ci-dessous.
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storeAprès cela, nous devons écrire une nouvelle araignée sous le répertoire store_name/spiders/ du projet. Spider est une classe Python composée des attributs obligatoires suivants :
Nom de l'araignée (name )
- URL de départ de l'araignée pour l'exploration (start_urls)
Et méthode d'analyse qui consiste en regex pour l'extraction des éléments souhaités de la réponse de la page. La méthode d'analyse est la partie importante de spider.
Nous avons créé l'araignée "store_name.py" sous le répertoire store_name/spiders/ et ajouté le code python suivant pour l'extraction du nom du magasin du site fatwallet.com. La sortie de l'araignée est écrite dans le fichier (StoreName.txt ).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")
REMARQUE :Le but de ce didacticiel est uniquement la compréhension de Scrapy Framework