Présentation
Kubernetes offre un niveau de flexibilité extraordinaire pour orchestrer un grand cluster de conteneurs distribués.
Le grand nombre de fonctionnalités et d'options disponibles peut présenter un défi. L'application des meilleures pratiques vous aide à éviter les obstacles potentiels et à créer un environnement sécurisé et efficace dès le départ.
Utilisez les bonnes pratiques Kubernetes décrites pour créer des conteneurs optimisés, rationaliser les déploiements, administrer des services fiables et gérer un cluster complet.

Sécuriser et optimiser les conteneurs
Les conteneurs offrent beaucoup moins d'isolation que les machines virtuelles. Vous devez toujours vérifier les images de conteneur et maintenir un contrôle strict sur les autorisations des utilisateurs.
L'utilisation de petites images de conteneurs améliore l'efficacité, préserve les ressources et réduit la surface d'attaque pour les attaquants potentiels.
N'utilisez que des images de conteneur de confiance
Les images de conteneurs prêtes à l'emploi sont hautement accessibles et exceptionnellement utiles. Cependant, les images publiques peuvent rapidement devenir obsolètes, contenir des exploits, des bogues ou même des logiciels malveillants qui se propagent rapidement dans un cluster Kubernetes.
N'utilisez que des images provenant de référentiels de confiance et analysez toujours les images à la recherche de vulnérabilités potentielles. De nombreux outils en ligne, tels que Anchore ou Clair, fournissent une analyse statique rapide des images de conteneurs et vous informent des menaces et problèmes potentiels. Passez quelques instants à analyser les images de conteneurs avant de les déployer et évitez les conséquences potentiellement désastreuses.
Utilisateurs non root et systèmes de fichiers en lecture seule
Modifiez le contexte de sécurité intégré pour forcer tous les conteneurs à s'exécuter uniquement avec des utilisateurs non root et avec un système de fichiers en lecture seule.
Évitez d'exécuter des conteneurs en tant qu'utilisateur racine. Une faille de sécurité peut rapidement s'aggraver si un utilisateur peut s'accorder des autorisations supplémentaires.

Si un système de fichiers est défini en lecture seule, il y a peu de chance de falsifier le contenu du conteneur. Au lieu de modifier les fichiers système, le conteneur entier devrait être supprimé et un nouveau mis à sa place.
Créer des images petites et superposées
Les petites images accélèrent vos constructions et nécessitent moins de stockage. La superposition efficace d'une image peut réduire considérablement la taille de l'image. Essayez de créer vos images à partir de zéro pour obtenir des résultats optimaux.
Utilisez plusieurs instructions FROM dans un seul Dockerfile si vous avez besoin de nombreux composants différents. Cette fonctionnalité crée des sections, chacune faisant référence à une image de base différente. L'image finale ne stocke plus les couches précédentes, uniquement les composants dont vous avez besoin de chacune, ce qui rend le conteneur Docker beaucoup plus mince.
Chaque couche est extraite en fonction du FROM commande située dans le conteneur déployé.
Limiter l'accès des utilisateurs avec RBAC
Le contrôle d'accès basé sur les rôles (RBAC) garantit qu'aucun utilisateur ne dispose de plus d'autorisations que nécessaire pour accomplir ses tâches. Vous pouvez activer RBAC en ajoutant l'indicateur suivant lors du démarrage du serveur d'API :
--authorization-mode=RBACRBAC utilise rbac.authorization.k8s.io Groupe d'API pour piloter les décisions d'autorisation via l'API Kubernetes.
Journaux Stdout et Stderr
Il est courant d'envoyer les journaux d'application à la stdout (sortie standard) et journaux d'erreurs vers stderr (erreur standard) flux. Une fois qu'une application écrit sur stdout et stderr, un moteur de conteneur, comme Docker, redirige et stocke les enregistrements dans un fichier JSON.
Les conteneurs, pods et nœuds Kubernetes sont des entités dynamiques. Les journaux doivent être cohérents et disponibles en permanence. Il est donc recommandé de conserver vos journaux à l'échelle du cluster dans un système de stockage principal distinct.
Kubernetes peut être intégré à une large gamme de solutions de journalisation existantes, telles que la pile ELK.
Rationalisation des déploiements
Un déploiement Kubernetes établit un modèle qui garantit que les pods sont opérationnels, régulièrement mis à jour ou annulés comme défini par l'utilisateur.
L'utilisation d'étiquettes, d'indicateurs, de conteneurs liés et de DaemonSets clairs peut vous donner un contrôle précis sur le processus de déploiement.
Utiliser le drapeau d'enregistrement
Lorsque vous ajoutez le --record flag, le kubectl exécuté La commande est stockée sous forme d'annotation. En inspectant l'historique de déploiement du déploiement, vous pouvez facilement suivre les mises à jour dans le CHANGE-CAUSE colonne.
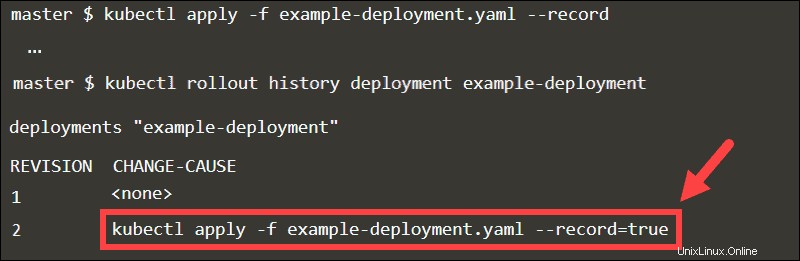
Revenez à n'importe quelle révision en déclarant le numéro de révision dans la commande d'annulation.
kubectl rollout undo deployment example-deployment --to-revision=1
Sans le --record flag, il serait difficile d'identifier la révision spécifique.
Étiquettes descriptives
Essayez d'utiliser autant d'étiquettes descriptives que possible. Les étiquettes sont des paires clé:valeur qui permettent aux utilisateurs de regrouper et d'organiser les pods en sous-ensembles significatifs. La plupart des fonctionnalités, plug-ins et solutions tierces ont besoin d'étiquettes pour pouvoir identifier les pods et contrôler les processus automatisés.
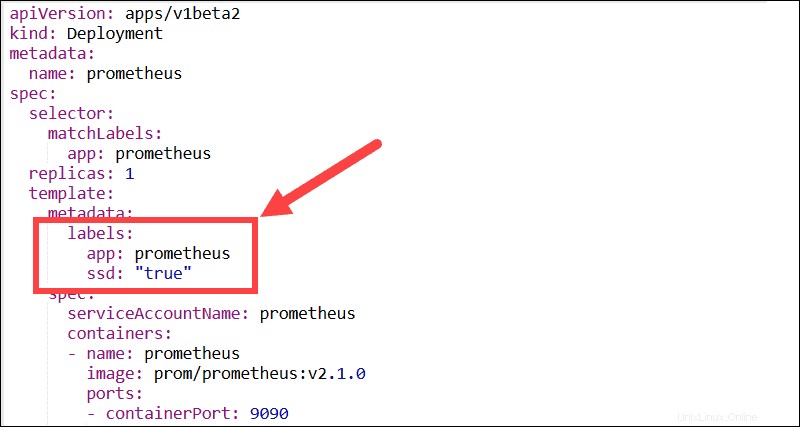
Par exemple, les DaemonSets Kubernetes dépendent des libellés et des sélecteurs de nœuds pour gérer le déploiement des pods au sein d'un cluster.
Créer plusieurs processus dans un pod
Utilisez les capacités de liaison de conteneurs de Kubernetes au lieu d'essayer de résoudre tous les problèmes à l'intérieur d'un conteneur. Il déploie efficacement plusieurs conteneurs sur un seul pod Kubernetes. Un bon exemple est l'externalisation des fonctionnalités de sécurité vers un proxy sidecar conteneur.
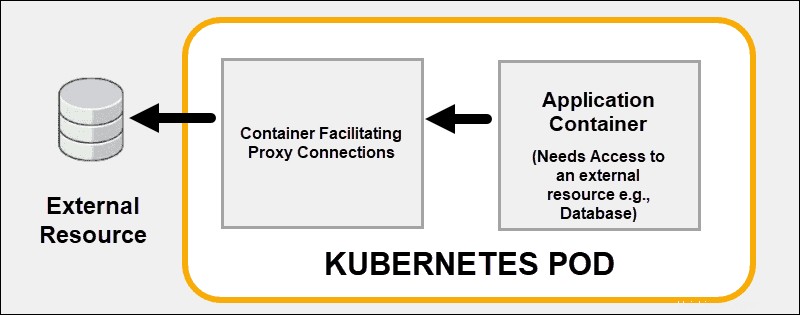
Un conteneur couplé peut prendre en charge ou améliorer les fonctionnalités de base du conteneur principal ou aider le conteneur principal à s'adapter à son environnement de déploiement.
Utiliser des conteneurs d'initialisation
Un ou plusieurs conteneurs d'initialisation effectuent généralement des tâches utilitaires ou des contrôles de sécurité que vous ne souhaitez pas inclure dans le conteneur d'application principal. Vous pouvez utiliser des conteneurs init pour vous assurer qu'un service est prêt avant de lancer le conteneur principal du pod.
Chaque conteneur d'initialisation doit s'exécuter avec succès jusqu'à la fin avant que le conteneur d'initialisation suivant ne démarre. Les conteneurs d'initialisation peuvent retarder l'apparition du conteneur principal du pod jusqu'à ce qu'une condition préalable soit satisfaite. Sans cette condition préalable, Kubernetes redémarre le pod. Une fois la condition préalable remplie, le conteneur init s'arrête automatiquement et permet au conteneur principal de démarrer.
Évitez d'utiliser la dernière balise
S'abstenir d'utiliser aucune balise ou le :latest tag lors du déploiement de conteneurs dans un environnement de production. La dernière balise rend difficile la détermination de la version de l'image en cours d'exécution.
Un moyen efficace de s'assurer que le conteneur utilise toujours la même version de l'image consiste à utiliser le résumé d'image unique comme balise. Dans cet exemple, une version d'image Redis est déployée à l'aide de son condensé unique :
[email protected]:675hgjfn48324cf93ffg43269ee113168c194352dde3eds876677c5cbKubernetes ne met pas automatiquement à jour la version de l'image, sauf si vous modifiez la valeur du résumé.
Configurer les sondes de préparation et de vivacité
Vivant et sondes de préparation aidez Kubernetes à surveiller et à interpréter la santé de vos applications. Si vous définissez une vérification de l'activité et qu'un processus répond aux exigences, Kubernetes arrête le conteneur et démarre une nouvelle instance pour le remplacer.
Les sondes de préparation effectuent des audits au niveau du pod et évaluent si un pod peut accepter le trafic. Si un pod ne répond pas, une vérification de l'état de préparation déclenche un processus pour redémarrer le pod.
La documentation relative à la configuration des sondes de préparation et de vivacité est disponible sur le site Web officiel de Kubernetes.
Essayez différents types de services
En apprenant à utiliser différents types de services, vous pouvez administrer efficacement le trafic interne et externe des pods. Votre objectif est de créer un environnement réseau stable en gérant des points de terminaison fiables tels que les adresses IP, les ports et le DNS.
Ports statiques avec NodePort
Exposez les pods aux utilisateurs externes en définissant le type de service sur NodePort. Si vous spécifiez une valeur dans nodePort , Kubernetes réserve ce numéro de port sur tous les nœuds et transfère tout le trafic entrant destiné aux pods qui font partie du service. Le service est accessible en utilisant à la fois l'IP interne du cluster et l'IP du nœud avec le port réservé.

Les utilisateurs peuvent contacter le service NodePort depuis l'extérieur du cluster en demandant :
NodeIP:NodePortUtilisez toujours un numéro de port dans la plage configurée pour NodePort (30000-32767). Si une transaction API échoue, vous devrez résoudre les éventuelles collisions de ports.
Ingress vs LoadBalancer
Le type LoadBalancer expose les services en externe à l'aide de l'équilibreur de charge de votre fournisseur. Chaque service que vous exposez à l'aide du type LoadBalancer reçoit son adresse IP. Si vous avez de nombreux services, vous pouvez rencontrer des coûts supplémentaires imprévus en fonction du nombre de services exposés.
Une exigence de configuration standard consiste à fournir un contrôleur d'entrée avec une adresse IP publique statique existante. L'adresse IP publique statique reste si le contrôleur d'entrée est supprimé. Cette approche vous permet d'utiliser les enregistrements DNS et les configurations réseau actuels de manière cohérente tout au long du cycle de vie de vos applications.
Mapper des services externes sur un DNS
Le type ExternalName ne mappe pas les services à un sélecteur mais utilise un nom DNS à la place. Utilisez le externalName paramètre pour mapper les services à l'aide d'un enregistrement CNAME. Un enregistrement CNAME est un nom de domaine complet et non une adresse IP numérique.
Les clients qui se connectent au service vont contourner le proxy de service et se connecter directement à la ressource externe. Dans cet exemple, le pnap-service est mappé sur admin.phoenixnap.com ressource externe.

Accès au service pnap fonctionne de la même manière qu'avec d'autres services. La différence cruciale est que la redirection se produit désormais au niveau DNS.
Conception d'applications
Le déploiement automatisé de conteneurs avec Kubernetes garantit que la plupart des opérations s'exécutent désormais sans intervention humaine directe. Concevez vos applications et images de conteneurs de manière à ce qu'elles soient interchangeables et ne nécessitent pas une microgestion constante.
Concentrez-vous sur les services individuels
Essayez de diviser votre application en plusieurs services et évitez de regrouper trop de fonctionnalités dans un seul conteneur. Il est beaucoup plus facile de redimensionner les applications horizontalement et de réutiliser les conteneurs s'ils se concentrent sur une seule fonction.
Lors de la création de vos applications, partez du principe que vos conteneurs sont des entités à court terme qui vont être arrêtées et redémarrées régulièrement.
Utiliser les graphiques Helm
Helm, le gestionnaire de packages d'applications Kubernetes, peut rationaliser le processus d'installation et déployer très rapidement des ressources dans l'ensemble du cluster. Les packages de l'application Helm sont appelés Charts.
Des applications comme MySQL, PostgreSQL, MongoDB, Redis, WordPress sont des solutions en demande. Au lieu de créer et de modifier plusieurs fichiers de configuration complexes, vous pouvez déployer des graphiques Helm facilement disponibles.
Utilisez la commande suivante pour créer les déploiements, services, PersistentVolumeClaims et secrets nécessaires pour exécuter le gestionnaire Kafka sur votre cluster.
helm install --name my-messenger stable/kafka-managerVous n'avez plus besoin d'analyser des composants spécifiques et d'apprendre à les configurer pour exécuter Kafka correctement.
Utiliser l'affinité des nœuds et des pods
La fonction d'affinité est utilisée pour définir à la fois l'affinité de nœud et l'affinité inter-pod. L'affinité de nœud vous permet de spécifier les nœuds sur lesquels un pod peut être planifié en utilisant des étiquettes de nœud existantes.
- requiredDuringSchedulingIgnoredDuringExecution – Établit les contraintes obligatoires qui doivent être respectées pour qu'un pod soit planifié sur un nœud.
- preferredDuringSchedulingIgnoredDuringExecution – Définit les préférences qu'un planificateur priorise mais ne garantit pas.
Si les étiquettes de nœud changent au moment de l'exécution et que les règles d'affinité du pod ne sont plus respectées, le pod n'est pas supprimé du nœud. Le nodeSelector Le paramètre limite les pods à des nœuds spécifiques à l'aide d'étiquettes. Dans cet exemple, le pod Grafana va être planifié uniquement sur les nœuds qui ont le ssd étiquette.
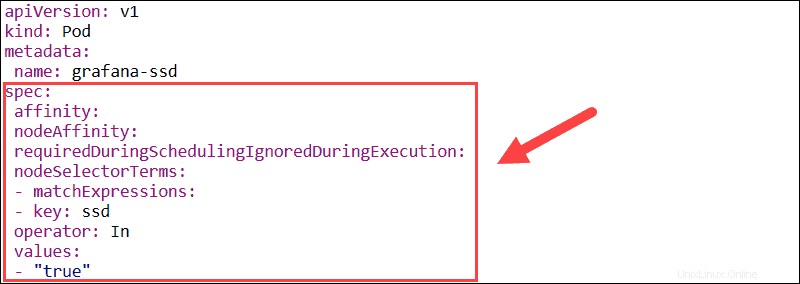
La fonctionnalité d'affinité/anti-affinité de pod élargit les types de contraintes que vous pouvez exprimer. Au lieu d'utiliser des étiquettes de nœud, vous pouvez utiliser des étiquettes de pod existantes pour délimiter les nœuds sur lesquels un pod peut être planifié. Cette fonctionnalité vous permet de définir des règles afin que les pods individuels soient programmés en fonction des étiquettes des autres pods.
Alertes et tolérances de nœud
Kubernetes essaie automatiquement de déployer des pods aux emplacements avec la charge de travail la plus faible. L'affinité de nœud et de pod vous permet de contrôler sur quel nœud un pod est déployé. Les teintes peuvent empêcher le déploiement de pods sur des nœuds spécifiques sans altérer les pods existants. Les pods que vous souhaitez déployer sur un nœud contaminé doivent s'inscrire pour utiliser le nœud.
- Les souillures – Empêchez la planification de nouveaux pods sur les nœuds, définissez les préférences des nœuds et supprimez les pods existants d'un nœud.
- Tolérances – Activez la planification des pods uniquement sur les nœuds avec des Taints existants et correspondants.
Les teintes et les tolérances produisent des résultats optimaux lorsqu'elles sont utilisées ensemble pour garantir que les pods sont planifiés sur les nœuds appropriés.
Regrouper des ressources avec des espaces de noms
Utilisez les espaces de noms Kubernetes pour partitionner de grands clusters en groupes plus petits et facilement identifiables. Les espaces de noms vous permettent de créer des environnements de test, d'assurance qualité, de production ou de développement distincts et d'allouer des ressources adéquates au sein d'un espace de noms unique. Les noms des ressources Kubernetes doivent uniquement être uniques au sein d'un même espace de noms. Différents espaces de noms peuvent avoir des ressources portant le même nom.
Si plusieurs utilisateurs ont accès au même cluster, vous pouvez limiter les utilisateurs et leur permettre d'agir dans les limites d'un espace de noms spécifique. Séparer les utilisateurs est un excellent moyen de délimiter les ressources et d'éviter d'éventuels conflits de nommage ou de version.
Les espaces de noms sont des ressources Kubernetes et sont exceptionnellement faciles à créer. Créez un fichier YAML définissant le nom de l'espace de noms et utilisez kubectl pour le publier sur le serveur d'API Kubernetes. Vous pouvez ensuite utiliser l'espace de noms pour administrer le déploiement de ressources supplémentaires.