Présentation
Pandas est une bibliothèque Python open source principalement utilisée pour l'analyse de données. La collection d'outils du package Pandas est une ressource essentielle pour préparer, transformer et agréger des données en Python.
La bibliothèque Pandas est basée sur le package NumPy et est compatible avec un large éventail de modules existants. L'ajout de deux nouvelles structures de données tabulaires, Series et DataFrames , permet aux utilisateurs d'utiliser des fonctionnalités similaires à celles des bases de données relationnelles ou des feuilles de calcul.
Cet article vous montre comment installer Python Pandas et présente les commandes de base de Pandas.

Comment installer Python Pandas
La popularité de Python a entraîné la création de nombreuses distributions et packages. Les gestionnaires de packages sont des outils efficaces utilisés pour automatiser le processus d'installation, gérer les mises à niveau, configurer et supprimer les packages et les dépendances Python.
Remarque : Version Python 3.6.1 ou version ultérieure est un prérequis pour une installation de Pandas. Utilisez notre guide détaillé pour vérifier votre version actuelle de Python. Si vous ne disposez pas de la version Python requise, vous pouvez utiliser l'un de ces guides détaillés :
- Comment installer Python 3.8 sur Ubuntu 18.04 ou Ubuntu 20.04.
- Comment installer Python 3 sur Windows 10
- Comment installer la dernière version de Python 3 sur Centos 7
Installer Pandas avec Anaconda
Le package Anaconda contient déjà la bibliothèque Pandas. Vérifiez la version actuelle de Pandas en tapant la commande suivante dans votre terminal :
conda list pandasLa sortie confirme la version et la construction de Pandas.

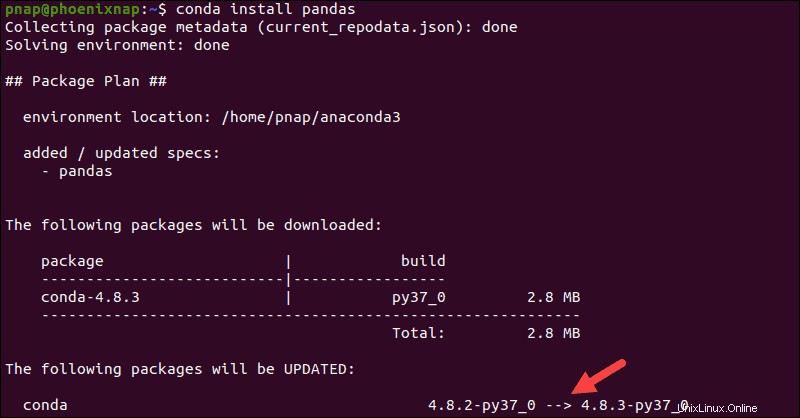
Si Pandas n'est pas présent sur votre système, vous pouvez également utiliser le conda outil pour installer Pandas :
conda install pandasAnaconda gère l'intégralité de la transaction en installant une collection de modules et de dépendances.
Installer Pandas avec pip
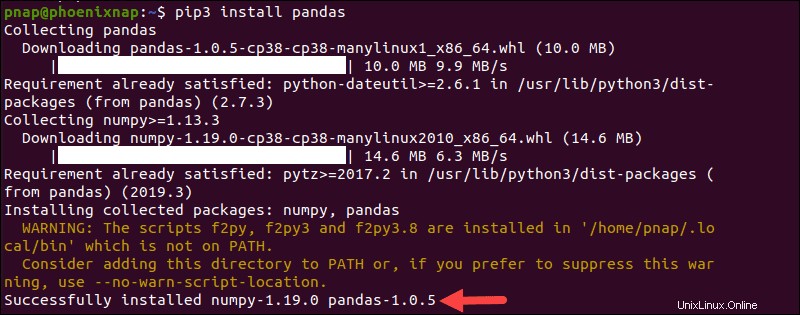
Le référentiel de logiciels PyPI est administré régulièrement et maintient les dernières versions des logiciels basés sur Python. Installez pip, le gestionnaire de packages PyPI, et utilisez-le pour déployer des pandas Python :
pip3 install pandasLe processus de téléchargement et d'installation prend quelques instants.
Installer Pandas sur Linux
L'installation d'une solution préemballée n'est pas toujours l'option préférée. Vous pouvez installer Pandas sur n'importe quelle distribution Linux en utilisant la même méthode qu'avec les autres modules. Par exemple, utilisez la commande suivante pour installer le module Pandas de base sur Ubuntu 20.04 :
sudo apt install python3-pandas -y Gardez à l'esprit que les packages des dépôts Linux ne contiennent souvent pas la dernière version disponible.
Utiliser des pandas Python
La flexibilité de Python vous permet d'utiliser Pandas dans une grande variété de frameworks. Cela inclut les éditeurs de code Python de base, les commandes émises depuis le shell Python de votre terminal, les environnements interactifs tels que Spyder, PyCharm, Atom et bien d'autres. Les exemples pratiques et les commandes de ce didacticiel sont présentés à l'aide de Jupyter Notebook.
Importation de la bibliothèque Python Pandas
Pour analyser et travailler sur des données, vous devez importer la bibliothèque Pandas dans votre environnement Python. Démarrez une session Python et importez Pandas à l'aide des commandes suivantes :
import pandas as pdimport numpy as np
Il est considéré comme une bonne pratique d'importer des pandas comme pd et le numpy bibliothèque scientifique en tant que np . Cette action vous permet d'utiliser pd ou np lors de la saisie des commandes. Sinon, il serait nécessaire de saisir le nom complet du module à chaque fois.

Il est essentiel d'importer la bibliothèque Pandas chaque fois que vous démarrez un nouvel environnement Python.
Séries et DataFrames
Python Pandas utilise Series et DataFrames pour structurer les données et les préparer pour diverses actions analytiques. Ces deux structures de données sont l'épine dorsale de la polyvalence de Pandas. Les utilisateurs déjà familiarisés avec les bases de données relationnelles comprennent naturellement les concepts et commandes de base de Pandas.
Série Pandas
Les séries représentent un objet dans la bibliothèque Pandas. Ils structurent des ensembles de données simples et unidimensionnels en associant chaque élément de données à une étiquette unique. Une série se compose de deux tableaux - le principal tableau qui contient les données et l'index tableau contenant les étiquettes appariées.
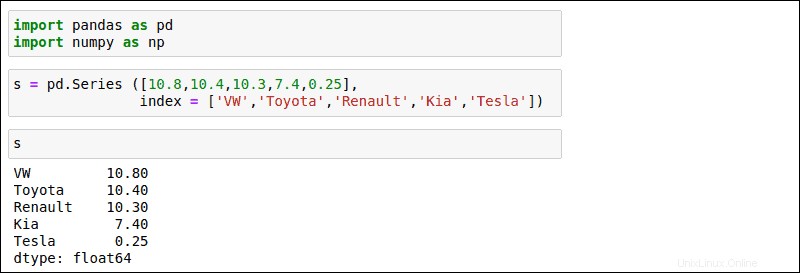
Utilisez l'exemple suivant pour créer une série de base. Dans cet exemple, la série structure les numéros de vente de voitures indexés par constructeur :
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
Après avoir exécuté la commande, tapez s pour afficher la série que vous venez de créer. Le résultat répertorie les fabricants en fonction de l'ordre dans lequel ils ont été saisis.
Vous pouvez exécuter un ensemble de fonctions complexes et variées sur les séries, y compris les fonctions mathématiques, la manipulation de données et les opérations arithmétiques entre les séries. Une liste complète des paramètres, attributs et méthodes de Pandas est disponible sur la page officielle de Pandas.
Frames de données Pandas
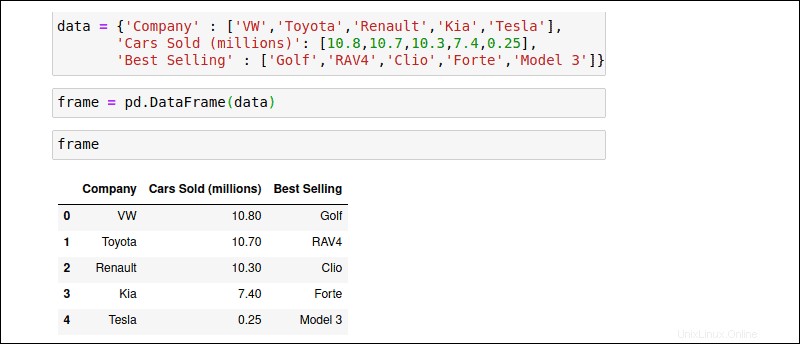
Le DataFrame introduit une nouvelle dimension dans la structure de données Series. En plus du tableau d'index, un ensemble de colonnes strictement agencées fournit aux DataFrames une structure semblable à une table. Chaque colonne peut stocker un type de données différent. Essayez de créer manuellement un dict objet appelé "data" avec les mêmes données de vente de voitures :
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}
Passez l'objet 'data' au pd.DataFrame() constructeur :
frame = pd.DataFrame(data)
Utilisez le nom du DataFrame, frame , pour exécuter l'objet :
frameLe DataFrame résultant formate les valeurs en lignes et en colonnes.
La structure DataFrame vous permet de sélectionner et de filtrer des valeurs en fonction de colonnes et de lignes, d'attribuer de nouvelles valeurs et de transposer les données. Comme pour Series, la page officielle de Pandas fournit une liste complète des paramètres, attributs et méthodes DataFrame.
Lire et écrire avec des pandas
Grâce à Series et DataFrames, Pandas introduit un ensemble de fonctions qui permettent aux utilisateurs d'importer des fichiers texte, des formats binaires complexes et des informations stockées dans des bases de données. La syntaxe pour lire et écrire des données dans Pandas est simple :
pd.read_filetype = (filename or path)– importer des données d'autres formats dans Pandas.df.to_filetype = (filename or path)– exporter des données de Pandas vers d'autres formats.
Les formats les plus courants incluent CSV , XLXS , JSON , HTML, et SQL .
| Lire | Écrire |
|---|---|
| pd.read_csv (‘nomfichier.csv’) | df.to_csv ('nom de fichier ou chemin') |
| pd.read_excel (‘nomfichier.xlsx’) | df.to_excel ('nom de fichier ou chemin') |
| pd.read_json (‘filename.json’) | df.to_json ('nom de fichier ou chemin') |
| pd.read_html (‘nomfichier.htm’) | df.to_html ('nom de fichier ou chemin') |
| pd.read_sql (‘nomtable’) | df.to_sql ('Nom de la BD') |
Dans cet exemple, la nz_population Le fichier CSV contient les données démographiques de la Nouvelle-Zélande pour les 10 dernières années. Importez le fichier CSV à l'aide de la bibliothèque Pandas avec la commande suivante :
pop_df = pd.read_csv('nz_population.csv')Les utilisateurs sont libres de définir le nom du DataFrame (pop_df ). Tapez le nom du DataFrame nouvellement créé pour afficher le tableau de données :
pop_df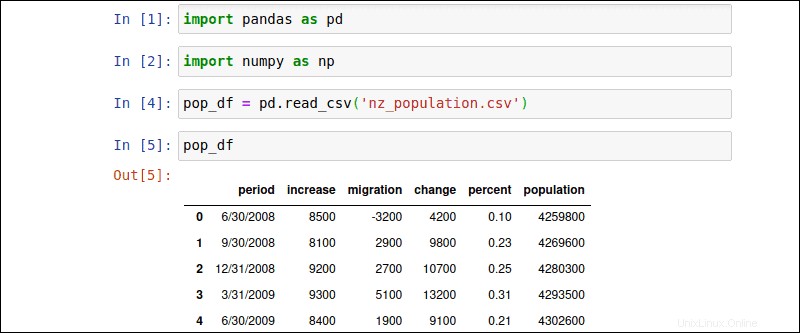
Commandes Pandas courantes
Une fois que vous avez importé un fichier dans la bibliothèque Pandas, vous pouvez utiliser un ensemble de commandes simples pour explorer et manipuler les ensembles de données.
Commandes DataFrame de base
Entrez la commande suivante pour récupérer un aperçu du pop_df DataFrame de l'exemple précédent :
pop_df.info()La sortie fournit le nombre d'entrées, le nom de chaque colonne, les types de données et la taille du fichier.
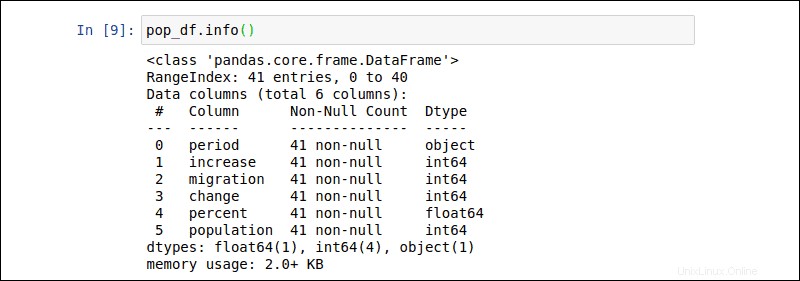
Utilisez le pop_df.head() commande pour afficher les 5 premières lignes du DataFrame.
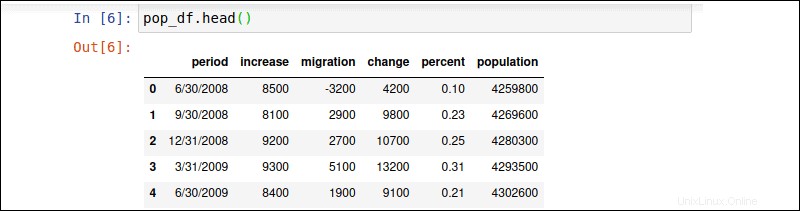
Tapez le pop_df.tail() commande pour afficher les 5 dernières lignes du pop_df DataFrame.
Sélectionnez des lignes et des colonnes spécifiques en utilisant leurs noms et le iloc attribut. Sélectionnez une seule colonne en utilisant son nom entre crochets :
pop_df['population']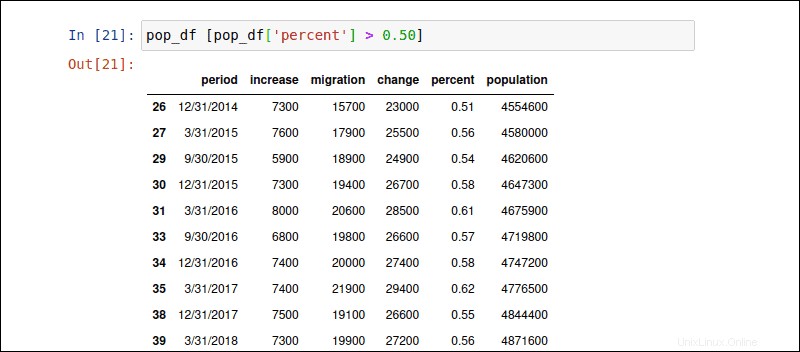
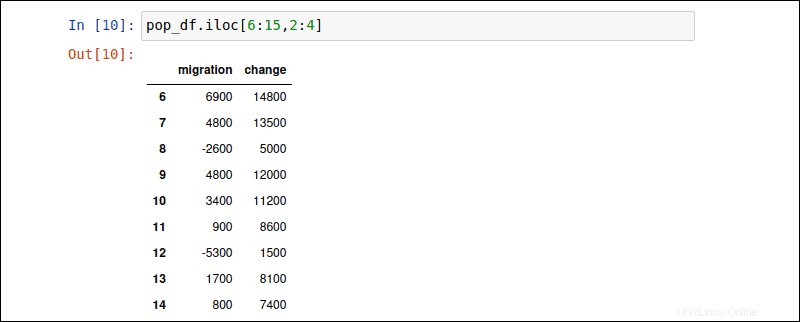
Le iloc L'attribut vous permet de récupérer un sous-ensemble de lignes et de colonnes. Les lignes sont spécifiées avant la virgule et les colonnes après la virgule. La commande suivante récupère les données des lignes 6 à 16 et des colonnes 2 à 4 :
pop_df.iloc [6:15,2:4]
Les deux-points : ordonne à Pandas d'afficher l'intégralité du sous-ensemble spécifié.
Expressions conditionnelles
Vous pouvez sélectionner des lignes en fonction d'une expression conditionnelle. La condition est définie entre crochets [] . La commande suivante filtre les lignes où la valeur de la colonne "pourcentage" est supérieure à 0,50 %.
pop_df [pop_df['percent'] > 0.50]Agrégation de données
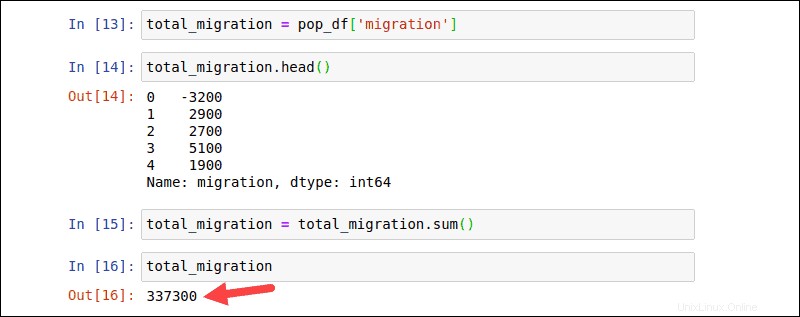
Utilisez des fonctions pour calculer les valeurs d'un tableau entier et produire un seul résultat. Crochets [] permettent également aux utilisateurs de sélectionner une seule colonne et de la transformer en DataFrame. La commande suivante crée un nouveau total_migration DataFrame de la migration colonne dans pop_df :
total_migration = pop_df['migration']Vérifiez les données en vérifiant les 5 premières lignes :
total_migration.head()
Calculez la migration nette vers la Nouvelle-Zélande avec le df.sum() fonction :
total_migration = total_migration.sum()total_migrationLa sortie produit un résultat unique qui représente la somme totale des valeurs dans total_migration DataFrame.
Certaines des fonctions d'agrégation les plus courantes incluent :
df.mean()– Calculer la moyenne des valeurs.df.median()– Calculer la médiane des valeurs.df.describe()– Fournit un résumé statistique .df.min()/df.max()– Les valeurs minimales et maximales du jeu de données.df.idxmin()/df.idxmax()– Les valeurs d'index minimum et maximum.
Ces fonctions essentielles ne représentent qu'une petite fraction des actions et opérations disponibles que Pandas a à offrir.