Présentation
MySQL est une application de base de données open source populaire qui stocke et structure les données de manière significative et facilement accessible. Avec les applications volumineuses, la quantité de données peut entraîner des problèmes de performances.
Ce guide fournit plusieurs conseils de réglage sur la façon d'améliorer les performances d'une base de données MySQL .

Prérequis
- Un système Linux avec MySQL installé et en cours d'exécution, Centos ou Ubuntu
- Une base de données existante
- Identifiants d'administrateur pour le système d'exploitation et la base de données
Réglage des performances du système MySQL
Au niveau du système, vous ajusterez les options matérielles et logicielles pour améliorer les performances de MySQL.
1. Équilibrez les quatre principales ressources matérielles

Stockage
Prenez un moment pour évaluer votre stockage. Si vous utilisez des disques durs traditionnels (HDD), vous pouvez passer à des disques SSD pour améliorer les performances.
Utilisez un outil comme iotop ou sar depuis le sysstat package pour surveiller les taux d'entrée/sortie de votre disque. Si l'utilisation du disque est beaucoup plus élevée que l'utilisation des autres ressources, envisagez d'ajouter plus de stockage ou de passer à un stockage plus rapide.
Processeur
Les processeurs sont généralement considérés comme la mesure de la rapidité de votre système. Utilisez le top Linux commande pour une ventilation de la façon dont vos ressources sont utilisées. Faites attention aux processus MySQL et au pourcentage d'utilisation du processeur qu'ils nécessitent.
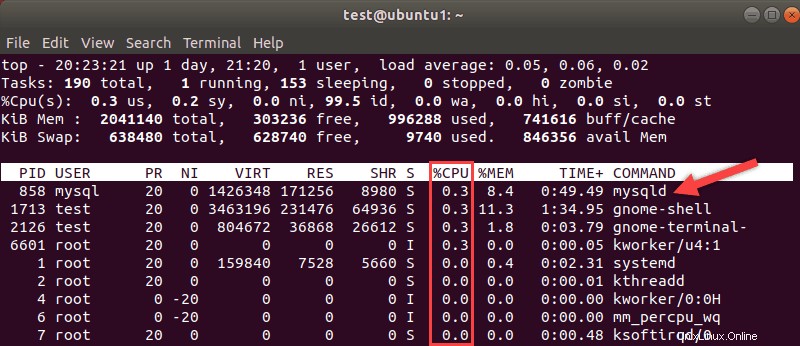
Les processeurs sont plus chers à mettre à niveau, mais si votre CPU est un goulot d'étranglement, une mise à niveau peut être nécessaire.
Mémoire
La mémoire représente la quantité totale de RAM dans votre serveur de stockage de base de données MySQL. Vous pouvez ajuster le cache mémoire (plus sur cela plus tard) pour améliorer les performances . Si vous ne disposez pas de suffisamment de mémoire ou si la mémoire existante n'est pas optimisée, vous risquez de nuire à vos performances au lieu de les améliorer.
Comme d'autres goulots d'étranglement, si votre serveur manque constamment de mémoire, vous pouvez mettre à niveau en en ajoutant davantage. Si vous manquez de mémoire, votre serveur mettra en cache le stockage de données (comme un disque dur) pour agir comme mémoire. La mise en cache de la base de données ralentit vos performances.
Réseau
Il est important de surveiller le trafic réseau pour vous assurer que vous disposez d'une infrastructure suffisante pour gérer la charge.
La surcharge de votre réseau peut entraîner une latence, des pertes de paquets et même des pannes de serveur. Assurez-vous que vous disposez d'une bande passante réseau suffisante pour gérer vos niveaux normaux de trafic de base de données.
2. Utilisez InnoDB, pas MyISAM
MonISAM est un ancien style de base de données utilisé pour certaines bases de données MySQL. C'est une conception de base de données moins efficace. Le nouveau InnoDB prend en charge des fonctionnalités plus avancées et dispose de mécanismes d'optimisation intégrés.
InnoDB utilise un index clusterisé et conserve les données dans des pages, qui sont stockées dans des blocs physiques consécutifs. Si une valeur est trop grande pour une page, InnoDB la déplace vers un autre emplacement, puis indexe la valeur. Cette fonctionnalité permet de conserver les données pertinentes au même endroit sur le périphérique de stockage, ce qui signifie que le disque dur physique prend moins de temps pour accéder aux données.
3. Utilisez la dernière version de MySQL
L'utilisation de la dernière version n'est pas toujours possible pour les bases de données anciennes et héritées. Mais dans la mesure du possible, vous devez vérifier la version de MySQL utilisée et mettre à niveau vers la dernière.
Une partie du développement en cours comprend des améliorations de performances. Certains ajustements de performances courants peuvent être rendus obsolètes par les nouvelles versions de MySQL. En général, il est toujours préférable d'utiliser l'amélioration des performances natives de MySQL plutôt que les fichiers de script et de configuration.
Réglage des performances du logiciel MySQL
Le réglage des performances SQL est le processus d'optimisation de la vitesse des requêtes sur une base de données relationnelle. La tâche implique généralement plusieurs outils et techniques.
Ces méthodes impliquent :
- Ajustement des fichiers de configuration MySQL.
- Écrire des requêtes de base de données plus efficaces.
- Structurer la base de données pour récupérer les données plus efficacement.
4. Envisagez d'utiliser un outil d'amélioration automatique des performances
Comme avec la plupart des logiciels, tous les outils ne fonctionnent pas sur toutes les versions de MySQL. Nous allons examiner trois utilitaires pour évaluer votre base de données MySQL et recommander des modifications pour améliorer les performances.
Le premier est l'amorce de réglage. Cet outil est un peu plus ancien, conçu pour MySQL 5.5 - 5.7. Il peut analyser votre base de données et suggérer des paramètres pour améliorer les performances. Par exemple, il peut suggérer que vous augmentiez la query_cache_size paramètre s'il semble que votre système ne peut pas traiter les requêtes assez rapidement pour garder le cache vide.
Le deuxième outil de réglage, utile pour la plupart des bases de données SQL modernes, est MySQLTuner. Ce script (mysqltuner.pl ) est écrit en Perl. Comme tuning-primer, il analyse la configuration de votre base de données à la recherche de goulots d'étranglement et d'inefficacités. Le résultat affiche des statistiques et des recommandations :
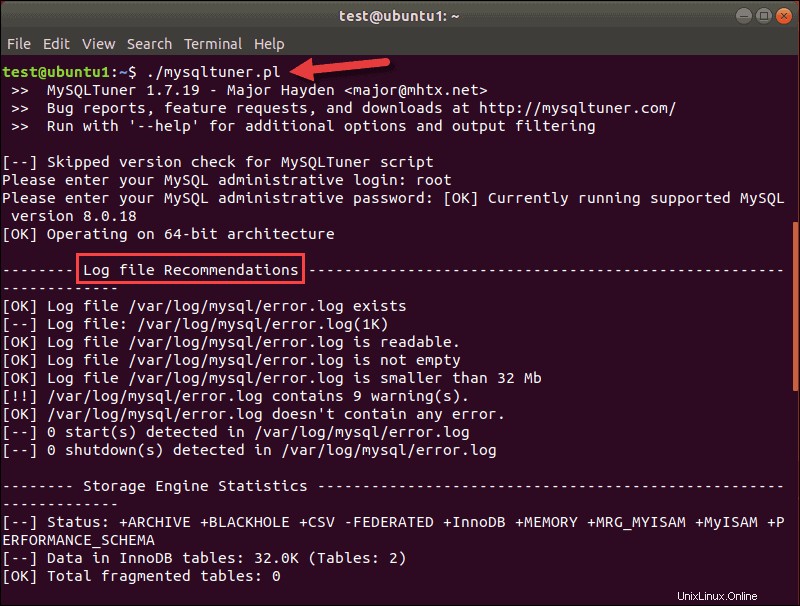
En haut de la sortie, vous pouvez voir la version de l'outil MySQLTuner et de votre base de données.
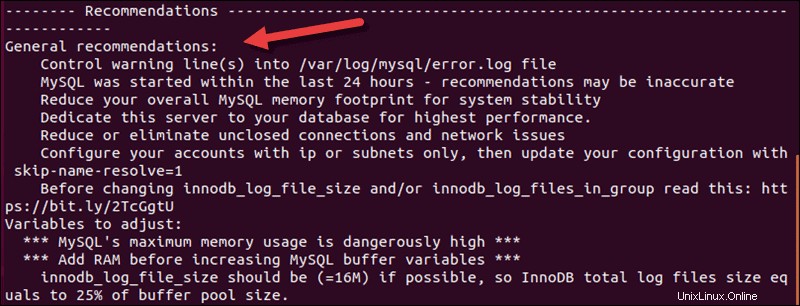
Le script fonctionne avec MySQL 8.x. Les recommandations de fichiers journaux sont les premières sur la liste, mais si vous faites défiler vers le bas, vous pouvez voir des recommandations générales pour améliorer les performances de MySQL.
Le troisième utilitaire, que vous possédez peut-être déjà, est le conseiller phpMyAdmin . Comme les deux autres utilitaires, il évalue votre base de données et recommande des ajustements. Si vous utilisez déjà phpMyAdmin, le conseiller est un outil utile que vous pouvez utiliser dans l'interface graphique.
5. Optimiser les requêtes
Une requête est une requête codée pour rechercher dans la base de données des données correspondant à une certaine valeur. Certains opérateurs de requête, de par leur nature même, prennent beaucoup de temps à s'exécuter. Les techniques de réglage des performances SQL permettent d'optimiser les requêtes pour de meilleurs temps d'exécution.
La détection des requêtes avec un temps d'exécution médiocre est l'une des principales tâches de réglage des performances. Les requêtes couramment mises en œuvre sur de grands ensembles de données sont lentes et occupent des bases de données. Les tables sont donc indisponibles pour toute autre tâche.
Par exemple, une base de données OLTP nécessite des transactions rapides et un traitement efficace des requêtes. L'exécution d'une requête inefficace bloque l'utilisation de la base de données et bloque les mises à jour des informations.
Si votre environnement repose sur des requêtes automatisées telles que des déclencheurs , elles peuvent avoir un impact sur les performances. Vérifiez et terminez les processus MySQL qui peuvent s'accumuler dans le temps.
6. Utilisez les index le cas échéant
De nombreuses requêtes de base de données utilisent une structure similaire à celle-ci :
SELECT … WHERECes requêtes impliquent l'évaluation, le filtrage et la récupération des résultats. Vous pouvez les restructurer en ajoutant un petit ensemble d'index pour les tables associées. La requête peut être dirigée vers l'index pour accélérer la requête.
7. Fonctions dans les prédicats
Évitez d'utiliser une fonction dans le prédicat d'une requête. Par exemple :
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
Le UPPER la notation crée une fonction, qui doit fonctionner pendant le SELECT opération. Cela double le travail de la requête et vous devriez l'éviter si possible.
8. Éviter % Wildcard dans un prédicat
Lors de la recherche dans des données textuelles, les caractères génériques permettent d'élargir la recherche. Par exemple, pour sélectionner tous les noms commençant par ch , créez un index sur la colonne name et exécutez :
SELECT * FROM person WHERE name LIKE "ch%"La requête analyse les index, ce qui réduit le coût de la requête :

Cependant, effectuer une recherche de noms en utilisant les caractères génériques au début augmente considérablement le coût de la requête car un parcours d'indexation ne s'applique pas aux fins de chaînes :
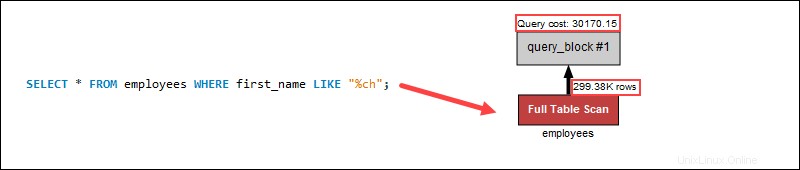
Un caractère générique au début d'une recherche n'applique pas l'indexation. Au lieu de cela, une analyse complète de la table recherche dans chaque ligne individuellement, ce qui augmente le coût de la requête dans le processus. Dans l'exemple de requête, l'utilisation d'un caractère générique à la fin permet de réduire le coût de la requête en parcourant moins de lignes de table.
Une façon de rechercher les extrémités des chaînes est d'inverser la chaîne, d'indexer les chaînes inversées et de regarder les caractères de début. Placer le caractère générique à la fin recherche désormais le début de la chaîne inversée, ce qui rend la recherche plus efficace.
9. Spécifiez les colonnes dans la fonction SELECT
Une expression couramment utilisée pour les requêtes analytiques et exploratoires est SELECT * . En sélectionner plus que nécessaire entraîne une perte de performances et une redondance inutiles. Si vous spécifiez les colonnes dont vous avez besoin, votre requête n'aura pas besoin d'analyser les colonnes non pertinentes.
Si toutes les colonnes sont nécessaires, il n'y a pas d'autre moyen de s'y prendre. Cependant, la plupart des exigences métier n'ont pas besoin de toutes les colonnes disponibles dans un jeu de données. Envisagez plutôt de sélectionner des colonnes spécifiques.
Pour résumer, évitez d'utiliser :
SELECT * FROM tableÀ la place, essayez :
SELECT column1, column2 FROM table10. Utilisez ORDER BY de manière appropriée
Le ORDER BY expression trie les résultats en fonction de la colonne spécifiée. Il peut être utilisé pour trier par deux colonnes à la fois. Ceux-ci doivent être triés dans le même ordre, croissant ou décroissant.
Si vous essayez de trier différentes colonnes dans un ordre différent, cela ralentira les performances. Vous pouvez le combiner avec un index pour accélérer le tri.
11. GROUP BY au lieu de SELECT DISTINCT
Le SELECT DISTINCT query est pratique lorsque vous essayez de vous débarrasser des valeurs en double. Cependant, l'instruction nécessite une grande quantité de puissance de traitement.
Dans la mesure du possible, évitez d'utiliser SELECT DISTINCT , car il est très inefficace et parfois déroutant. Par exemple, si un tableau répertorie des informations sur les clients avec la structure suivante :
| identifiant | nom | nom | adresse | ville | état | zip |
|---|---|---|---|---|---|---|
| 0 | Jean | Smith | 652 rue des fleurs | Los Angeles | CA | 90017 |
| 1 | Jean | Smith | 1215, boulevard de l'Océan | Los Angeles | CA | 90802 |
| 2 | Marthe | Matthieu | 3104, boulevard Pico | Los Angeles | CA | 90019 |
| 3 | Marthe | Jones | 2712 Boulevard de Venise | Los Angeles | CA | 90019 |
L'exécution de la requête suivante renvoie quatre résultats :
SELECT DISTINCT name, address FROM person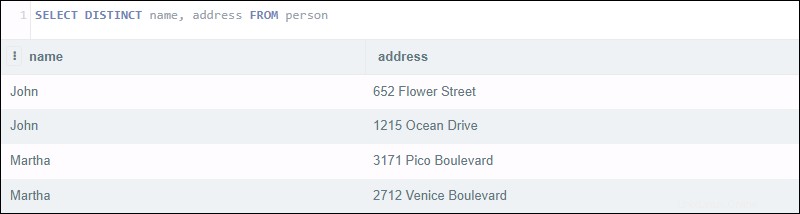
La déclaration semble devoir renvoyer une liste de noms distincts avec leur adresse. Au lieu de cela, la requête examine les deux la colonne nom et adresse. Bien qu'il existe deux paires de clients portant le même nom, leurs adresses sont différentes.
Pour filtrer les noms en double et renvoyer les adresses, essayez d'utiliser le GROUP BY déclaration :
SELECT name, address FROM person GROUP BY name
Le résultat renvoie le premier nom distinct avec l'adresse, ce qui rend l'instruction moins ambiguë. Pour regrouper par adresses uniques, le GROUP BY le paramètre changerait simplement en adresse et renverrait le même résultat que le DISTINCT déclaration plus rapidement.
Pour résumer, évitez d'utiliser :
SELECT DISTINCT column1, column2 FROM tableÀ la place, essayez d'utiliser :
SELECT column1, column2 FROM table GROUP BY column112. REJOINDRE, OÙ, UNION, DISTINCTE
Essayez d'utiliser une jointure interne dans la mesure du possible. Une jointure externe examine des données supplémentaires en dehors des colonnes spécifiées. C'est bien si vous avez besoin de ces données, mais c'est une perte de performances d'inclure des données qui ne seront pas nécessaires.
Utilisation de INNER JOIN est l'approche standard pour joindre des tables. La plupart des moteurs de base de données acceptent d'utiliser WHERE aussi bien. Par exemple, les deux requêtes suivantes renvoient le même résultat :
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.idPar rapport à :
SELECT * FROM table1, table2 WHERE table1.id = table2.idEn théorie, ils ont également le même temps d'exécution.
Le choix d'utiliser ou non JOIN ou WHERE requête dépendent du moteur de base de données. Alors que la plupart des moteurs ont le même temps d'exécution pour les deux méthodes, dans certains systèmes de base de données, l'une s'exécute plus rapidement que l'autre.
L'UNION et DISTINCT les commandes sont parfois incluses dans les requêtes. Comme une jointure externe, il est bon d'utiliser ces expressions si elles sont nécessaires. Cependant, ils ajoutent un tri et une lecture supplémentaires de la base de données. Si vous n'en avez pas besoin, mieux vaut trouver une expression plus efficace.
13. Utilisez la fonction EXPLIQUER
Les bases de données MySQL modernes incluent un EXPLAIN fonction.
Ajouter le EXPLAIN expression au début d'une requête lira et évaluera la requête. S'il y a des expressions inefficaces ou des structures confuses, EXPLAIN peut vous aider à les trouver. Vous pouvez ensuite ajuster la formulation de votre requête pour éviter les analyses de table involontaires ou d'autres problèmes de performances.
14. Configuration du serveur MySQL
Cette configuration implique d'apporter des modifications à votre /etc/mysql/my.cnf dossier. Procédez avec prudence et apportez des modifications mineures à la fois.
query_cache_size – Spécifie la taille du cache des requêtes MySQL en attente d'exécution. La recommandation est de commencer avec de petites valeurs autour de 10 Mo, puis d'augmenter jusqu'à 100-200 Mo maximum. Avec trop de requêtes en cache, vous pouvez rencontrer une cascade de requêtes "En attente de verrouillage du cache". Si vos requêtes continuent de reculer, une meilleure procédure consiste à utiliser EXPLAIN pour évaluer chaque requête et trouver des moyens de les rendre plus efficaces.
max_connection – Fait référence au nombre de connexions autorisées dans la base de données. Si vous obtenez des erreurs citant "Trop de connexions, ” augmenter cette valeur peut aider.
innodb_buffer_pool_size – Ce paramètre alloue de la mémoire système en tant que cache de données pour votre base de données. Si vous avez de gros volumes de données, augmentez cette valeur. Prenez note de la RAM requise pour exécuter d'autres ressources système.
innodb_io_capacity – Cette variable définit le taux d'entrée/sortie de votre périphérique de stockage. Ceci est directement lié au type et à la vitesse de votre lecteur de stockage. Un disque dur à 5400 tr/min aura une capacité bien inférieure à un SSD haut de gamme ou à Intel Optane. Vous pouvez ajuster cette valeur pour mieux correspondre à votre matériel.