La pile ELK, également connue sous le nom de pile Elastic, se compose de quatre projets open source :Elasticsearch, Logstash, Kibana et Beats. Il vous aide à stocker tous vos journaux au même endroit et vous permet d'analyser et de visualiser les données ou les problèmes en corrélant les événements à un moment donné.
Ce guide vous aide à installer la pile ELK sur RHEL 8.
Composants
Elasticsearch – Un moteur de recherche open source en texte intégral. Il stocke les journaux entrants de Logstash et offre la possibilité de rechercher les journaux/données en temps réel
Logstash – Il effectue le traitement des données (collecte, enrichissement et transformation) des journaux entrants envoyés par beats (forwarder) et les envoie à Elasticsearch
Kibana – Fournit une visualisation des données ou des journaux d'Elasticsearch.
Beats :installé sur les machines clientes, il collecte et envoie les journaux à Logstash via le protocole Beats.
Environnement
Pour disposer d'une pile ELK complète, nous aurions besoin de deux machines pour tester la collecte des journaux.
| Nom d'hôte | SE | Adresse IP | Objectif |
|---|---|---|---|
| elk.itzgeek.local | RHEL 8 | 192.168.1.10 | Pile ELK |
| client.itzgeek.local | CentOS 7 | 192.168.1.20 | Machine cliente (Filebeat) |
Prérequis
Installer Java
Étant donné qu'Elasticsearch est basé sur Java, nous devons avoir OpenJDK ou Oracle JDK installé sur votre machine.
LIRE : Comment installer Java sur RHEL 8
Ici, j'utilise OpenJDK 1.8.
yum -y install java
Vérifiez la version Java.
java -version
Sortie :
openjdk version "1.8.0_212" OpenJDK Runtime Environment (build 1.8.0_212-b04) OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
Configurer le référentiel ELK
Importez la clé de signature Elastic.
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Configurez le référentiel Elasticsearch sur le serveur ELK et le client.
cat << EOF > /etc/yum.repos.d/elastic.repo [elasticsearch-7.x] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md EOF
Installer et configurer Elasticsearch
Elasticsearch est une source ouverte, le moteur de recherche en texte intégral offre une recherche et des analyses distribuées en temps réel avec l'interface Web RESTful. Elasticsearch stocke toutes les données envoyées par le Logstash et les affiche via l'interface Web (Kibana) à la demande des utilisateurs.
Installez Elasticsearch.
yum install -y elasticsearch-oss
Modifiez le fichier de configuration d'Elasticsearch en
vi /etc/elasticsearch/elasticsearch.yml
Définissez le nom du cluster, le nom du nœud, l'adresse IP d'écoute en fonction de votre environnement.
cluster.name: elkstack node.name: elk.itzgeek.local network.host: 192.168.1.10
Si vous définissez une adresse IP d'écoute, vous devez définir des hôtes de départ et des nœuds maîtres initiaux.
discovery.seed_hosts: ["elk.itzgeek.local"] cluster.initial_master_nodes: ["elk.itzgeek.local"]
Configurez Elasticsearch pour qu'il démarre au démarrage du système.
systemctl daemon-reload systemctl enable elasticsearch systemctl start elasticsearch
Utilisez CURL pour vérifier si Elasticsearch répond aux requêtes.
curl -X GET http://192.168.1.10:9200
Sortie :
{
"name" : "elk.itzgeek.local",
"cluster_name" : "elkstack",
"cluster_uuid" : "yws_6oYKS965bZ7GTh0e6g",
"version" : {
"number" : "7.2.0",
"build_flavor" : "oss",
"build_type" : "rpm",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
} Vérifiez la santé du cluster en exécutant la commande ci-dessous.
curl -XGET '192.168.1.10:9200/_cluster/health?pretty'
Résultat :l'état du cluster doit être vert.
{
"cluster_name" : "elkstack",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Installer et configurer Logstash
Logstash est un outil open source de gestion des logs. Il collecte les journaux, les analyse et les stocke sur Elasticsearch. Plus de 160 plugins sont disponibles pour Logstash, qui offre la possibilité de traiter les différents types d'événements sans travail supplémentaire.
Installez le package Logstash.
yum -y install logstash-oss
La configuration de Logstash se trouve dans /etc/logstash/conf.d/ .
Le fichier de configuration Logstash se compose de trois sections, à savoir l'entrée, le filtre et la sortie. Les trois sections peuvent être trouvées dans un seul fichier ou dans des fichiers séparés se terminant par .conf.
Je vous recommande d'utiliser un seul fichier pour placer les sections d'entrée, de filtre et de sortie.
vi /etc/logstash/conf.d/beats.conf
Dans la section d'entrée, nous allons configurer Logstash pour qu'il écoute sur le port 5044 les journaux entrants des beats (transmetteur) installés sur les machines clientes.
input {
beats {
port => 5044
}
} Dans la section des filtres, nous utiliserons Grok pour analyser les journaux avant de les envoyer à Elasticsearch.
Le filtre grok suivant recherchera le syslog journaux étiquetés et essaie de les analyser pour créer un index structuré. Ce filtre est très utile uniquement pour surveiller les messages syslog (/var/log/messages).
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
} Pour plus de modèles de filtres, visitez la page grokdebugger.
Dans la section de sortie, nous définirons l'emplacement où les journaux seront stockés, évidemment, un nœud Elasticsearch.
output {
elasticsearch {
hosts => ["192.168.1.10:9200"]
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
}
} Maintenant, démarrez et activez le service Logstash.
systemctl start logstash systemctl enable logstash
Attendez une minute pour permettre à Logstash de démarrer, puis exécutez la commande ci-dessous pour vérifier s'il écoute sur le port 5044.
netstat -antup | grep -i 5044
Sortie :
tcp6 0 0 :::5044 :::* LISTEN 31014/java
Vous pouvez dépanner Logstash à l'aide des journaux.
cat /var/log/logstash/logstash-plain.log
Installer et configurer Kibana
Kibana fournit une visualisation des journaux stockés sur Elasticsearch. Installez le Kibana à l'aide de la commande suivante.
yum -y install kibana-oss
Modifiez le fichier kibana.yml.
vi /etc/kibana/kibana.yml
Par défaut, Kibana écoute sur localhost, ce qui signifie que vous ne pouvez pas accéder à Kibana à partir de machines externes. Pour l'autoriser, modifiez la ligne ci-dessous et mentionnez l'adresse IP de votre serveur ELK.
server.host: "0.0.0.0"
Décommentez la ligne suivante et mettez-la à jour avec l'URL de l'instance Elasticsearch.
elasticsearch.hosts: ["http://192.168.1.10:9200"]
Démarrez et activez kibana au démarrage du système.
systemctl start kibana systemctl enable kibana
Vérifiez si Kibana écoute sur le port 5601.
netstat -antup | grep -i 5601
Sortie :
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 3631/node
Pare-feu
Configurez un pare-feu sur le serveur ELK pour recevoir les journaux des machines clientes.
5044 – Pour que Logstash reçoive les logs
5061 – Pour accéder au Kibana depuis des machines externes.
firewall-cmd --permanent --add-port=5044/tcp firewall-cmd --permanent --add-port=5601/tcp firewall-cmd --reload
Ensuite, nous allons configurer beats pour envoyer les journaux au serveur Logstash.
Installer et configurer Filebeat
Quatre clients Beats sont disponibles
- Packetbeat – Analyser les données des paquets réseau.
- Filebeat – Aperçu en temps réel des données de journal.
- Meilleur rythme – Obtenez des informations à partir des données d'infrastructure.
- Metricbeat – Envoi des métriques à Elasticsearch.
Configurez le référentiel Elastic sur la machine cliente pour obtenir le package Filebeat.
Installez Filebeat à l'aide de la commande suivante.
yum -y install filebeat
Le fichier de configuration Filebeat est au format YAML, ce qui signifie que l'indentation est très importante. Assurez-vous d'utiliser le même nombre d'espaces que dans le guide.
Modifier le fichier de configuration filebeat.
vi /etc/filebeat/filebeat.yml
Commentez la section output.elasticsearch : car nous n'allons pas stocker les journaux directement dans Elasticsearch.
#-------------------------- Elasticsearch output ------------------------------ #output.elasticsearch: # Array of hosts to connect to. #hosts: ["localhost:9200"] # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "changeme"
Maintenant, trouvez la ligne output.logstash et modifiez les entrées comme ci-dessous. Cette section définit filebeat pour envoyer les journaux au serveur Logstash 192.168.1.10 sur le port 5044 .
. . . #----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["192.168.1.10:5044"] . . .
En plus de /etc/filebeat/filebeat.yml , vous verriez la section des prospecteurs. Ici, vous devez spécifier quels journaux doivent être envoyés à Logstash.
Chaque prospecteur commence par un – caractère.
Ici, nous allons configurer filebeat pour envoyer les journaux système /var/log/messages au serveur Logstash. Pour cela, modifiez le prospecteur existant sous paths section comme indiqué ci-dessous.
. . .
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/messages
#- c:\programdata\elasticsearch\logs\*
. . . Redémarrez le service.
systemctl restart filebeat systemctl enable filebeat
Accéder à Kibana
Accédez au Kibana en utilisant l'URL suivante.
http://votre-adresse-ip:5601/Vous obtiendrez la page d'accueil de Kibana. Cliquez sur Explorer par moi-même .

Lors de votre premier accès, vous devez mapper l'index filebeat. Accédez à Gestion>> Modèles d'indexation>> Créer un modèle d'indexation .
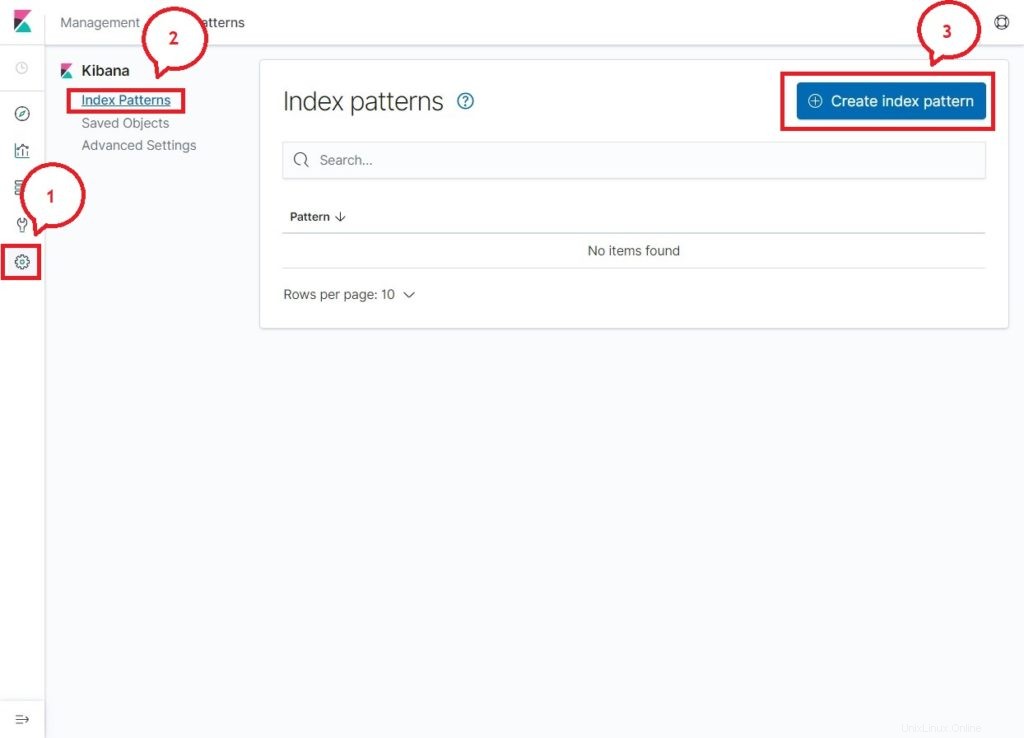
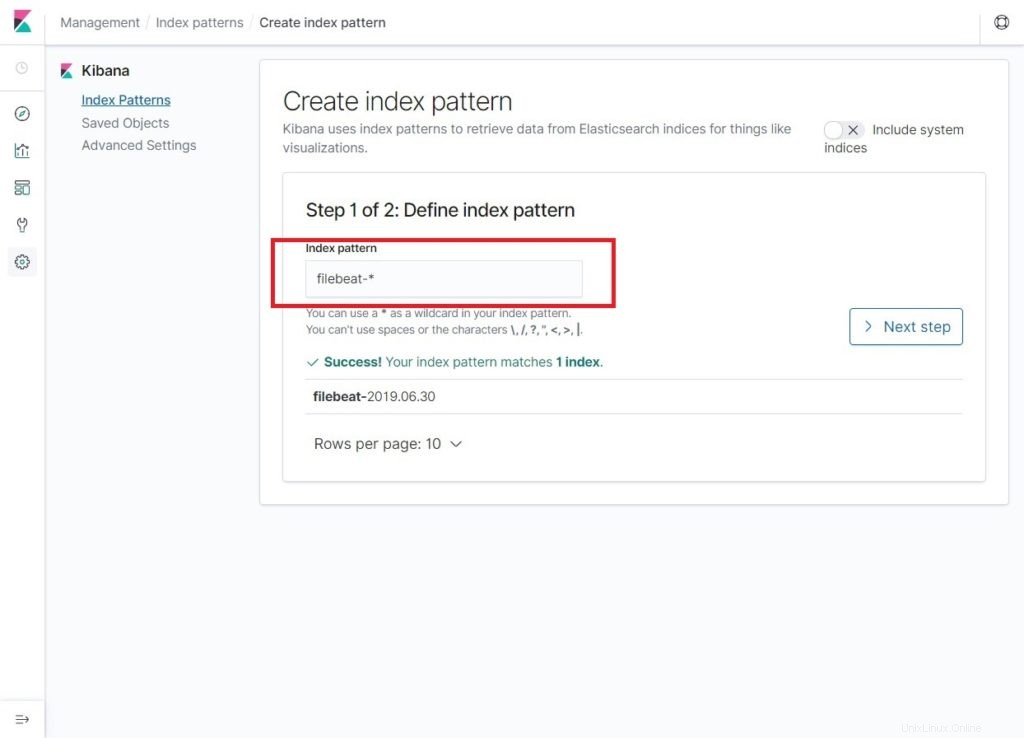
Tapez ce qui suit dans le modèle d'index boîte.
filebeat-*Vous devriez voir au moins un index filebeat comme ci-dessous. Cliquez sur Étape suivante .
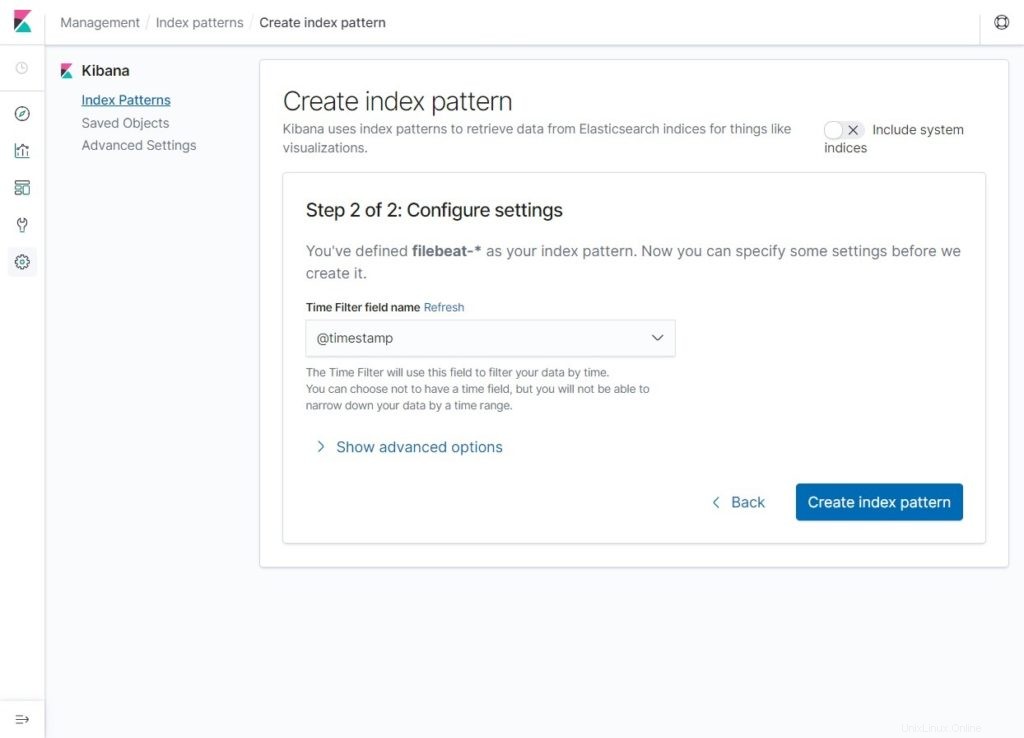
Sélectionnez @timestamp puis cliquez sur Créer un modèle d'index .
@timestamp
Vérifiez vos modèles d'index et ses mappages.
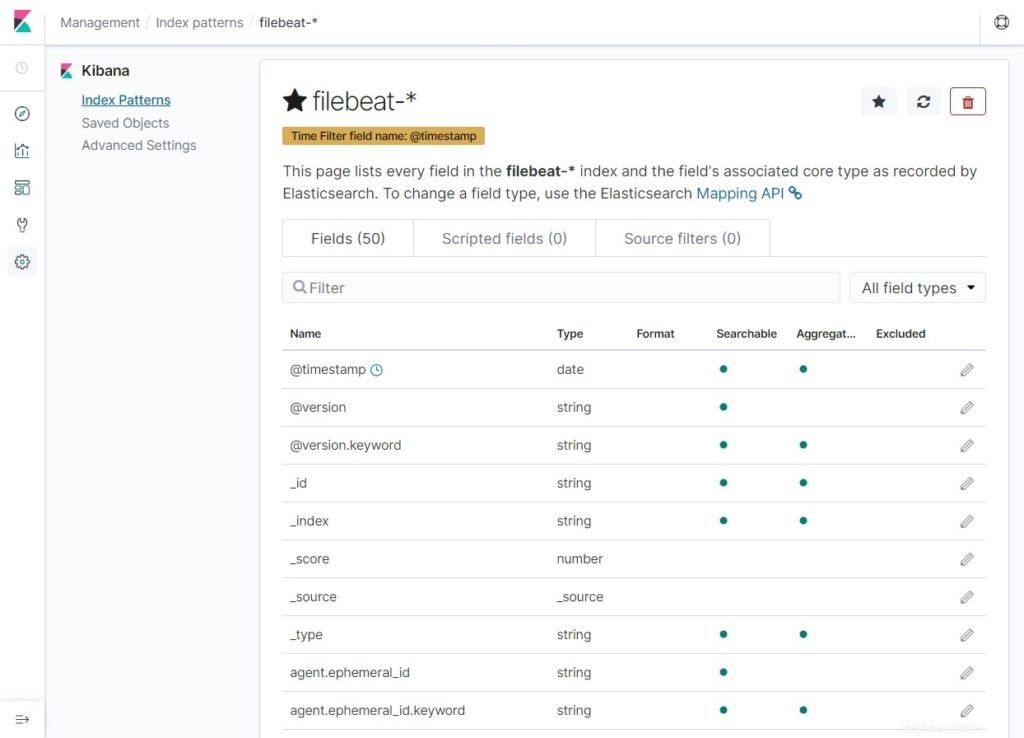
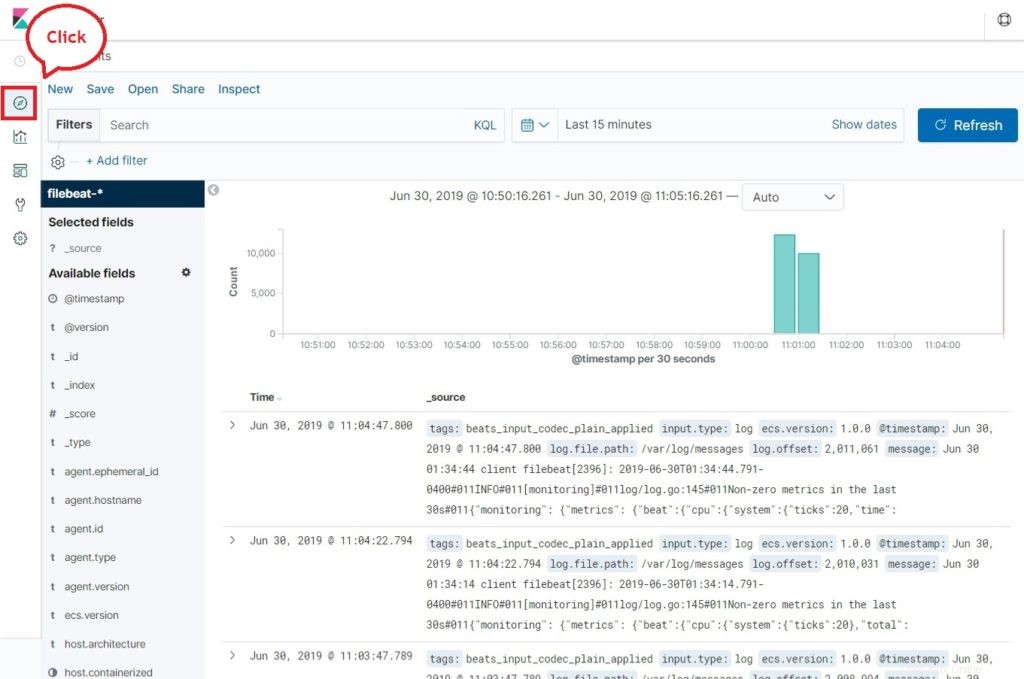
Maintenant, cliquez sur Découvrir pour afficher les journaux et effectuer des requêtes de recherche.
Conclusion
C'est tout. Vous avez réussi à installer ELK Stack sur RHEL 8. Veuillez partager vos commentaires dans la section des commentaires.